这是"用 TDD 驯服 AI 编码代理"系列的第二篇。上一篇讲了测试层的需求锚定方法[1]。测试的前提是需求清晰。本篇回头补上游——需求层的消歧实践。
第一版的教训:一句话需求,371 行污染
Aristotle 第一版没有 GEAR 协议[2],没有角色分工。整个反思功能写在一个 371 行的 SKILL.md 里。需求描述只有一句大意:系统能识别用户对 AI 错误的纠正,生成可复用的规则。
AI 拿到这句话,直接开工。3 个 commit,从 SKILL.md 到测试脚本到 README,一气呵成。37 个静态断言全部通过,E2E 测试一路绿灯[3]。
上线用了才发现,反思任务根本没走后台。它直接在主 session 里跑了起来,371 行 SKILL.md 全部注入上下文。子进程完成后,background_output(full_session=true) 又把整份 RCA 报告拉回主 session。审核流程更离谱——task() 创建的子 agent session 是非交互式的(这是 OpenCode 的架构限制),用户根本无法在子 session 里做审核确认。
设计原则里写了"主会话上下文零污染"“过程对用户透明”。一句都没兑现。
为什么?因为需求里没说清楚三件事:
- 反思必须在独立的后台 session 执行,主 session 不能被污染——没写。AI 自然选了最简单的实现方式:把所有东西塞进同一个 session。
- 审核必须在用户可交互的环境中完成——没写。AI 不知道
task()创建的 session 是非交互式的,它直接假设子 session 能做审核。 - 反思完成后只能通知用户,不能把完整输出推回主 session——没写。AI 选了最直接的信息传递方式:全量推送。
这不是 AI 的 bug。是我给的需求有缺失。AI 按照最常见的模式填充了所有我没说清楚的细节。在传统开发中,开发者会追问这些约束条件。AI 不会追问——它直接填空。
为什么 AI 不会追问需求
LLM 的结构特性决定了它不会主动追问。它被训练成"给出答案",不是"提出问题"。这不是缺陷,是设计目标。
用户输入一个问题,LLM 会在训练数据中寻找最可能的回答。它的训练目标是最大化下一个 token 的预测准确率。提问意味着预测中断,不符合训练目标。
这种特性在生成内容时是优势。在需求工程中是灾难。 你给的需求越模糊、越不完整,AI 填充的细节越多。这些细节不是你想要的,是训练数据里最常见的。等你发现偏差时,已经有几百行代码写好了。
AI 没有"追问需求"的天然动力。你必须在上游堵死漏洞——不是堵歧义,是堵缺失。
GEAR 协议:从漏洞中诞生的结构化方法
GEAR 全称 Git-backed Error Analysis & Reflection。它不是一开始就规划好的。它是被第一版的四个问题逼出来的。
第一版只有一个 agent 角色,所有逻辑塞在一个 371 行的 SKILL.md 里。翻车后拆成了四个文件:路由逻辑留在 SKILL.md(84 行),反思启动在 REFLECT.md,审核在 REVIEW.md,子 agent 分析协议在 REFLECTOR.md。每个文件只在一个场景被加载。
但拆文件只解决了上下文污染。更深的问题是:谁负责写规则,谁负责审核,谁负责消费——这些角色职责没有定义清楚。拆文件之后,我意识到需要一个协议来规定角色之间的关系。这就是 GEAR 的起源。
GEAR 的核心是 PAC 模型(Production-Audit-Consumption)和 Δ 决策因子。PAC 把写规则(R)、审规则(C)、用规则(L)三种角色完全分离,R 只管产不管判,C 只管审不管改,L 只管用不管审。Δ 因子根据置信度、风险权重和历史数据决定审核级别——新规则强制人工审核,积累足够数据后逐步自动化。这套机制解决了规则质量管理的问题[4]。
但 GEAR 解决的是错误反思的流程规范。需求文档怎么写,GEAR 本身没有规定。tdd-pipeline 项目[5]在需求阶段用的是 User Stories + Given-When-Then 验收标准,加上 core/secondary 两级优先级,和 GEAR 的 PAC/Δ 没有关系。
这篇文章的主题是需求缺失。GEAR 的价值不在于直接指导需求写法,而在于它提供了一个教训:没有结构化的协议,AI 会按最省事的方式填空。 这个教训在需求层同样成立。
需求文档该怎么写
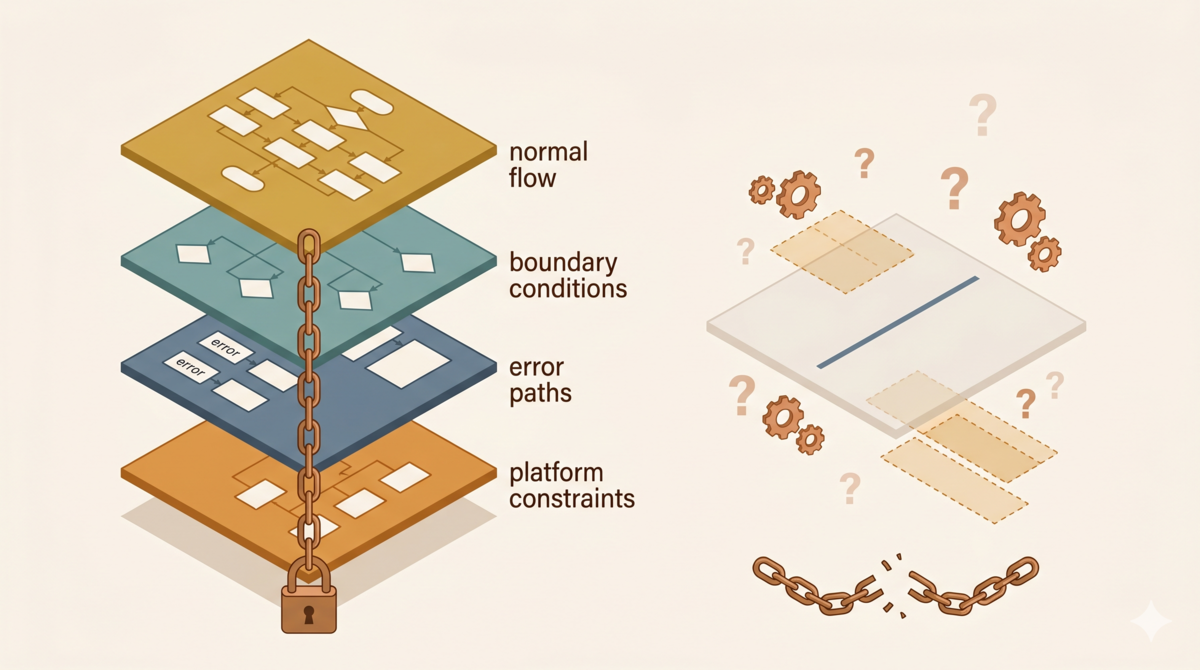
第一版的需求只有一句话。结构化的需求文档应该包含什么?从第一版的教训反推,至少需要四个部分。
以反思触发功能为例。
模糊版需求
“当用户纠正 AI 的错误时,系统应提示用户启动反思流程。”
结构化版需求
需求编号:AC-001 所属模块:反思触发 优先级:core(核心功能)
正常路径
- 用户发送包含明确错误纠正的消息 → 系统显示反思提示卡片
- 用户点击"启动反思" → 系统创建独立反思 session,不污染主会话
- 反思完成后 → 系统生成规则提交审核,提示用户查看结果
边界条件
- 用户说"不对"但未说明具体错误 → 仍然触发提示
- 用户纠正的是产品设计意见而非事实错误 → 不触发提示
- 用户在同一轮对话中多次纠正 → 只显示一次提示
- 对话历史为空 → 不触发提示
- 纠正关键词出现在代码块注释中 → 不触发提示
错误路径
- 反思 session 创建失败 → 显示错误提示,引导用户重试
- 规则生成失败 → 显示失败原因,不静默
- 审核流程超时 → 自动保存草稿,通知用户后续处理
平台约束
task()创建的子 session 是非交互式的——审核不能在子 session 中进行,必须在主 session 实现- 反思完成后只能通知用户,不能把完整输出推回主 session——信息流必须是拉取模式
对比一下:模糊版只说了"做什么"。结构化版把"什么时候做"“什么时候不做"“做失败了怎么办"“平台有什么限制"全写清楚了。AI 拿到结构化版,不需要猜。
注意"平台约束"这一段。这是第一版需求完全缺失的部分,也是翻车的直接原因。如果当时写了”task() 创建的子 session 是非交互式的"这条约束,AI 就不会假设用户能在子 session 里做审核。
这四个部分不是 GEAR 定义的。是行业里验收标准、边界条件、错误路径的通用写法。核心原则只有一条:凡是你没写的,AI 会自己填。你填的越详细,AI 填的空间越小。
怎么逼自己写出这四个部分
知道该写四个部分,不代表能写出来。第一版的时候,我根本没意识到"平台约束"是一个需要写的东西——我不知道自己不知道。
tdd-pipeline 项目[5]用了一个方法来解决这个问题:苏格拉底提问。在需求阶段(Phase 1),流程强制要求对用户做 deep-interview,至少提 3 个澄清问题,目标是 3-5 个。问题包括:
- 这个解决什么问题?
- 谁是参与者?
- 系统的边界在哪里?
- 什么明确不在范围内?
接下来还有一个关键步骤:挑战模糊术语。“快速”、“安全”、“用户友好"这类词必须被逼到可量化。未声明的约束(法规、性能、兼容性)必须被识别。所有歧义不解决完,不准进入下一阶段。
这不是指望 AI 自己追问。是在流程里强制规定:必须追问,至少 3 个问题,不解决完不许往下走。
在传统开发中,这个追问发生在开发者脑子里——有经验的开发者会自然地问这些问题。AI 不会。所以你必须把"脑子里的追问"外化成流程步骤。tdd-pipeline 做的就是这件事。
系列预告
这篇文章讲的是需求层的消歧实践。管线的其他环节,每一步都有各自的坑和值得我学习的教训:
- 设计层:PRD 到技术方案的映射——第二次重构时,需求写清楚了,但
task(run_in_background=true)的异步行为没有提前验证,agent O 仍然在主 session 里被拉起。为什么跳过技术调研,AI 会自作主张填补空白 - 审核机制:Ralph Loop 的设计哲学——AI 的错误是系统性的,需要结构化审核而非随机 review
- 全流程总结:从需求到代码的一张图——严格流程的边际成本随项目复杂度下降,随 AI 参与度上升而必要
整个系列的核心主张:AI coding agent 是放大器。它放大你的工程能力,也放大你的工程债务。驯服它需要比传统开发更严格的流程纪律。
参考
- 上一篇文章:先写测试文档,再写测试代码:AI 开发的需求锚定
- GEAR 协议 RFC:一份 Markdown 的三次生命:从静态规则到 Git 版本管理的 MCP Server
- Aristotle 改造实录:从四道伤疤到一套铠甲:Aristotle 改造中的驾驭工程实践
- GEAR 协议规范:DOI 10.5281/zenodo.19660780
- tdd-pipeline 项目:https://github.com/alexwwang/tdd-pipeline