
系列:AI Agent 实验方法论(第二篇) 上一篇:如何用双盲实验验证 skill 改动的有效性
TL;DR: 双盲实验跑完第一轮,B 赢了 3/4 但没过"幅度筛选",结论是"证据不足"。排查发现 S1-A 的输出被终端颜色代码污染,scorer 在 ANSI 乱码上认认真真打了 8 个维度的分。修复执行上下文后重跑,B 变成 4/4 全胜。翻车的原因不是实验设计,是子 agent 的上下文构造没约束异常行为。
第一轮:协议完美,结论不可用
上一篇讲了双盲实验的设计:两个版本、四个场景、盲映射、独立 scorer。协议本身挑不出毛病。
第一轮结果出来了:
| 场景 | 目标代码 | Variant A | Variant B | 胜者 | 差距 |
|---|---|---|---|---|---|
| S1 | Python user service | 0.625 | 2.875 | B | +2.250 |
| S2 | React payment form | 2.625 | 2.750 | B | +0.125 |
| S3 | Java order processor | 2.625 | 2.625 | 平 | 0.000 |
| S4 | Node.js cache | 2.250 | 2.875 | B | +0.625 |
B 赢了 3/4,S3 平局。但"幅度筛选"没过——A 只有 B 的 73%,低于 90% 门槛。
8 个 evaluator run、一个 scorer、一堆 token——结论是"证据不足,不能采纳"。得重跑。
S1-A 那个 0.625 是个明显的异常值。满分 3 分,8 个维度里有 5 个得 0 或 1。但数据就是数据,你不能因为一个数字看着不对就扔掉它——除非你找到原因。
排查:不是实验设计的错
第一反应是怀疑实验设计有问题:是不是某个场景太难?是不是 rubric 设计偏向 B?
逐维度排查,S1-A 的 8 个维度里有 5 个得 0 或 1,和其他场景差距极大。最终定位到了:S1-A 的输出文件被 ANSI escape sequences 污染——终端颜色代码混进了文本,文件几乎不可读。
这不是实验设计的错。双盲协议、secret mapping、8 维度 rubric——每一步都正确。问题出在执行链路上:evaluator 的输出没有做完整性校验,scorer 的输入没有做可读性检查。
evaluator 产出了一个被污染的结果,scorer 接到乱码也没报错——它对着 ANSI 转义序列,认认真真完成了 8 个维度的评分。Prompt 里没写"如果输入不可读,必须拒绝打分",它就默认自己能处理。
这和上一篇里的"幽灵投递"是同一个模式:LLM 不会主动告诉你它出错了。你不在 prompt 里写明拒绝条件,它就会在垃圾输入上"正常"完成工作。

逐维度看一下 S1-A 的评分有多离谱:
| 维度 | S1-A 得分 | 原因 |
|---|---|---|
| Prompt Contamination | 1 | ANSI 污染被判定为 prompt 问题 |
| Dual-Pass Adherence | 1 | 输出不可读,无法判断流程 |
| Severity Accuracy | 0 | 无法识别任何内容 |
| Defect Discovery | 1 | 勉强发现一些模式 |
| False Positive Control | 1 | 无法区分真假 |
| Suggestion Quality | 1 | 建议基于乱码 |
| Critical Opinion | 1 | 意见基于不可读内容 |
| Format Compliance | 0 | 完全不可读 |
scorer 不是在故意打低分——它在尽力完成一个不可能的任务。5 个维度得 0 或 1,不是因为 Variant A 的审查 skill 差,是因为它在评分的对象根本不是正常的审查输出。
第二个错误:一个 scorer 做了不该做的事
S1-A 的 ANSI 污染是第一个执行问题。v1 里还有第二个——汇总逻辑错误。上一篇从结论角度讲了 0.03 差距是怎么来的,这里从执行角度看同一个问题。
v1 的 scorer 是一个 subagent 对所有场景的结果评分。给它四个场景的输入,它看到了 X 和 Y 的标签,不知道背后的映射关系。于是它做了一个"合理"的操作:把四个 X 加起来求平均、四个 Y 加起来求平均。
问题是:四个 X 里混了两个 A 的分和两个 B 的分。四个 Y 也一样。A 和 B 的分数被混在一起平均了,差异被抹平了。
X 均分 2.44,Y 均分 2.41,差 0.03。看起来"没区别"。
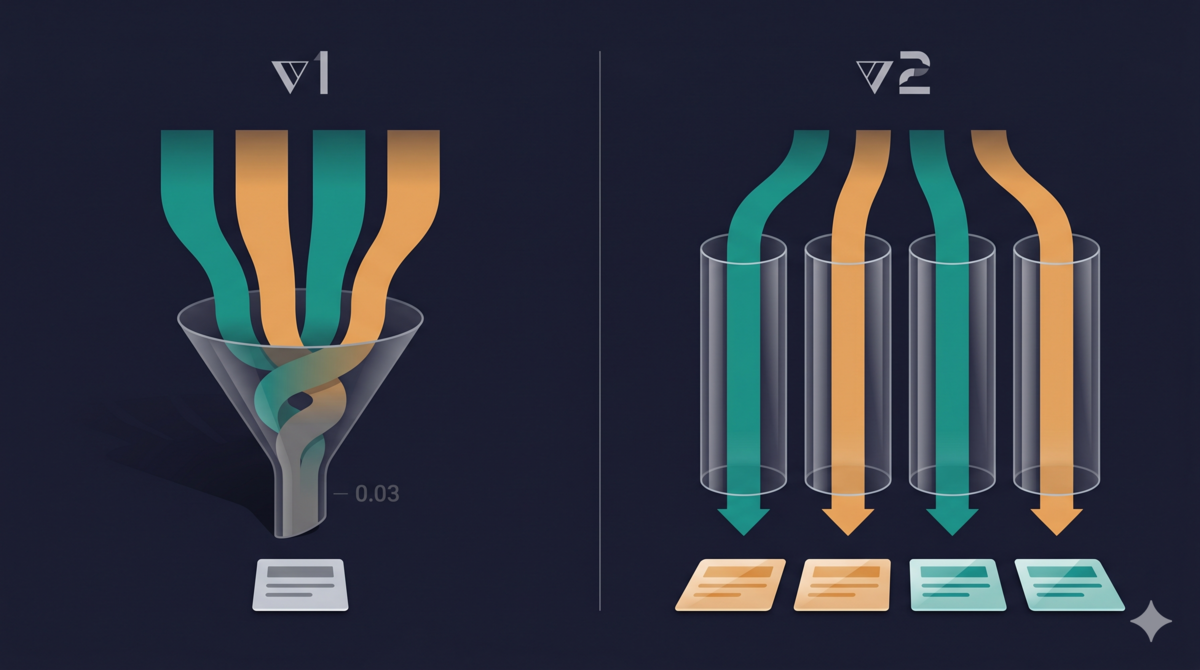
这不是 scorer 犯了什么罕见的错误。给它所有数据,它会自然地做汇总——这是 LLM 的默认行为。错误在于我的执行架构设计:应该每个场景用独立的 scorer subagent,只给它一个场景的评分输入,它就没有机会做跨场景汇总。
同一个 subagent,给它 1 个场景的数据 vs 给它 4 个场景的数据,产出完全不同的结论。这不是 prompt 措辞的问题,是上下文构造的问题。
修上下文,重跑
修复方式不是改实验设计,是重新构造每个执行环节的上下文:
- 修复 evaluator 的输出捕获(终端颜色代码不再混入)
- 每个场景起一个独立的 scorer subagent,只给它该场景的评分输入
- 汇总步骤由知道 secret mapping 的人来做,不让 scorer 接触跨场景数据
两处修复,两处都有数据变化。S1-A 从 0.625 恢复到 2.500,汇总逻辑从"一个 scorer 评所有场景"改成"每个场景独立 scorer"。v2 结果:
| 场景 | Variant A | Variant B | 胜者 | 差距 |
|---|---|---|---|---|
| S1 | 2.500 | 2.750 | B | +0.250 |
| S2 | 2.375 | 2.500 | B | +0.125 |
| S3 | 2.250 | 2.375 | B | +0.125 |
| S4 | 2.125 | 2.500 | B | +0.375 |
| 指标 | v1(无执行约束) | v2(重构造上下文) |
|---|---|---|
| B 胜场 | 3/4(S3 平局) | 4/4 |
| 幅度筛选 | 0.73 ❌ | 0.91 ✅ |
| A 平均 | 2.031 | 2.313 |
| B 平均 | 2.781 | 2.531 |
| 结论 | 证据不足,不能采纳 | 采纳 B |
值得注意的一点:v2 里 B 的平均分从 2.781 降到了 2.531。不是 B 变弱了,是 v1 里 S1-A 的 0.625 把 A 的平均分严重拉低,让 B 看起来赢了很多。修复后差距变小了,但数据反而更可靠。
重构了两个节点的执行上下文,结论从"证据不足"变成了"采纳 B"。
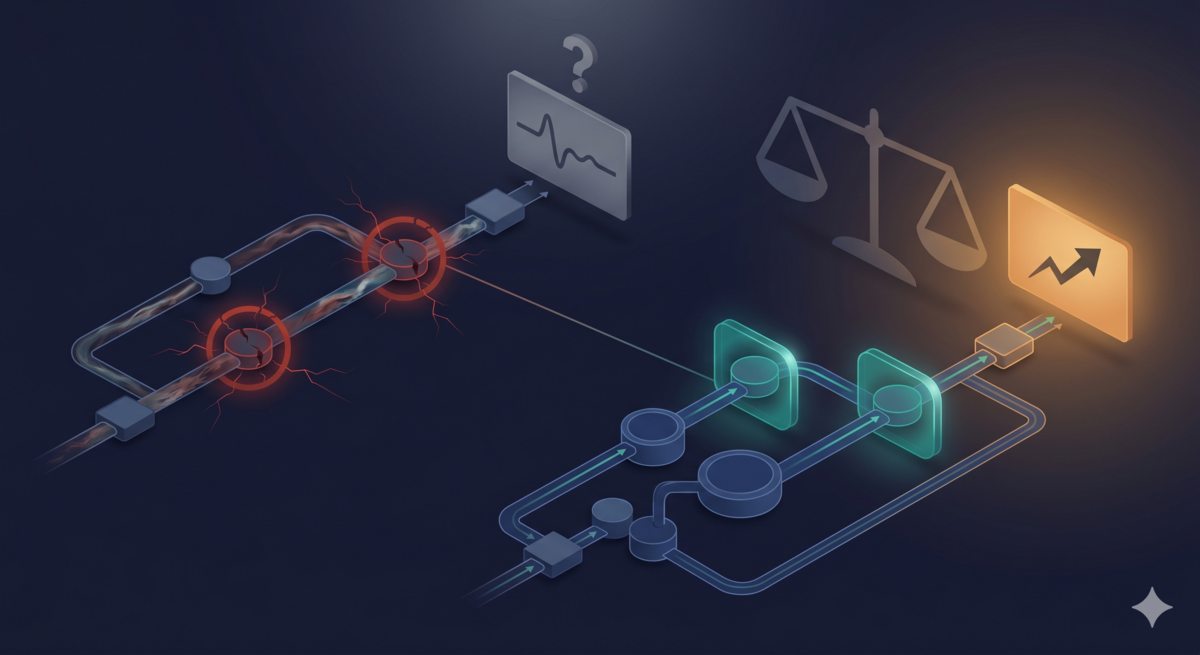
设计对了,为什么还是翻车
这个实验的设计挑不出毛病——双盲协议、secret mapping、8 维度 rubric。但 v1 还是翻车了,因为设计对了只解决了一半问题:
- Evaluator 没被要求校验输出完整性,所以它没报告 ANSI 污染
- Scorer 被给了 4 个场景的数据,所以它自然地做了跨场景汇总——差异被抹平
v2 的修复没动实验设计,只做了两件事:evaluator 加了输出完整性校验,scorer 从"一个 agent 评所有场景"改成"每个场景一个独立 agent"。
做 tdd-pipeline 的过程里,类似的教训反复出现。设计 workflow 是一件事——做什么、按什么顺序做。构造上下文是另一件事——每个 subagent 看到什么、不看到什么、什么情况下该拒绝执行。
这次实验的迭代,再次提醒我:驾驭工程的实施,既要有合理的 workflow 设计,对完成各节点任务的 subagent,也要审慎设计它们的上下文构造,这对目标实现至关重要。