这是"用 TDD 驯服 AI 编码代理"系列的第一篇。整个系列讲一件事:为什么 AI 辅助开发需要比传统开发更严格的流程纪律,以及每一步具体怎么做。
系列会按管线的顺序展开——需求、设计、测试、审核、实现。但本篇从测试层切入,因为在第三次重构 Aristotle 的过程中,测试方案文档是让我体会最深的一环。先讲这一环,再回头补上游和下游。
前传:两次翻车,第三次才学会走路
Aristotle 是我开发的一个 AI 错误反思学习工具。开发过程中重构了两次,两次都没能实现需求描述的能力。
第一次开发,37 个静态断言全部通过,E2E 测试一路绿灯。但上线后发现主 session 被注入了 371 行上下文。审核流程在非交互式子 session 里根本跑不通[1]。测试验证了"协议有没有正确执行",没验证"副作用是否可接受"。
第一次翻车暴露了一个问题:需求文档里的歧义太多,AI 不会追问,直接按自己的理解填充。为了堵住这个问题,我设计了 GEAR 协议——一种需求消歧协议,强制把每条需求的验收标准、边界条件、错误路径全部写清楚。这个协议在后续文章会详细介绍。
第二次重构用 GEAR 协议锁定了需求。解决了上下文污染和审核断裂的问题。代码结构拆分了,信息流改成了拉取模式,设计原则看起来落地了。但装完跑了一遍,发现反思功能仍然没有实现需求描述的能力。检测纠正信号的准确率远低于预期,生成的规则在多数场景下不能正确匹配。第二次重构修的是上一版暴露的副作用,但没人问过"需求描述的能力,安装后到底有没有"。
两次失败指向同一个根因:没有测试方案文档,测试代码只覆盖了执行路径,没覆盖需求本身。第一次漏掉了设计原则的约束,第二次漏掉了功能正确性的验证。
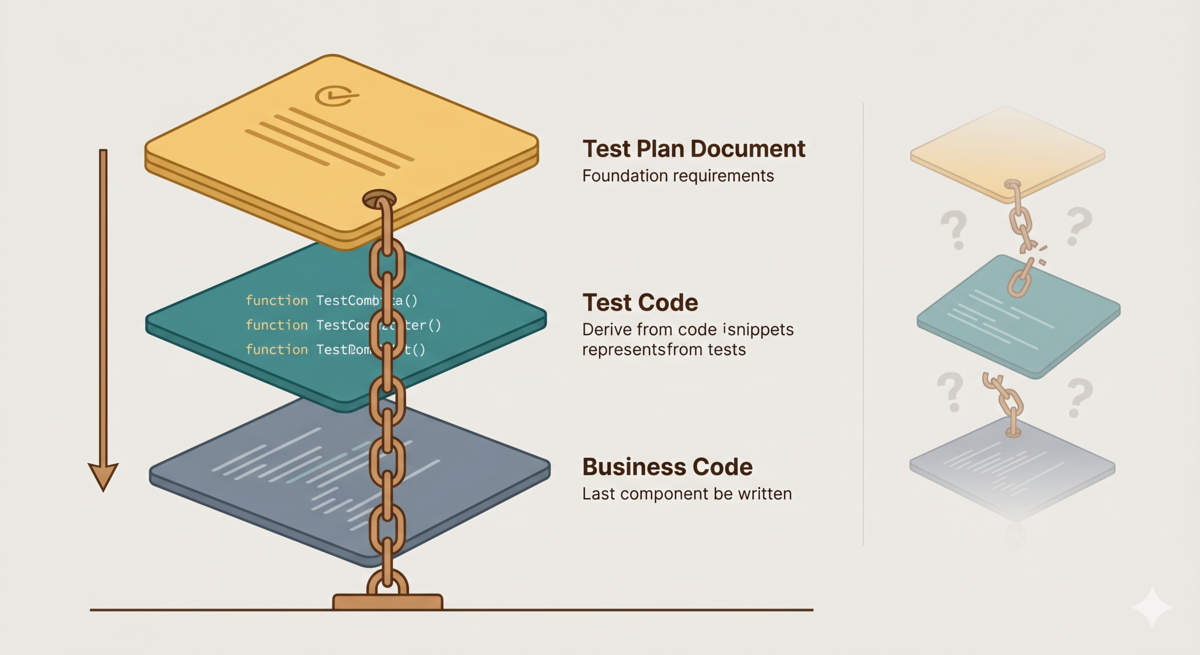
第三次重构,我改变了工作方式。不再直接写代码。按管线一步一步来:GEAR 协议写需求 → 产品设计文档 → 技术方案文档 → 测试方案文档 → 测试代码 → 业务代码。每个阶段有独立的 reviewer 审查,直到零问题才放行。
这篇文章讲的是测试方案文档这一环——为什么它必须先于测试代码存在,在 AI 辅助开发中它的角色发生了什么变化,以及具体该怎么写。
为什么"测试代码先于业务代码"在 AI 开发中更重要
经典的 TDD 教科书会说:先写一个失败的测试,然后写最少的业务代码让它通过,再重构[2]。这个顺序在传统开发中已经够好了。但在 AI 辅助开发中,“先写测试"的权重被放大了一个量级。
原因有三个。
第一,AI 对自然语言的歧义毫无警觉。有经验的开发者读到"用户应该能注册”,会追问"邮箱格式有什么要求?密码长度限制呢?重复注册怎么处理?"。AI 不会追问。它会把"用户应该能注册"直接翻译成一堆 happy path 代码——标准邮箱、8 位密码、一切正常。然后你觉得"能跑",直到边界情况暴露问题。
测试用例是消除歧义的最精确工具。should_reject_registration_with_duplicate_email() 不存在解读空间。过就是过,不过就是不过。你能给 AI 的最精确的语言是测试用例。不是需求文档里的用户故事,也不是技术方案里的架构图。
第二,AI 生成代码的速度远超人类审查的速度。人类开发者写代码有个自然节奏,写的过程中思路本身就是一道关卡。AI 一秒钟能生成几百行代码,人类的审查速度跟不上。如果没有测试作为自动化的质量闸门,AI 生成的代码里藏着的 bug 会比传统开发多得多。不是 AI 的代码质量更差,而是人类来不及看。
第三,AI 的错误不是随机的,是系统性的。误解需求、假设上下文、过度简化,Aristotle 的 8 类错误分类里,每一种都有明确的模式[3]。系统性错误需要系统性约束。测试方案文档就是这个约束的载体。它不是事后验证的工具,而是事前防止系统性偏差的护栏。
所以在 AI 辅助开发中,TDD 不仅仅是"好的工程实践",而是不可或缺的风险控制手段。没有它,AI 的高产出不是效率,是速度掩盖下的技术债积累。
需求锚定:测试方案文档的定位
这套方法不是凭空发明的。需求追溯矩阵(Requirements Traceability Matrix,RTM)是 ISO/IEC/IEEE 29148 定义的标准实践——每条需求必须能追溯到测试用例,每个测试用例必须能追溯到需求[5]。Gojko Adzic 在 2011 年出版的 Specification by Example 中提出,用具体例子而非抽象描述来定义需求,这些例子直接变成可执行的验收测试[6]。验收测试驱动开发(ATDD)则是将这三个概念串联起来的工作流程。
这些方法在传统软件开发中已经成熟。我的贡献不是发明新概念,而是回答一个问题:当编码者从人类变成 AI 时,这些已有的工程实践为什么从"锦上添花"变成了"不可或缺"。
传统开发中,RTM 和 SBE 是质量保障的手段。即使没有它们,人类开发者在编码过程中会追问、会讨论、会在代码评审中发现遗漏。AI 不做这些事。它拿到一个模糊的需求,直接输出代码,速度之快让你来不及在过程中纠正。这意味着传统开发中的"人类兜底机制"消失了——RTM 和 SBE 从"质量加分项"变成了"唯一的质量闸门"。
从这个视角出发,我给 RTM + SBE + ATDD 的组合应用取了一个简称:需求锚定。核心就一句话——测试锚定在需求上,不锚定在实现上。这个简称不是新概念,只是方便记忆。
传统开发流程中,RTM 和 SBE 的实践者一直在做"从需求推导测试"这件事,但实现代码仍然可以先于测试存在。在 AI 辅助开发中,这个顺序必须严格锁定。AI 太快了,需求写完两分钟就给你"实现完了"。你还没来得及设计测试方案,代码已经"能跑了"。等到发现需求理解错了,已经是一堆需要推翻重写的代码。
需求锚定把测试方案文档提前到实现之前。流程变成:
产品设计 → 技术方案 → 测试方案文档 → 测试代码 → 业务代码
测试方案文档回答的问题是"怎么验证需求被正确实现了",而不是"怎么验证代码做了它做的事"。这两者的区别很重要。
举个例子。实现 Aristotle 的反思功能时:
- 从实现推导:测试
Reflector.generate_rca()方法是否返回了正确格式的 JSON。测的是代码的行为。 - 从需求锚定:测试"用户触发反思后,系统是否生成了包含根因分析的可审核报告"。测的是需求的满足。
前者验证的是代码,后者验证的是意图。回到上面的对比:从实现推导的测试,测的是代码行为;从需求锚定的测试,测的是需求满足。当 AI 把实现从方案 A 改成方案 B 时,前者大概率失效,后者纹丝不动。测试锚定在需求上,不锚定在实现上。
测试方案文档的四层结构
一份测试方案文档包含四个层次:测试场景识别、测试点梳理、测试用例定义、测试开发文档。每一层都是前一层的细化,每一层都有明确的输入和输出。
第一层:测试场景识别
输入:需求文档的验收标准(Acceptance Criteria)。
做法:把每一条验收标准展开成测试场景。一条验收标准通常对应多个场景——happy path、边界情况、错误路径。
以 Aristotle 的反思触发为例。验收标准写成:“当用户在对话中纠正 AI 的错误时,系统应提示用户启动反思”。
展开成测试场景:
- 用户明确纠正了 AI 的错误 → 应触发提示
- 用户含糊地说"不对" → 应触发提示
- 用户纠正的是意见分歧而非事实错误 → 不应触发
- 用户在同一轮对话中多次纠正 → 应只提示一次
- 对话记录为空 → 不应触发
注意,这个展开过程本身就是对需求的第二次检验。写场景 3 的时候,你被迫回答一个问题:“意见分歧和事实错误的边界在哪里?“如果你答不上来,说明验收标准不够精确。这就是需求锚定的价值——测试场景把需求的模糊地带逼出来。
第二层:测试点梳理
输入:测试场景列表。
做法:为每个场景定义具体的测试点。测试点是二值的——过或不过,没有中间状态。这一层只回答"测什么”,不关心"怎么测”。
场景 1 展开成测试点:
- 检测到包含纠正关键词的用户消息 → 触发
- 纠正关键词出现在代码块注释中 → 不触发
- 连续两条消息构成一次纠正 → 触发
- 纠正关键词后跟"算了不用改了" → 不触发
注意第二层和第三层的区别:第二层列出的是检查项——“纠正关键词出现在代码注释中时不应触发”,它是场景的细化,但还没有具体的前置条件和操作步骤。第三层才会把每个检查项展开成完整的可执行用例——给定什么输入、执行什么操作、期望什么输出。先列检查项再写完整用例,可以防止在细节中遗漏场景。
每个测试点对应一条可执行的断言。走到这一步,测试就从"验证需求"变成了"定义接口"。should_trigger_on_explicit_correction() 这个测试名,本质上是在定义 CorrectionDetector 的公共接口。
第三层:测试用例定义
输入:测试点列表。
做法:把测试点组织成具体的测试用例。每个用例包含前置条件、操作步骤、预期结果。
这是给 AI 最精确的指令。一个测试用例的格式:
用例:显式纠正触发反思提示
前置:对话历史包含 3 轮正常交互
操作:用户发送 "你第 2 轮的回答里把 API endpoint 写错了,应该是 /api/v2/reflect 不是 /api/v1/reflect"
预期:系统在下一轮响应中包含反思提示
AI 读到这个用例,知道输入是什么、输出应该是什么、边界在哪里。比任何自然语言的需求描述都精确。
第四层:测试开发文档
输入:测试用例列表、技术方案文档。
做法:把测试用例映射到具体的测试文件、测试函数名、测试类型(unit / integration / e2e)。
这一层产出的就是测试覆盖矩阵。我在 tdd-pipeline 项目[4]里把它定义为 Phase 3 的核心交付物。以下为 Aristotle 场景的示例:
| # | 验收标准 | 测试类型 | 测试文件 | 测试函数名 | 描述 |
|---|---|---|---|---|---|
| 1 | AC-1 | Unit | test_detector.py | should_trigger_on_explicit_correction | 显式纠正触发提示 |
| 2 | AC-1 | Unit | test_detector.py | should_not_trigger_in_code_comment | 代码注释中的纠正不触发 |
| 3 | AC-1 | Unit | test_detector.py | should_trigger_on_multi_turn_correction | 跨轮次纠正触发 |
这张表是测试方案文档的核心交付物。它的每一行都是一条可执行的契约。后续的测试代码只需要按表实现,业务代码只需要让表里的每一行通过。
为什么测试方案文档能防止 AI 的系统性偏差
回到开头的教训。两次重构 Aristotle,两次跳过了测试方案文档。
第一次,测试代码只覆盖了协议的执行路径。Coordinator 启动了 Reflector,Reflector 读取了 session,生成了 DRAFT。全部通过。但设计原则有三条:即时触发、会话隔离、人在回路(即关键操作必须用户确认才能生效)。测试代码覆盖了"即时触发"的执行路径,完全没覆盖“会话隔离"和"人在回路"的约束。
第二次重构修了副作用。上下文污染消除了,审核流程跑通了。但反思功能本身的正确性——检测纠正信号、生成匹配规则——依然没有测试覆盖。因为两次都没有测试方案文档,我从没系统性地问过自己这个问题:“每条需求对应哪些测试场景?每条设计原则对应哪些测试场景?”
测试方案文档强制你做这件事。它的第一层——测试场景识别——要求从验收标准出发,覆盖 happy path、边界、错误路径。如果验收标准里有"会话隔离"这一条,测试场景就必须包含:
- 主 session 的上下文在反思前后的 token 变化 ≤ N
- 反思过程的输出不自动注入主 session
- 用户必须主动拉取审核报告
这些场景不是从实现推导的,是从需求锚定的。无论 AI 把反思功能实现成子进程、子 agent 还是远程调用,这些测试场景都不变。
测试方案文档是 AI 编码的安全网。它把"需求理解对了没有"这个问题,从"AI 自己判断"变成"AI 照着表执行”。人类定义表,AI 填实现。有了测试方案文档,人类审查的重心从"代码有没有实现需求"转移到"表的完整性够不够"。但代码审查本身并没有消失。安全漏洞、性能问题、可维护性依然需要人来看。测试方案文档缩小了审查范围,没有替代审查本身。
第三次重构:测试方案文档实战
第三次重构 Aristotle 时,我按四层结构写了完整的测试方案文档。效果立竿见影——不是测试本身的效果,是写测试方案的过程中发现问题的效果。
写测试场景时,我发现了两个之前从未暴露的缺陷。
第一个是测试方法选择错误。Aristotle 的反思触发有两条路径:同步回退和异步通知。之前的测试用的是非交互式模式(opencode run --format json),这种模式不支持异步通知回调。但测试场景定义的是异步路径,所以测试结果时过时不过——不是被测逻辑不稳定,是测试环境根本不匹配。三轮回合修修补补,每轮"看起来收敛了一点",最后声称"验证通过"。实际上从头到尾都在测错误的东西。
这个问题的根因:没有测试方案文档,测试代码直接从实现推导,没有先问"被测功能的真实运行环境是什么"。测试方案文档的第一层——测试场景识别——会强制你回答这个问题。
第二个是测试盲区。按四层结构写完测试方案后,我让 reviewer 对照需求文档审查。审查发现了 13 个测试盲区。其中一个典型例子:retry_pending 路由的静态验证通过了,但运行时的路由行为没有覆盖。静态验证检查的是配置结构,不是运行时决策。没有测试方案文档的系统性对照,这类"配置正确但行为错误"的盲区几乎不可能被发现。
同时,用户测试也暴露了测试方案文档本可以预防的问题。比如 P0 级别的 bug:首次安装不会初始化 git 仓库,导致 write_rule() 直接失败。如果测试场景里有"全新安装后执行完整反思流程"这个场景,这个 bug 在开发阶段就会被抓到。
第三次重构的测试方案文档最终定义了 95 条新测试。这不是拍脑袋定的数字,是从需求逐层推导出来的。每一条测试都能追溯到具体的验收标准或设计原则。这是和前两次的本质区别:前两次测试覆盖的是"代码做了什么",这次覆盖的是"需求要求什么"。
从测试方案到测试代码:TDD Pipeline 的实现
我把这套方法固化成了一个可复用的工具:[tdd-pipeline][4]。
它把 AI 辅助开发拆成 5 个阶段,每个阶段有明确的交付物和审核关卡:
产品设计 → 技术方案 → 测试方案文档 → 测试代码 → 业务代码
规则只有一条:测试代码不存在,或存在但未失败时,禁止编写业务代码。
这条规则在传统开发中是最佳实践,在 AI 辅助开发中是生存必需。AI 生成业务代码的速度太快了。如果没有测试方案文档作为锚点,AI 会在两分钟内给你一个"看起来能跑"的实现。而你来不及判断它是否真的满足了需求。
tdd-pipeline 的 5 个阶段对应 5 份文档,每份文档之间有强制审核机制(Ralph Loop)——独立的 reviewer subagent 审查每个阶段的交付物,直到连续两轮零问题才放行。这把关每一步的质量,也防止了 AI 把上一阶段的错误带入下一阶段。
测试方案文档(Phase 3)是这个管线的关键节点。它承接技术方案(Phase 2)的架构设计,输出测试覆盖矩阵。Phase 4 的测试代码严格按矩阵实现,Phase 5 的业务代码严格以让测试通过为目标。任何一环跳过,后续的所有工作都建立在沙子上。
原则:如果你无法为某个功能写出一个失败的测试,说明你对它的理解还不够深入,不应该开始写代码。
一点反思
“测试是可执行的需求规格说明”——这个观点并不新。Kent Beck 在 2002 年就写了[2]。但在 AI 辅助开发的语境下,它获得了全新的紧迫性。
传统开发中,需求模糊的代价是返工。人类开发者会追问、会讨论、会在编码过程中发现歧义并修正。AI 不做这些事。它拿到一个模糊的需求,直接输出代码。速度之快让你来不及在过程中纠正。等你在结果里发现偏差时,代码已经写了一堆。推翻的成本远高于一开始就把需求定义清楚。
所以测试方案文档在 AI 开发中的角色发生了变化。它不仅是开发阶段的参考文档,更是需求的最终裁决者。需求文档可能有歧义,技术方案可能有遗漏。但测试用例是二值的。一个测试要么通过要么不通过。这个确定性在 AI 的高速度面前是唯一的锚点。
Aristotle 两次重构两次翻车,我学到的教训是"测试通过不代表需求满足,副作用修好了不代表功能正确"。这个教训催生了 tdd-pipeline,形成了"先写测试方案文档,再写测试代码"的流程。它也促成了这篇系列文章。
说句实话,不是每个项目都值得走完整的测试方案文档流程。50 行的脚本、简单的 CRUD 接口,直接写测试代码就够了。这套方法的价值随项目复杂度和 AI 参与度上升——当 AI 生成的代码量超过你能逐行审查的阈值时,测试方案文档从"锦上添花"变成"不可或缺"。
系列预告
这篇文章讲的是测试方案文档。管线的其他环节,每一步都有各自的坑:
- 需求层:GEAR 协议——LLM 没有"追问需求"的天然动力,你必须在上游堵死歧义
- 设计层:PRD 到技术方案的映射——为什么跳过这步,AI 会自作主张填补空白
- 审核机制:Ralph Loop 的设计哲学——AI 的错误是系统性的,需要结构化审核而非随机 review
- 全流程总结:从需求到代码的一张图——严格流程的边际成本随项目复杂度下降,随 AI 参与度上升而必要
核心就一句话:测试用例是能给 AI 的最精确的语言。 在让 AI 写一行代码之前,先想清楚怎么验证它。
参考
- 关于 Aristotle 初版的测试假象问题,详见 从四道伤疤到一套铠甲:Aristotle 改造中的驾驭工程实践
- Kent Beck, Test-Driven Development: By Example, Addison-Wesley, 2002
- 关于 Aristotle 的 8 类错误分类,详见 Aristotle:让 AI 学会从错误中反思
- tdd-pipeline 项目源码:https://github.com/alexwwang/tdd-pipeline
- ISO/IEC/IEEE 29148:2018, Systems and software engineering — Life cycle processes — Requirements engineering
- Gojko Adzic, Specification by Example, Manning Publications, 2011