
系列:用经典理论指导 Agent 实践(第三篇) 第一篇:双轮审查:召回和精确为什么不能兼得 · 第二篇:策略基因:借遗传算法思路精简审查 prompt
TL;DR: 两组对照实验。代码审查维度从 8 个加到 11 个,已知问题的发现率从 1/6 升到 6/6。设计审查引入公理化设计维度,发现率同样从 1/6 升到 6/6。但加了数学公式的版本证明维度不是越多越好——计算过程挤掉了审查注意力,发现数掉 35%。做对照实验,用已知问题做参照,才知道哪个维度有效。
上一篇解决了"prompt 里写什么"——删掉可推导的冗余内容,只保留策略基因,审查质量升了 29%,但还有一个问题没回答:审查的维度够不够?
策略基因再精,维度不够,还是看不到。
先看结果
两组对照实验。同一个思路:收集已确认但被现有维度漏掉的已知问题,加维度,看找回了几成。
实验一:代码审查维度增强
代码审查原来有 8 个维度。对照实验发现,6 个已知问题只找到了 1 个。
加了 3 个维度(安全深度、测试缝隙分析、资源安全),变成 11 个。
结果:6/6 全部找到。
实验二:设计审查维度增强
设计审查原来有 11 个维度。6 个已知问题只找到了 1 个。
引入公理化设计(Axiomatic Design),加了 3 个维度(独立性公理、信息公理、需求纯度),变成 14 个。
结果:6/6 全部找到。
两个实验的结论看起来一样:加维度,效果好,但故事没结束。后面还有一个实验,结论完全不同,下面会详细说。
对照实验方法论
两组实验用了同一个方法论——对照实验。我为此写了一个双盲实验的技能,让 AI agent 按照统一的流程跑。
控制变量
每次只改变审查维度。同一个代码库,同一批已知问题,同一个模型。其他条件不变。
维度数量不同,效果差异才能归因到维度变化上。
已知问题做参照
参照是之前审查中已确认的真实问题,但被现有维度漏掉的。
这些问题不是"可能有问题",是"确实有问题"。它们经过人工确认,有明确的错误描述和修复方案。
用这些已验证的问题做参照,实验就有了客观的衡量标准。
衡量指标
已知问题发现率 = 实验组报出了多少个之前被漏掉的问题。
为什么不直接看"报了多少问题"(发现总数)?
因为发现总数可以通过降低标准来注水。一个维度报 100 个发现,可能 90 个是误报。降低标准 = 多报 = 数字好看但质量差。
已知问题发现率看的是另一件事:真正有价值的问题被找到了多少。 这些问题之前被漏掉过,说明它们不容易被发现。新维度能不能找到这些"难发现的问题",才是衡量维度有效性的标准。
为什么用已知问题做参照
一般做审查实验会用人工标注做参照。我没用,原因很简单——没有精力标。
但我发现这反而更好。已知问题不是"标注出来的问题",是"之前审查确认过、实际修复过的问题"。它们的存在已经被验证了,不需要再找人确认"这个到底算不算问题"。
公理化设计
实验二引入了公理化设计,这个理论框架我之前也没有听说过,这里做一个专门的介绍。
公理化设计是 MIT 的 Nam P. Suh 提出的设计理论[1]。核心是两条公理:
- 独立性公理:功能需求之间的耦合越少,设计越好
- 信息公理:在满足独立性公理的方案中,最简单的最好
两条公理有顺序。先满足独立性,再选最简方案。
独立性公理怎么用在审查里
独立性公理说:好的设计里,每个功能需求(Functional Requirement,简称 FR)由独立的设计参数(Design Parameter,简称 DP)实现。如果两个功能需求共享一个设计参数,改一个功能会影响另一个。这就是耦合。
把这个检查放进审查维度:画功能需求和设计参数的对应关系,看是不是一对一。如果出现多对多的关系,说明设计有耦合。
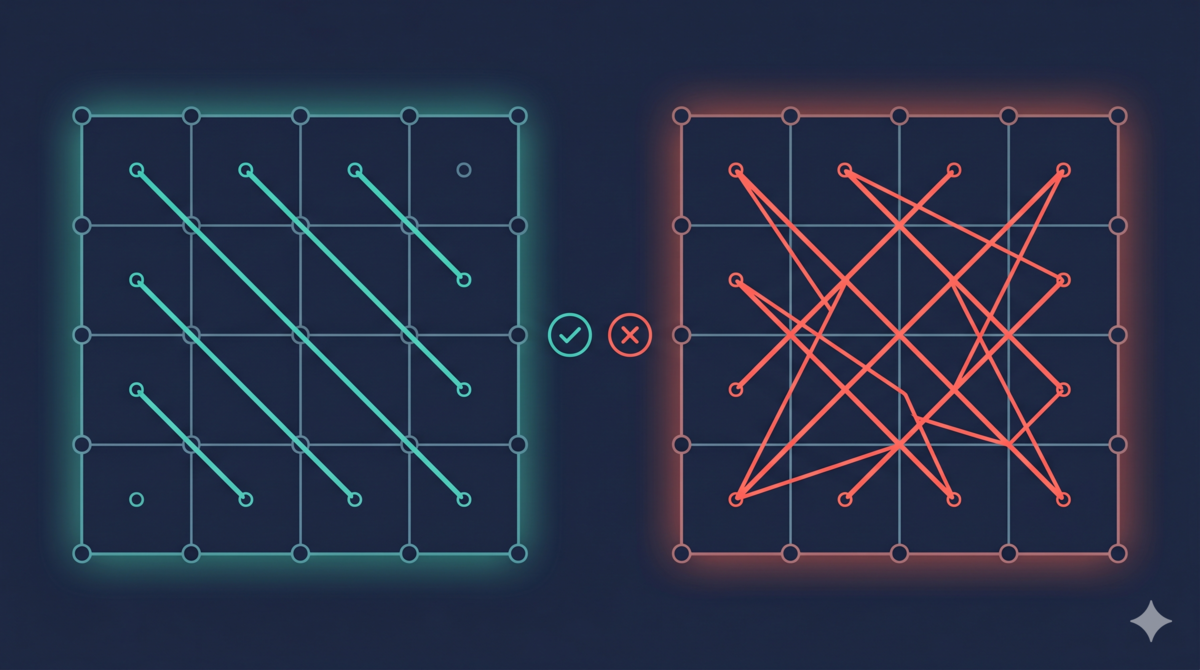
纯正确性审查不检查这个,“功能对不对"和"功能之间有没有耦合"是两个不同的问题,正确性维度只检查前者。
信息公理的两个版本
信息公理说:如果多个方案都满足独立性,选最简单的。I=-log₂(p),p 是成功概率。成功概率越高 = 方案越简单。
我做了两个版本:精简版就一句"选择最简方案"。公式版要求模型做完整的 I=-log₂(p) 计算。哪个更好?这里继续留个悬念,后面一并说。
怎么想到的
起点:审查没看到的问题
前两篇解决了两个问题。第一篇,审查循环怎么跑——双轮审查。第二篇,prompt 写什么——策略基因。
双轮审查和策略基因优化后,审查循环收敛变快了。轮次少了,每轮的有效发现率高了。
但还有一个现象:收敛后去做回归测试,总会发现之前审查没报过的问题。不是审查报了没修,是审查根本没看到——维度里没有对应的检查项。
一个典型的已知问题
SQL 查询里的 ORDER BY created_at 没有 tiebreaker——没有加决胜列。当多条记录的 created_at 相同时,数据库每次返回的顺序可能不一样。
这不是逻辑错误——查询结果在大多数情况下是对的,不是安全问题,不是性能问题,但现有的 8 个维度里没有一个覆盖它。
“正确性"维度不查这种事,“安全性"维度也不查,“性能"维度也不查,需要一个新维度来检查这类问题,于是加了"测试缝隙分析"维度。
对照实验
用前面说的方法跑了一轮:6 个已知问题做参照,只改变审查维度。
第一步加 3 个维度(安全深度、测试缝隙分析、资源安全),跑出来 1/6。不够。
仔细看没找到的 5 个问题,发现维度方向其实对了——“测试缝隙分析"确实覆盖了排序确定性问题。但模型不知道该看什么。
于是改了措辞。不再是"检查测试缝隙”,而是告诉模型具体看什么:排序字段相同时有没有加决胜列?查询条件有没有跳过复合主键的前面几列、导致索引失效?
再跑,6/6。
这个迭代过程本身说明一件事:维度设计不是"想到了就有效”。想到了方向,还需要验证。验证发现方向对了但不够具体,再加线索。
公理化设计的灵感
前面的维度迭代解决的是"方向对了但不够具体"的问题。修完措辞后,tiebreaker 和索引问题都能找到了。
到此为止,我能想到的维度都加了。但耦合这类问题,我之前根本没有关注过。不是"知道有问题但不知道怎么查”,是压根没意识到这是一个维度。
正巧推友 @goldengrape 和我聊记忆系统设计时提到,公理设计里有个设计矩阵,迭代到上三角就能保证设计质量。我听着挺有意思,就去了解了这套理论的核心思路(前面"公理化设计"一节已经介绍过了),然后抱着试试看的心理,把 FR-DP 耦合检查加进了审查维度。
跑了一轮实验。结果出乎意料——它找到了之前所有维度都没发现的问题。耦合不是我预设的目标,是实验结果告诉我的。
当然,从理论到可用的审查维度不是直接搬的。Suh 的方法里还有一套量化比选的数学公式,我也试了。结果……
公式版被否决的教训

把数学公式放进维度时,我是有信心的。数学上严谨,语义上精确,模型应该能算出"哪个方案更简单”。
结果不是预想的那样。
33 个发现,比精简版少了 35%。召回还掉了半个。
回头看,原因很清楚:I=-log₂(p) 要求模型做数学推理。评估成功概率、取对数、比较。这些计算消耗的注意力,远超一句"选择最简方案"。
这就是第二篇的策略基因原则在另一个层面的体现。不是只有 prompt 的文字有冗余内容,维度本身的设计也有冗余内容。独立性公理的检查框架是策略基因——它指导模型做有价值的检查。数学公式是冗余内容——它让模型做了和审查无关的事。
系列:一条共同的规律
到这里三篇都写完了,做个简单回顾。

第一篇,双轮审查。问题:一个审查 agent 同时优化"找全"和"找准",两头都不好。解法:拆开。理论依据:信息检索里 Recall 和 Precision 的矛盾关系。
第二篇,策略基因。问题:prompt 太长,模型注意力被稀释。解法:删掉可推导的冗余内容,只保留策略基因。理论依据:Holland 的遗传算法 building blocks 概念和 Wang 的 strategy genes 研究结果。
第三篇,维度实验。问题:审查维度不够,系统性地漏掉某一类问题。解法:对照实验验证维度有效性,用已知问题做参照。理论依据:对照实验方法论和公理化设计。
三篇用了三个不同的经典理论,IR、遗传算法、公理化设计,看起来没什么关系。
但其实只在讲一个规律:把经典理论搬进 AI Agent 设计时,最重要的是分辨什么是策略基因、什么是冗余内容。
- 双轮审查:Recall 和 Precision 的矛盾是策略基因,“模型应该自己权衡"是冗余内容。
- 策略基因:约束和反面例子是策略基因,步骤描述和正面例子是冗余内容。
- 维度实验:独立性公理的检查框架是策略基因,数学公式是冗余内容。
每一篇的"被否决方案"都在说同一件事:理论里看起来重要的东西,放进 Agent 不一定有用,关键是看它对输出有没有实际影响。没有影响的,再优雅也是冗余内容。
这个判断只能通过实验来做,删掉它,看输出变不变,加进去,看召回升不升,没有捷径。
参考
- Suh, N. P. The Principles of Design, Oxford University Press, 1990. https://global.oup.com/academic/product/the-principles-of-design-9780199259796