看不见的空白层
系列:破而后立的 TDD 流程迭代(第三篇) 第一篇:失之东隅,收之桑榆的实验 · 第二篇:以尺度尺,用方法改进方法 TL;DR: 阶段六已经在集成层做诊断——逐个 bug 追问根因。它不做的事是跨缺陷的模式扫描、组件缝隙检查、执行顺序分析。这些事归阶段七。小系统里阶段七多拦几个 bug;系统大了,同样是这三件事,产出变成建测试基础设施、硬化 CI 规则、驱动架构演进。阶段七不做架构决策,但它提供架构决策最稀缺的输入——基于证据的问题定位。 ...
系列:破而后立的 TDD 流程迭代(第三篇) 第一篇:失之东隅,收之桑榆的实验 · 第二篇:以尺度尺,用方法改进方法 TL;DR: 阶段六已经在集成层做诊断——逐个 bug 追问根因。它不做的事是跨缺陷的模式扫描、组件缝隙检查、执行顺序分析。这些事归阶段七。小系统里阶段七多拦几个 bug;系统大了,同样是这三件事,产出变成建测试基础设施、硬化 CI 规则、驱动架构演进。阶段七不做架构决策,但它提供架构决策最稀缺的输入——基于证据的问题定位。 ...

系列:破而后立的 TDD 流程迭代(第二篇) 上一篇:失之东隅,收之桑榆的实验 TL;DR: TDD Pipeline 自己教的是"给原则不给步骤",但自己却长成了步骤驱动的工具。把阶段一到阶段五的操作步骤删掉,只保留原则、风险提示和反面例子。模型自己推导出了被删掉的步骤,输出质量不降。原因:阶段一到阶段五是创作阶段,需要发散空间,去掉固定轨道反而更好。同样的策略用在阶段六上失败了——下一篇讲为什么。 ...

系列:破而后立的 TDD 流程迭代(第一篇) TL;DR: 把 TDD Pipeline 的阶段六(预发布测试)从"步骤驱动"精炼为"原则驱动",预设目标没达到——精炼版在单个 bug 的追问深度、证据链完整度上都比原版差。但对比两组输出发现了维度差异:精炼版在组件缝隙检查、跨 bug 模式扫描上比原版强。这些差异指向一个判断——阶段六不需要被精炼,而是缺了一个阶段六没有定义的任务,后来被定义为阶段七。 ...

TL;DR: 展示 Why Articulation 模板升级前后的对比,以及三条可迁移建议:给原则不给示例、关键步骤用强制语气、相信模型的自我组织能力。实验局限也已说明。 前两篇回顾 第一篇从 Anthropic 的对齐研究出发:教模型"为什么"比只教它"正确答案",误对齐率从 22% 降到 3%(约 7 倍),而且用 1/28 的数据量就能达到同等效果[1]。我把这个发现移植到 prompt 设计里,造出了 Why Articulation 模板——要求 AI 动手前先说清目的、风险和方案。 ...

TL;DR: 四变量 A/B 实验测试 Why Articulation 的结构、语气、位置和示例。正面示例反而有害——模型倾向模仿而非独立思考。开放式 prompt 方向性提升质量,同时节省 33% token。 ...

TL;DR: Anthropic 的对齐研究表明,教模型"为什么"比教"做什么"更有效——误对齐率从 22% 降到 3%。本文拆解四组实验,提炼出三个可迁移的 prompt 设计教训。 ...

TL;DR: Aristotle v1.1 发布前发现 18 个 bug,单元测试只拦住 4 个(22%)。剩下 14 个都在集成层——组件接线、配置传递、进程启动的交叉点。对它们做 root cause analysis 后归纳出六种模式:路径/环境不一致(5 个)、注册遗漏(3 个)、启动阻塞(2 个)、静默失败(2 个)、测试-生产路径差异(2 个)、集成拼接错误(4 个)。根因不是问题变难了,是 AI 绕过了手写代码时靠经验建立的防线——实现和审查的节奏脱钩、代码外观误导了质量判断、集成环节从显式动作变成了隐式假设。文末附八维度集成检查清单和 16 种 bug 类型的路线图。 ...

TL;DR: 追问协议用七个条件给 AI 的 5-Why 过程设规矩:T1-T3 是地板(不满足不许停),HC1-HC4 是护栏(防止过程失控)。其中 T2 的预防性反事实检验是最关键的设计——预防性 framing 迫使追问走深,同时反事实提问专门构造否定情境来对冲确认偏差。 ...
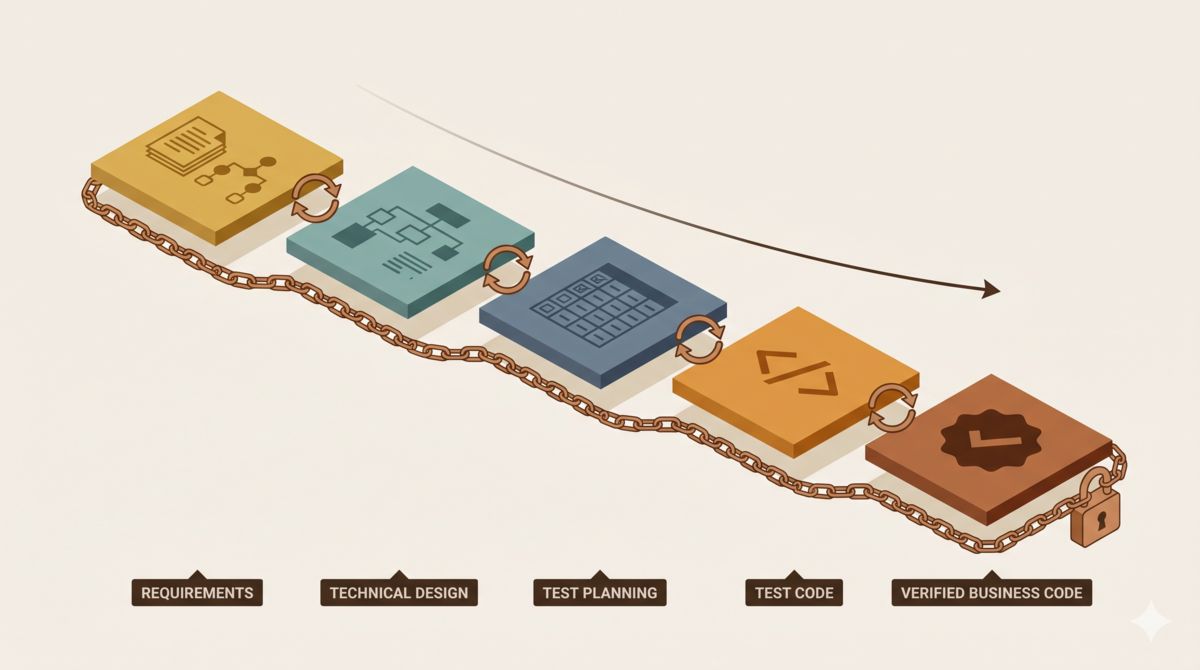
这是"用 TDD 驯服 AI 编码代理"系列的第 6 篇。前四篇分别讲了需求层、设计层、测试层和审核层,第 5 篇把审核层升级为程序正义。本篇把它们串成一条可落地的完整管线。 ...
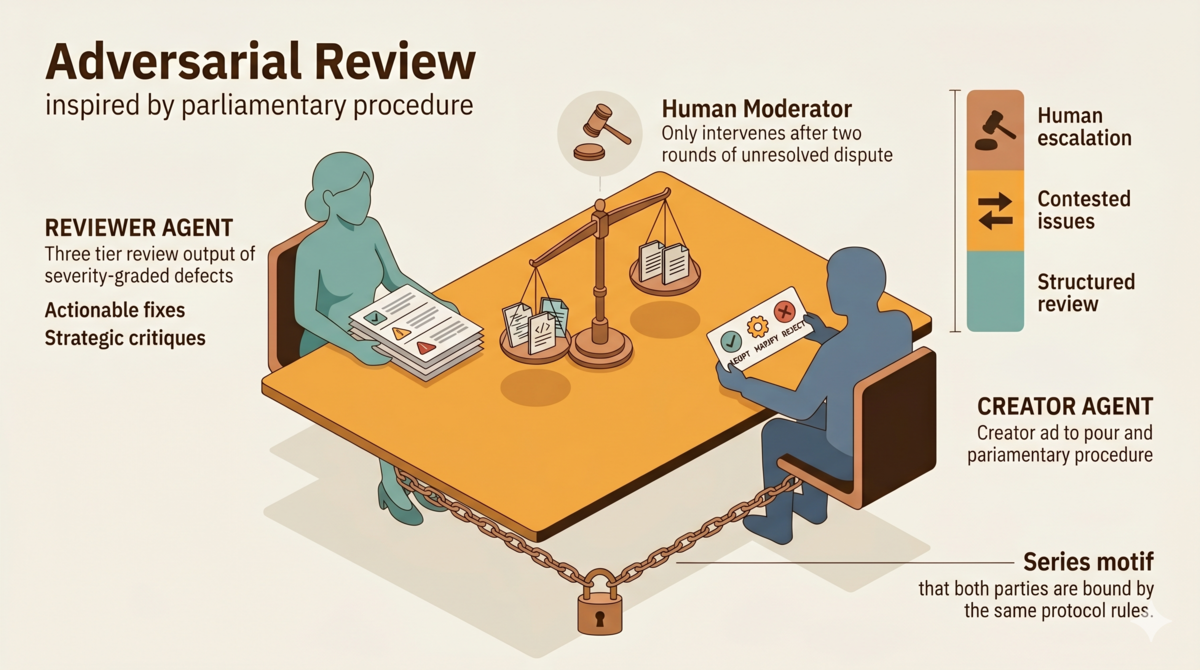
我之前做的 Ralph Loop 审核机制,有个隐藏问题。 v0.2 的流程只有「发现问题→修复→确认收敛」。第 4 篇提过,创造者如果认为审查者误判,可以在下一轮提供证据,由审查者重新评估——但那只是一句规则,不是正式协议。没人检验审核本身的质量。审查者可能标错问题严重等级。主代理可能盲目接受不合理建议。 ...