这是"用 TDD 驯服 AI 编码代理"系列的第四篇。前三篇按管线顺序讲了需求层、设计层和测试层。本篇讲最后一道防线——审核机制。
第三篇留下的问题
第三篇结尾提了一个问题:PRD 写了,技术方案写了,测试方案写了,流程是对的。但这些文档里的事实性声明——平台 API 的行为、框架的限制、依赖库的接口——都是 AI 生成的。一个人逐条核实,时间上不现实。但不核实,又可能踩进 coroutine-O——Aristotle 的异步编排原型——同样的坑。
问题本质:流程文档缩小了 AI 的填空空间,但没有解决信任问题。
需要一个机制,在不依赖人类逐条核实的前提下,系统地检查每个阶段的交付物。
为什么随机看两眼不够
常见的做法是"让 AI 自己 review 一下"。在同一个会话里,AI 写完代码,再让它回头检查。这有两个问题。
第一个问题:AI 审查自己的工作,存在确认偏误。 写代码的 AI 已经做了一系列隐含假设——“这个 API 参数存在"“这个框架支持异步回调"“这个数据结构线程安全”。让它审查自己,它会用同一套假设验证自己的结论。假设错了,审查也查不出来。
第二个问题:逐条看容易"看着都对”。 人类审查 AI 输出时,如果逐条检查每个事实声明,注意力会在第三条开始衰减。到第十条,即使有明显的错误,也容易被放过。这不是态度问题,是人类注意力的结构性限制。
这两个问题的共同根因:AI 的错误不是随机的,是系统性的。 同一个错误假设会渗透到多个模块——假设 task() 支持异步,不仅反思模块用了它,通知模块也用了它,状态管理也基于它。随机抽查看不到这种系统性扩散。
系统性错误需要系统性审核。
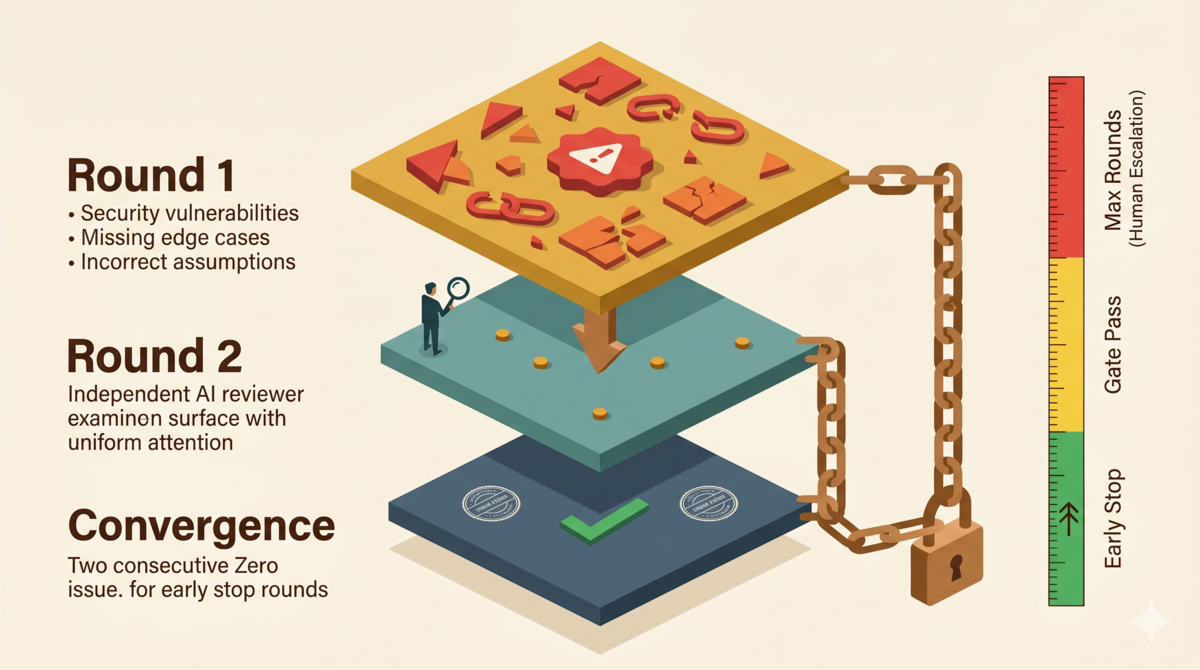
Ralph Loop:多轮收敛审核
Ralph Loop 是 tdd-pipeline 项目定义的审核协议[1]。核心设计有三个要素。
一、独立审查者
审查者和创造者必须是不同的 AI session。审查者没有参与交付物的创建过程,因此不会继承创造者的隐含假设。
实际操作:写代码的是主 session 的 AI,审查代码的是用 task() 启动的独立 subagent。两者共享项目上下文(可以读文件),但不共享对话历史。
二、严重程度分级
每个发现的问题必须标记严重程度:
| 级别 | 含义 | 处理 |
|---|---|---|
| Critical | 根本性错误,交付物不可用 | 必须修 |
| High | 重大缺陷,严重削弱交付物 | 必须修 |
| Major | 重要问题,违反需求或最佳实践 | 必须修 |
| Low | 小改进、风格问题 | 可选 |
| Info | 观察、建议,无缺陷 | 不需要处理 |
分级的作用不是给问题排序,而是定义退出条件——只有 C/H/M 清零,审核才能结束。L 和 I 可以携带进入下一阶段。三级的区别在于紧急程度:Critical 阻塞当前阶段进度,必须立即修完才能继续;High 需在本轮修复但不阻塞其他并行工作;Major 需在交付前修复但可延后到下一轮。
三、三种退出路径
Ralph Loop 有三种结局:
1. Early Stop:连续 2 轮零问题(C/H/M/L 全部为零)→ 立即通过
2. Gate Pass:第 5 轮起,当前轮 C/H/M 为零(L 可接受)→ 可以通过(多数审核在 3-4 轮内收敛,第 5 轮起仍只有 L 级问题是正常收敛的尾部噪声)
3. Max Rounds:10 轮后仍有 C/H/M → 暂停,上报人类决策
如果审查者和创造者对某个问题的严重程度有分歧——审查者标了 Major,创造者认为只是风格问题——协议的规则是"以审查者的判定为准”。审查者是独立视角,创造者有确认偏误。如果创造者认为审查者误判,可以在下一轮提供证据,由审查者重新评估。Max Rounds 本质上也是分歧升级机制——审核 10 轮仍未收敛,说明分歧无法在 AI 之间解决,需要人类介入。
最关键的是 Early Stop 的条件:连续两轮零问题。一轮干净不够,必须连续两轮。
每个阶段的典型错误模式
Ralph Loop 不是一刀切的审查。不同阶段,AI 犯的错误类型不同,审查的侧重点也不同。
需求阶段(Phase 1)
AI 最容易犯的错误:把模糊需求当成清晰需求。
“系统应该快速响应”——AI 会把"快速"理解成 200ms(训练数据里最常见的阈值),而不是追问用户"快速是指多少毫秒"。审查者需要检查:每条验收标准是否可测试、是否二值判定、是否没有主观形容词。
设计阶段(Phase 2)
AI 最容易犯的错误:基于不存在的 API 做设计。
coroutine-O 的 task(run_in_background=true) 就是典型案例。审查者需要检查:每个涉及平台 API 的决策,是否有调研结论支撑?调研结论是否标注了来源?
测试阶段(Phase 3)
AI 最容易犯的错误:写 happy-path 测试,跳过边界和错误路径。
Coroutine-O Round 1 发现的测试覆盖缺失:空结果、空 workflow_id、无效 JSON——全是边界条件,AI 默认没写。审查者需要检查:每条验收标准的 Edge Cases 是否都有对应测试?
代码阶段(Phase 4-5)
AI 最容易犯的错误:安全漏洞和 flaky test。
Coroutine-O Round 1 发现的 workflow_id 路径遍历攻击——AI 在拼接文件路径时没有校验输入。这在训练数据里不常见(因为大多数代码不考虑恶意输入),但对暴露给用户的 API 是致命的。审查者需要检查:外部输入是否做了校验?是否有注入攻击的风险?
为什么是连续两轮
这是 Ralph Loop 最容易被忽视的设计决策。为什么一轮零问题不能退出?
用 Coroutine-O 合并任务的真实审核记录举例[2]:
Round 1 发现了 26 个问题,涵盖 5 个类别:
| 类别 | 问题数 | 典型问题 |
|---|---|---|
| 安全漏洞 | 1 | workflow_id 路径遍历攻击 |
| 数据完整性 | 1 | 非原子写入可能导致数据损坏 |
| 错误处理 | 2 | 静默失败,未知事件类型返回 done |
| 注入攻击 | 1 | O_INTENT_PROMPT 的 prompt injection |
| 测试质量 | 3 | flaky timestamp test,flaky latency test |
| 测试覆盖 | 4 | 缺少空结果、空 workflow_id 等边界测试 |
| 其他 | 14 | 重复断言、gitignore 检查等 |
修完 26 个问题后,Round 2 发现 0 个新问题。16 个修复全部通过验证,无回归。按"一轮干净就退出"的规则,这里可以结束了。
但如果 Round 1 的修复引入了新的问题呢?比如修路径遍历时加了正则校验,但正则本身写错了——这种"修一个 bug 引入另一个"的情况在 AI 代码中很常见。一轮干净可能是假象:审查者碰巧没有覆盖到新引入的问题,或者修复的副作用在当前审查维度里不可见。
连续两轮零问题排除了这种假象。第一轮零证明上一轮的修复没有引入新问题,第二轮零证明第一轮的审查本身也没有遗漏。这是对收敛的双重确认。
与数学收敛的结构同构
这个设计不是拍脑袋想的。它和数学分析中的柯西收敛准则有直接的结构同构。
柯西收敛准则说的是:数列 {aₙ} 收敛的充要条件是,对于任意 ε > 0,存在 N,使得当 m, n > N 时,|aₘ - aₙ| < ε。翻译成大白话:数列收敛不是看某一项离极限有多近,而是看足够远的任意两项有多接近。
Ralph Loop 的审核轮次可以看作一个数列:{a₁, a₂, a₃, …},其中 aₙ 是第 n 轮发现的问题数。我们希望这个数列收敛到零。
一轮零问题,相当于 aₙ = 0。但这不能证明收敛——可能 aₙ₊₁ > 0,数列还在振荡。连续两轮零问题,相当于 aₙ = aₙ₊₁ = 0,两项之间的差为零。这捕捉了柯西条件的核心直觉:不是看 aₙ 和极限的差(因为极限是未知的),而是看项与项之间的差。而且,因为问题数是非负整数,连续两轮零意味着后续轮次不可能凭空出现 C/H/M 而不被审查者捕获——连续两轮零实质上满足了柯西条件。
tdd-pipeline 的协议文档甚至明确列出了"常见错误"[1],其中最频繁犯的错误就是把"一轮零问题"当成 early stop:
❌ 错误:Round 3 = 0 issues → 停止
原因:1 个零轮次不是 early stop,需要连续 2 个
❌ 错误:Round 3 和 Round 5 都是 0 → early stop
原因:Round 3 和 Round 5 不连续,Round 4 打断了序列
这些常见错误本质上都是对收敛判断的误用——用不相邻的轮次、或单轮的结果来断言收敛。
为什么不用更多轮
如果两轮确认比一轮好,三轮是不是更好?
理论上是的。但审核有成本——每轮审核消耗 token 和时间。两轮确认在实践中的误判率已经足够低。Coroutine-O 的 Round 2 完全干净,Bridge Plugin 的 6 轮审核中后 2 轮连续零问题——两个案例都支持两轮确认的有效性。
这和工程实践中的"两次独立验证"原则一致:密码学用两个独立随机源确认随机性[4],航空航天用两个独立传感器确认状态[5]。两次独立确认足以将误判率降到可接受的水平,三次的边际收益不值得边际成本。
一个完整的管线数据
上面用 Coroutine-O 的合并审核展示了单次收敛。下面是另一个项目(一个 Python 数据回填服务[6])完整走完 tdd-pipeline 五个阶段的审核数据:
审核方说明:Oracle 和 Council 是 OMO-Slim(oh-my-opencode 的轻量版)插件提供的两种 agent 角色。Oracle 是单一 AI 审查者,职责是深度代码审查、架构分析和问题发现——相当于一位资深架构师做 CR。Council 是多模型共识机制,同时调用多个 AI 模型独立审查同一份交付物,综合各方意见后输出共识报告——用于架构决策等需要多视角验证的场景。
| 产出物 | 审核方 | 轮次 | 结果 |
|---|---|---|---|
| 产品设计 v2.0 | Oracle | 12 轮 | ✅ 通过 |
| 技术方案 v1.1 | Oracle + Council | 5 轮 | ✅ 通过 |
| 测试方案 v1.2 | Oracle | 4 轮 | ✅ 通过 |
| 测试代码 | Oracle | 2 轮(早停) | ✅ 通过 |
| 实现代码 | Oracle | 2 轮(早停) | ✅ 通过 |
最终验证:1,219 个测试全部通过,Pyright 类型检查零错误。
两个观察:
- 轮次递减是管线的典型模式。 产品设计需要 12 轮,因为需求阶段的不确定性最高——“做什么"的边界在审核中才逐渐清晰。到测试代码和实现代码阶段,范围已经锁死,审核只需 2 轮(早停)。至少在这个项目里,需求阶段的发散和代码阶段的收敛形成了明显对比。越早的阶段越需要多轮审核。
- 技术方案引入了 Council 机制——多个 AI 模型并行审查、综合意见,作为单一审查者的补充。架构决策涉及多维度权衡(性能、安全、可维护性),单一视角可能遗漏。
核心洞察:审核是另一个 AI 的工作
这个系列从第一篇到第四篇,逐步建立了一套流程:PRD 锁定"做什么”,技术方案锁定"怎么做",测试方案锁定"怎么验证",Ralph Loop 锁定"怎么确认没出错"。
但 Ralph Loop 有一个隐含前提:审查者是另一个 AI,不是人类。
人类在这个流程里的角色是决策者,不是审查者。人类决定做什么(PRD 审批),决定怎么算通过(验收标准),决定遇到 Max Rounds 时怎么处理(上报)。但逐行审查代码、逐条验证事实声明的工作,应该交给独立的 AI subagent。
这不是因为 AI 审查比人类更可靠。而是因为 AI 审查的注意力不衰减——第 100 行和第 1 行的审查强度相同。人类的注意力在第 10 行就开始衰减了。对于一个有几十个事实声明的技术方案,这个差异是决定性的。
Ralph Loop 的本质是:用 AI 的无限注意力弥补人类的有限注意力,用独立审查弥补自我审查的确认偏误,用双重确认弥补单轮审查的假阳性风险。
参考
- tdd-pipeline 项目:github.com/alexwwang/tdd-pipeline ralph-review-loop.md
- Coroutine-O 合并开发日志:Aristotle 仓库 分支提交历史及内部文档
- 柯西收敛准则:Rudin, W. Principles of Mathematical Analysis, 3rd ed., McGraw-Hill, 1976, Theorem 3.11.
- 独立熵源组合:NIST SP 800-90B, Recommendation for the Entropy Sources Used for Random Bit Generation, Section 6.3.
- 双传感器冗余:RTCA DO-178C, Software Considerations in Airborne Systems and Equipment Certification, Section 6.4.
- Python 数据回填服务项目:内部项目,审核数据来自 CI 构建日志。
Aristotle 项目在 GitHub 开源,MIT 协议。欢迎提交 Issue 和 PR。