这是"用 TDD 驯服 AI 编码代理"系列的第三篇。前两篇分别讲了测试层的需求锚定和需求层的 GEAR 消歧协议。本篇补中间一环——PRD 做完之后,技术方案该做什么。
需求锁死了,代码还是错了
第二次重构 Aristotle 之前,我花了整整两天写需求文档。参考前一篇的结构化需求写法,把每条验收标准、边界条件、错误路径、平台约束全写清楚了[1]。AI 拿到这份文档,37 个静态断言全部通过,E2E 测试一路绿灯。代码按职责拆成了四个文件,信息流从推送改成了拉取。
需要说明一下"看起来没问题"的精确含义。第一篇提到第二次重构"解决了上下文污染和审核断裂的问题"[2],这是相对于第一版的 371 行 SKILL.md 而言——第二版把上下文负载从 371 行降到 84 行,污染大幅减轻。但"减轻"不是"归零"。84 行仍然被注入主 session,异步后台机制仍然没有按设计工作。
装完跑了一遍,发现反思功能仍然没有实现需求描述的能力。
需求写得够清楚——“反思任务必须在独立后台 session 执行,主 session 不能被污染”。AI 也"理解"了这条需求。它调用了 OpenCode 的 task(run_in_background=true) API,把反思任务放进了子进程。
但根因是前期没有做技术调研,没有人在动手前验证过:“OpenCode 的 task() 异步机制到底怎么工作?”
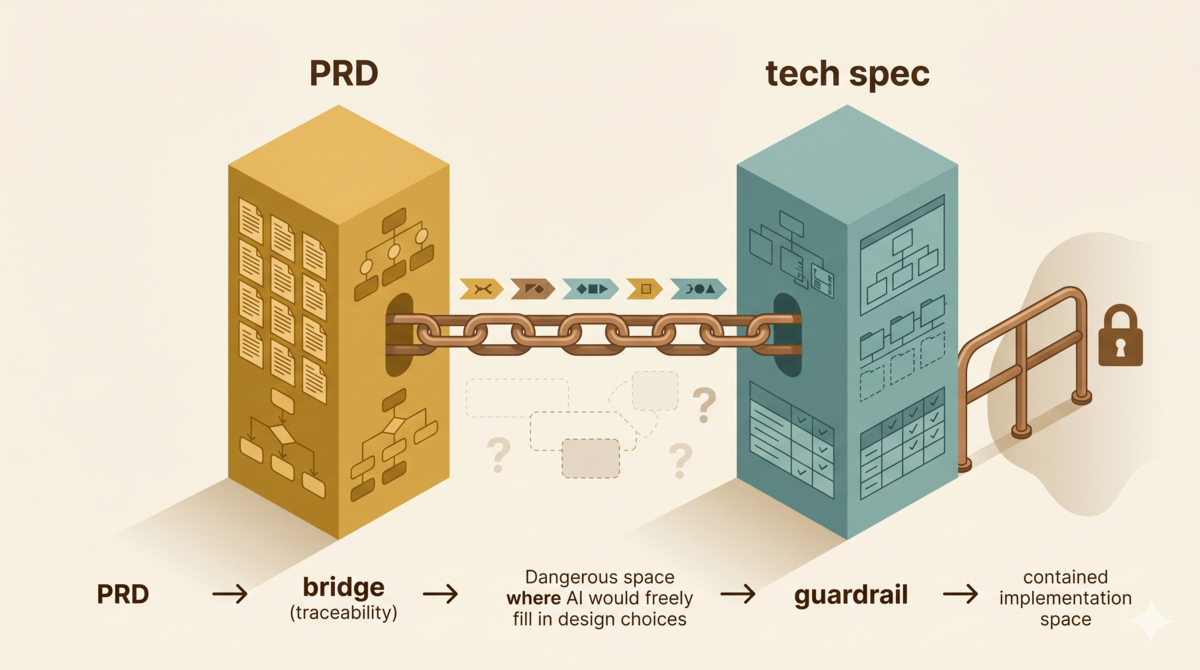
需求层做得再好,也只回答了"做什么"。回答不了"怎么做"。
PRD 该写什么
PRD 的职责是定义用户可观察的行为边界——用户做了什么,系统该有什么反应,边界在哪里,错了怎么办。
tdd-pipeline 项目的 Phase 1 交付物包含 User Stories(含 Priority)、Acceptance Criteria(含 Edge Cases 列)、Constraints & Assumptions[3]。本文为了讲解方便,将 Edge Cases 和 Priority 拆成独立部分,重新组织为以下五个方面:
一、User Stories
描述谁要做什么、为什么做。格式:As a <role>, I want <goal> so that <benefit>。
以 Aristotle 反思功能为例:
| # | Priority | User Story |
|---|---|---|
| US-1 | Core | As a user, I want to trigger error reflection with a single command so that past mistakes inform future sessions |
| US-2 | Core | As a user, I want the main session to remain usable during reflection so that I can continue working |
| US-3 | Secondary | As a user, I want to review generated rules before they take effect so that I maintain control |
二、Acceptance Criteria
把每条 User Story 展开成可测试的 Given-When-Then。二值的——过就是过,不过就是不过,没有"基本通过"。
US-2(主 session 保持可用)展开成验收标准:
| # | User Story | Priority | Acceptance Criterion | Edge Cases |
|---|---|---|---|---|
| AC-1 | US-2 | Core | Given 反思任务已启动, When 用户发送新消息, Then 主 session 正常响应且不包含反思输出 | 反思任务进行中用户再次触发反思 |
| AC-2 | US-2 | Core | Given 反思任务已完成, When 系统通知用户, Then 通知内容不超过 200 字 | 反思任务失败时的通知内容 |
三、Edge Cases & Error Scenarios
AC-2 的 Edge Case 已经标注了"反思任务失败时"。正式的 PRD 会把每条验收标准的边界情况展开成独立条目:
- 反思 session 创建失败 → 显示错误提示,引导重试
- 规则生成超时 → 保存草稿,通知用户后续处理
- 用户在同一轮对话中多次纠正 → 只触发一次反思
- 对话历史为空 → 不触发反思
四、Constraints & Assumptions
声明已知的限制和假设:
- OpenCode 的
task()创建的子 session 是非交互式的——审核不能在子 session 中进行 - 反思完成后只能通知用户,不能把完整输出推回主 session——信息流必须是拉取模式
- 当前不支持 Claude Code 环境
五、Priority Classification
每条 User Story 和 Acceptance Criterion 标记为 core 或 secondary。core 是必须有的,secondary 是锦上添花。这个分类在后续阶段会驱动测试深度——core 的测试覆盖 happy path + edge cases + error scenarios,secondary 只需基本覆盖。
这五个方面回答的都是"做什么“和”为什么做"。它们让任何读文档的人都能判断"这个功能做对了还是做错了"。
但它们不回答"怎么做"。
PRD 做对了,但还不够
第二次重构的 PRD 确实按这个结构写了。验收标准里明确写了"主 session 零污染"“异步非阻塞”。边界条件和平台约束也写了。
但 coroutine-O 分支——Aristotle 的异步编排原型——暴露了 PRD 的边界。
coroutine-O 的目标是实现非阻塞的反思工作流:用户触发 /aristotle 后,主 session 立即返回,反思任务在后台执行。PRD 里写得够清楚——“主 session 零污染"“异步非阻塞”。AI 拿到需求,直接开工。
问题是:PRD 只写了"做什么”,没有写"怎么做"。AI 需要回答一个关键的设计问题:后台任务用什么机制实现?
AI 从训练数据里找到了最常见的答案:调用 task(run_in_background=true)。这个参数在训练数据里出现过无数次,是最直接的实现路径。AI 没有追问:“OpenCode 的 task() API 是否真的支持 run_in_background?”
后来的平台调研发现:OpenCode 的 task() 根本没有 run_in_background 这个参数。当前版本的 task() 是同步阻塞的——父 agent 会等待子 agent 完成,不会立即返回。PRD 里的"非阻塞"在这个方案下根本无法实现。
coroutine-O 分支最终被清理,但它留下了一个清晰的教训:
PRD 锁定的是"做什么",不是"怎么做"。 需求文档再精确,也替代不了技术方案文档。AI 会基于训练数据填补设计空白——如果技术方案里没有写明"后台任务用什么机制实现",AI 会默认选择训练数据里最常见的方案,即使这个方案在当前平台不存在。
技术方案该写什么
技术方案的职责是回答"怎么做"。它承接 PRD 的每个验收标准,输出可执行的工程决策。
tdd-pipeline 的 Phase 2 交付模板包含 Architecture Overview、Component Breakdown、Data Models / API Contracts、Key Decisions、Failure Mode Handling、Non-functional Constraints、Observability Design、Cost Estimation、Priority Downgrade Justifications 和 Open Technical Questions 共十个部分[3]。本文从中选取了与 AI 辅助开发最相关的核心部分,按必要性排序。
一、Architecture Overview(不可跳过)
描述组件边界和数据流。不需要精美的架构图,ASCII 图就够用。关键是让读者(包括 AI)在动手前就知道系统由哪些部分组成、信息怎么流动。
Aristotle 反思流程的时序图:
用户 ──纠正──→ 主 Session
│
├──→ O(路由器)
│ │
│ ├──→ 触发反思请求
│ │
│ ←─── 返回"已提交"(不等待结果)
│
独立 Session ←─── 反思任务(后台执行)
│
├──→ R 生成规则(REFLECTOR.md)
│
├──→ C 审核规则(REVIEW.md)
│
└──→ Git commit 规则
用户 ←──通知─── 主 Session(拉取结果)
这张图解决了一个关键问题:信息流是拉取模式。第一版和第二版都破坏了这个设计——第一版是全量拉回,第二版是 AI 假设回调通知可用。
二、Component Breakdown(不可跳过)
把 Architecture Overview 拆成具体的组件,每个组件有明确的职责、接口和依赖。
| Component | Priority | Responsibilities | Serves ACs | Dependencies |
|---|---|---|---|---|
| O (Router) | Key | 解析命令,路由到对应流程 | AC-1, AC-2 | MCP tools |
| Bridge Plugin | Key | 异步任务执行,R→C 链式驱动 | AC-1, AC-2 | promptAsync, idle events |
| MCP Server | Key | 规则生命周期管理,状态机 | AC-1 | Git, YAML frontmatter |
注意"Serves ACs"这一列——每个组件必须能追溯到 PRD 的验收标准。这是 PRD 和技术方案之间的映射关系。
三、Key Decisions(不可跳过)
记录每个关键决策的选型理由和排除的替代方案。
| Decision | Rationale | Alternatives Rejected |
|---|---|---|
| Bridge Plugin + promptAsync 实现异步 | 真正的异步非阻塞,主 session 零参与 | task():同步阻塞,run_in_background 参数不存在 |
coroutine-O 的教训直接体现在这行里。如果第二次重构的技术方案写了这行,AI 就不会默认选择 task() 方案。
平台调研不是可选项。每个涉及平台 API 的决策都必须经过验证:查官方文档确认参数和行为,写最小脚本测试关键假设,把结论记录在表格里。这三步把"我认为可行"变成"我验证过可行"。
四、Failure Mode Handling(不可跳过)
列出可能的失败场景和设计响应。
| Failure Scenario | Priority | Design Response |
|---|---|---|
| 子 session 创建失败 | Key | 主 session 内执行,标记"降级模式" |
| 规则生成超时 | Key | 保存草稿,通知用户后续处理 |
| Git 仓库未初始化 | Peripheral | 启动时自动检测并初始化 |
PRD 的 Error Scenarios 列了"反思任务失败怎么办"。技术方案把这条展开成具体的设计响应——用什么机制保存草稿,通知走什么渠道,降级模式的表现是什么。
五、Non-functional Constraints(视项目复杂度)
并发、可逆性、数据隔离、资源边界等非功能性需求。简单项目可以跳过,但涉及多进程、数据持久化、外部 API 的项目必须写。
Aristotle 的关键约束:
| Dimension | Requirement |
|---|---|
| Concurrency | 反思任务不阻塞主 session,多个反思任务不可并行 |
| Data isolation | 规则仓库通过 Git 隔离,消费者通过快照读获取稳态版本 |
| Operation reversibility | 所有 verified 规则可通过 git revert 回退 |
六、Observability(视项目复杂度)
健康指标、日志策略、告警条件。Aristotle 目前不需要——规则仓库的 Git history 就是天然的审计日志。
七、Cost Estimation(视项目复杂度)
基础设施、第三方服务、开发开销的估算。Aristotle 的成本是零——纯本地运行,没有外部依赖。
这些部分里,前四个是任何 AI 辅助项目都不可跳过的。后几个视项目复杂度决定。但有一个原则不变:技术方案的每个设计决策都必须能追溯到 PRD 的某条验收标准。 没有溯源的设计决策,就是 AI 自由发挥的空间。
从 PRD 到技术方案:映射逻辑
PRD 和技术方案不是独立的。它们之间存在双向可追溯的映射关系。
PRD: 反思任务在独立后台 session 执行(AC-1)
↓
技术方案:
Component: Bridge Plugin (Key) → Serves AC-1
Decision: promptAsync 实现异步 → Rationale: task() 不支持
Failure: 子 session 创建失败 → 降级模式
↓
测试方案:
验证进程隔离是否生效
验证主 session 上下文是否被污染
验证降级模式是否按设计执行
这个映射关系就是需求追溯矩阵(RTM)[4]的核心要求。测试方案中的每个测试用例,既能追溯到 PRD 的验收标准,也能追溯到技术方案的设计决策。
没有可追溯的映射,AI 在实现阶段会自由地"优化"设计——把方案 A 改成方案 B,把拉取改成推送——因为它看不到设计决策和验收标准之间的约束关系。RTM 把这层约束显性化了。
核心洞察:文档是给 AI 的约束空间
这个系列反复提到一个观点:AI 不会追问。需求模糊时它不追问,设计缺失时它也不追问。它会直接按训练数据里的最常见模式填空。
PRD 缩小了"做什么"的填空空间。技术方案缩小了"怎么做"的填空空间。两者叠加,AI 的自由发挥空间被压缩到只剩实现细节——这才是人类可以容忍的范围。
这个机制缩小了错误空间,但没有消灭它。技术方案本身也是假设的集合——如果方案里包含错误假设,AI 会忠实地执行一个错误的设计。coroutine-O 的教训就是:AI 和我一起假设了一个不存在的 API 参数。
既然方案里的假设可能出错,谁来发现?靠一个人逐条核实——Aristotle 这个规模的项目,技术方案里少说有十几个事实性声明——既不可靠也不可持续。PRD 可能写错,技术方案的调研结论可能过时,测试方案可能漏了边界条件。每一层都可能引入错误,而人类没有精力逐层检查。
需要的是一种结构化的审核机制:不是靠一个人从头看到尾,而是让另一个 AI 从不同角度独立审查,找到事实性错误、逻辑漏洞和遗漏的边界条件。审查结果必须是可操作的——不是"建议改进",而是具体的"第 X 行的声明与官方文档不符"。
下一篇讲 Ralph Loop:一个多轮审核机制,用独立的 AI subagent 审查每个阶段的交付物,拦截系统性偏差。
参考
- 结构化需求写法:为什么 AI 辅助开发必须从 GEAR 协议开始 第 3 节"需求文档该怎么写"
- 两次重构经历:先写测试文档,再写测试代码:AI 开发的需求锚定 第 1 节"前传:两次翻车,第三次才学会走路"
- tdd-pipeline 项目:github.com/alexwwang/tdd-pipeline Phase 1 (phase-1-product-design.md) 和 Phase 2 (phase-2-technical-solution.md)
- ISO/IEC/IEEE 29148:2018, Systems and software engineering — Life cycle processes — Requirements engineering.
- Aristotle 项目仓库:github.com/alexwwang/aristotle
Aristotle 项目在 GitHub 开源,MIT 协议。欢迎提交 Issue 和 PR。