
系列:用经典理论指导 Agent 实践(第一篇)
TL;DR: 设计审查的 agent 既要找得全又要找得准,一个 agent 难以两全。借鉴信息检索 15 年前的级联检索思路,拆成两个 agent——一个只管找全(Recall Pass),一个只管找准(Precision Pass)。设计方案的缺陷更早暴露,开发阶段返工的风险降低了。
这个系列讲一件事:经典的理论框架,怎么直接指导 AI Agent 的工程设计。第一篇从信息检索(Information Retrieval,下文简称 IR)领域 15 年前提出的级联检索方法说起——它的底层是更老的 Recall/Precision 矛盾,1966 年 Cranfield 实验就证明了这两个目标互相打架。把这个老问题的新解法搬到设计审查上,效果惊人。
先看结果
TDD Pipeline 的前三个阶段是设计阶段——写需求文档、出设计方案、定测试计划。这些文档写得好不好,直接决定后面的开发顺不顺利。所以设计文档写完后,我让另一个 AI agent 来审,看有没有遗漏和矛盾。
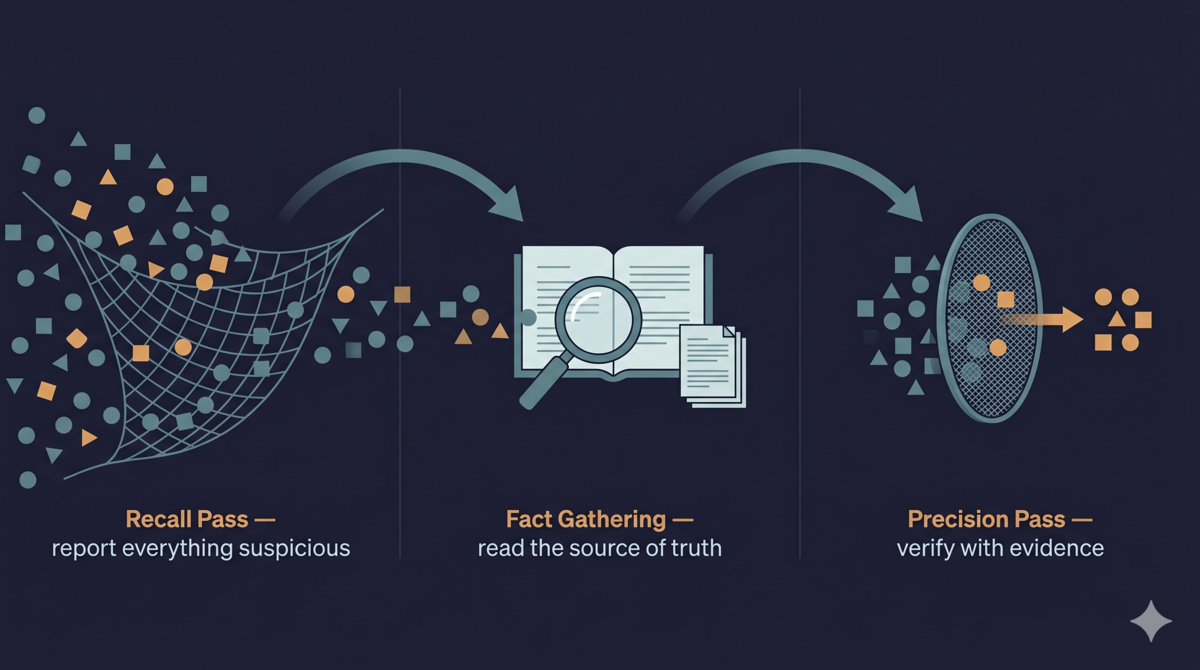
原本一个审查 agent 就够了。问题是这个 agent 既要把所有问题找出来(找全),又要保证每个问题都是真的(找准),结果两头都做不好。改动很简单:拆成两个。第一个只管找问题(Recall Pass),第二个只管过滤误报(Precision Pass)。
实测结果来自一个量化交易项目的设计审查——同一份设计文档,分别跑单轮和双轮模式做对比。注意:这是单次任务的观察,不是大规模统计,趋势可参考,具体数字别太较真。
| 指标 | 单轮审查 | 双轮审查 | 变化 |
|---|---|---|---|
| 每轮原始发现 | 16 | 25→12(过滤后) | 找得更多,过滤后保留 12 个 |
| 严重真实问题 | 2 | 2 | 一样,但更确定 |
| 严重误报 | 1 | 0 | 彻底消除 |
| 有效发现率 | ~75% | ~92% | +17 百分点 |
| 每轮 AI 调用 | 1 | 2 | 翻倍 |
| 预期审查轮次 | 5-7 | 3-5 | 少 30~40% |
调用次数翻倍了,但审查轮次少了 30-40%。算总账,花的 token 差不多,有效发现率从 75% 升到 92%。每找到一个问题花的 token 反而更少。
更关键的是审查行为变稳了。第一轮总是放手找,第二轮总是严格筛。不像单轮模式那样——前几轮猛报、后几轮不敢报,行为飘忽不定。
设计阶段的问题越早发现,下游开发返工的成本越低。双轮审查在方案设计阶段就把问题拦截了,不用等代码写完才发现设计缺陷。
意外收获:双轮模式抓到了单轮模式漏掉的真实设计缺陷——需求文档里遗留了迁移前的评分维度引用(baseline_score/graham_score),设计方案里没有更新。单轮审查的 16 个发现里没有这个。双轮的 Recall Pass 在 25 个发现里报了它,Precision Pass 确认了它。
找得全和找得准,为什么不能兼得
搜索引擎领域有一个常识:找得全和找得准是互相矛盾的。
找得全 = 不放过任何可疑的问题,代价是一堆误报。找得准 = 每个报告都是真问题,代价是有些问题被漏掉了。想同时做到两样,结果通常是两头都一般。这不是能力问题,是目标本身在打架。
教科书里用一张图讲这件事。横轴是"找得全"的程度(Recall),纵轴是"找得准"的程度(Precision)。调高一个,另一个通常会下降[1]。
审查也一样。审查标准放宽松,能找到更多问题,但其中不少是误报。审查标准收紧,误报少了,但真问题也可能被一起筛掉了。
搜索引擎、垃圾邮件过滤、医疗诊断都在和这对矛盾打交道,60 多年了——1966 年 Cranfield 实验就明确证明了 Recall 和 Precision 的反比关系[4],从那时起这就成了 IR 评估的基础常识。
级联检索:搜索引擎的解法
信息检索领域解决这个矛盾的方法是级联检索(Cascade Retrieval)——把一个检索任务拆成多级,每一级的目标不同。
2011 年,Wang、Lin 和 Metzler 在 SIGIR 上提出了级联排序模型[2]。他们的出发点是效率:用简单函数快速筛掉大部分无关文档,只在少数候选上跑复杂模型。级联架构天然形成了"前级宽、后级严"的结构。
Dang、Bendersky 和 Croft 在 2013 年把这个结构往找全/找准方向说得更直白[3]:第一级负责不漏(recall-oriented),第二级负责不错(precision-driven)。 两个目标拆到两个阶段,各自优化。这正是双轮审查直接借鉴的思路。
不只是搜索引擎。你刷抖音、逛小红书、看微信推荐的公众号文章——背后都是同一个架构:先召回,再精排。第一轮从海量候选里捞出来(尽量不漏),第二轮用复杂模型挑出你最可能感兴趣的(尽量不错)。搜索、广告、推荐,整个「搜广推」系统都是这个框架。
关键类比:「搜广推」要从海量内容里挑出你感兴趣的,设计审查要从一份方案里挑出真正的问题。候选物不同,但问题一样——都怕漏掉有价值的。级联检索的思路通用。
为什么拆开对设计审查有效
设计方案的问题更微妙。不是"代码有没有 bug",是"需求是否完整"“设计是否一致"“边界条件是否考虑了”。
单个 prompt 同时要求两件事:“找出所有设计问题"和"确保每个问题都是真的”。这两个指令互相矛盾。模型在一个 prompt 里被拉向两个方向。
拆成两轮,每轮只优化一个目标。
Recall Pass 的 prompt 只说一件事:宁可多报,不可遗漏。 不太确定的也报。半信半疑的也报。纯靠直觉的也报。“需求文档可能遗漏了一个场景”——报。
Precision Pass 的 prompt 也只说一件事:逐一验证每个发现的真实性。 只保留有证据支撑的。没有证据的,REJECT。
两轮之间还插了一个事实收集步骤。这让 Precision Pass 的判断有客观证据可用,而不是拿一个猜测去判断另一个猜测。
两轮之间做了什么
事实收集做什么?
- 读取前序阶段的需求文档(验证跨阶段一致性)
- 对照需求清单检查完整性
- 读取项目的编码规范/RULES.md(验证最佳实践类发现)
有了这些证据,Precision Pass 的判断从"感觉这个需求好像缺了什么"变成"需求文档里没有这个验收标准,CONFIRM”。前者是猜,后者是查。
baseline_score/graham_score 残留引用就是这样抓到的。Recall Pass 在 25 个发现里报了"需求文档疑似遗留旧评分维度"。事实收集步骤一查,需求文档里这两个标识符还在用,设计方案里却没更新。Precision Pass 据此判定为真问题。
单轮审查的 16 个发现里没有这个——单轮模式在"报还是不报"之间犹豫,把它过滤掉了。
怎么想到的
灵感来自观察审查 agent 对设计方案的审查行为。
跑了几轮之后,我发现一个现象:同一个审查 agent,前几轮倾向于多报(怕漏),后面轮次倾向于少报(怕误报)。同一个 prompt,同一份设计文档,审查行为随轮次变化。
最开始我看到每轮报的错变少,还挺高兴——觉得这是收敛了,是好事。还专门写过一篇文章讲审查循环要收敛(Ralph Loop:AI 的错误不是随机的,是收敛的)。
用了一段时间后才发现,我只理解了一半。问题变少和收敛确实是必要的,但收敛不该靠模型自己怂下来。实际跑下来,审查轮次会被拉得很长,后面每一轮都像挤牙膏,零星几个问题,有时候还是前几轮重复报过的。
这说明模型不是不知道"找全"和"找准"的区别。是同一个 prompt 里同时要求两个目标,模型只能自己在中间权衡。
每轮审查是独立的,模型并不知道这是第几轮、还剩几轮。但随着设计文档被修订,明显的问题被改掉了,剩下的都是模型自己也拿不准的边缘问题。单 prompt 模式下,模型在"报还是不报"之间犹豫——既要"找全"又要"找准"的指令让它倾向于保守。
与其让模型自己权衡,不如把权衡拆开。第一轮专心找全,第二轮专心找准。
把这个思路落到 LLM 审查上,我不是第一个。G-Research 的数据与分析团队在 2026 年 5 月写过一篇博客[5],讲他们做内部代码审查工具时怎么用双轮 LLM 调用,第一轮抓召回、第二轮抓精确率。他们的核心结论一句话——“separate recall and precision,两个简单的 pass 比一个复杂 prompt 效果好”。看到那篇文章我恍然大悟:这不就是级联检索吗。我把同样的思路从代码审查搬到了设计审查,并把它和 15 年前 IR 的级联检索理论对上号——再往下挖,底层是 60 年前的 Recall/Precision 矛盾。
不止设计审查
我自己在代码审查上也跑了一遍——结果和 G-Research 报告的一致:有效发现率从约 75% 升到约 92%,严重误报从 1 降到 0。同样是单次任务的观察,不是统计结论。但能在不同代码库、不同审查规则下复现 G-Research 的结果,又能跨到设计审查上同样有效——双轮模式不像是碰巧有效的策略。
留一个问题
双轮审查解决了审查行为不稳定的问题。但它引入了一个新问题——负责"找全"的那个 agent 报什么、不报什么,仍然受 prompt 写法影响。如果 prompt 写得不好,可能系统性地漏掉某一类设计问题。
那 prompt 到底该写什么、不该写什么?
我自己也以为 prompt 越详细、约束越多、例子越全,模型表现越好。后来发现完全反了。
下一篇见。
参考
- Manning, C. D., Raghavan, P., & Schütze, H. Introduction to Information Retrieval, Cambridge University Press, 2008, Chapter 8. https://nlp.stanford.edu/IR-book/information-retrieval-book.html
- Wang, L., Lin, J., & Metzler, D. “A Cascade Ranking Model for Efficient Ranked Retrieval,” SIGIR, 2011, pp. 105–114. https://dl.acm.org/doi/10.1145/2009916.2009934
- Dang, V., Bendersky, M., & Croft, W. B. “Two-Stage Learning to Rank for Information Retrieval,” ECIR, 2013, pp. 423–434. https://link.springer.com/chapter/10.1007/978-3-642-36973-5_36
- Cleverdon, C. W., Mills, J., & Keen, E. M. Factors Determining the Performance of Indexing Systems, Volume 2: Test Results, Aslib Cranfield Research Project, College of Aeronautics, Cranfield, 1966.(Cranfield II 报告,原文证明 Recall 与 Precision 的反比关系)https://dspace.lib.cranfield.ac.uk/items/aa7d3ba6-091b-47ff-aa96-8d9511a3d263
- G-Research, “Building a code review tool: The LLM patterns that actually work,” 2026 年 5 月。https://www.gresearch.com/news/building-a-code-review-tool-the-llm-patterns-that-actually-work/