三篇文章之后,再次回到代码,今天要做一个深刻的反思。
第一篇 Aristotle:让 AI 学会从错误中反思 讲了设计理念和顺利的实现过程——3 个 commit 一气呵成。第二篇 claude-code-reflect:同样的元认知,落在不同的土壤 讲了同样理念搬到 Claude Code 上的适配代价——从 V1 到 V3 的持续迭代。第三篇 信任边界:同一个想法在开放系统和受限系统上的实现实验 提出了信任分层模型和驾驭工程的思考框架。
第三篇给了理论框架。这篇文章回到代码——用 Aristotle 的改造过程,验证这些理论在实际工程中如何落地。
一、从"顺利"到"伤疤"
初版 Aristotle 的实现过程确实顺利。只用了 3 个 commit,从完整的 SKILL.md 到测试脚本到 README,一气呵成。不是因为问题简单,而是 OpenCode 的基础设施把最难的部分解决了。
第一篇里,我信誓旦旦地写了三条设计原则。第二条是“会话完全隔离”——“反思过程在后台的子会话里进行,主会话的上下文零污染,不会影响当前任务”。还说“整个过程对用户透明,不会打断工作流”。
实际使用后,我发现这两句话一句都没兑现。
- 主会话的上下文根本不是零污染。
/aristotle触发时,SKILL.md 全部 371 行被注入父 session。反思本应是"隔离的元认知",但启动反思这件事本身就占了主 session 大量 token。 - 子进程完成后,
background_output(full_session=true)又把整份 RCA 报告拉回父 session——错误分类、根因链条、建议规则全部涌入工作上下文。本来是为了让 AI 认识自己的局限,结果认识的过程本身干扰了正常工作。 task()创建的子 agent session 是非交互式的——这是 OpenCode 的架构限制——但初版假设用户能切入子 agent 的 session 做审核确认,实际上用户只能另开终端手动操作。审核流程在实践中断裂了。- 过程也完全不是透明的。启动前弹一个模型选择对话框,消耗一轮对话。
承诺 VS 现实:
| 第一篇的承诺 | 实际行为 |
|---|---|
| 主会话上下文零污染 | 大量污染上下文:SKILL.md 371 行全量注入 + RCA 报告全量拉回 |
| 整个过程对用户透明 | 上来就要用户选择:模型选择弹窗消耗一轮对话 |
| 不会打断工作流 | 严重打断用户当前工作流:结果直接写入了主 session,即便另开终端审核,因为开的是子 session,根本无法审核,流程是断的 |
为什么设计和实现之间有这么大的差距?
根因是过度信任了自动化测试的结果,所以没有人工测。37 个静态断言加上 E2E live test 验证了协议步骤能按顺序执行——Coordinator 启动 Reflector、Reflector 读取 session、生成 DRAFT。但测试验证的是"协议有没有正确执行",不是"协议的副作用是否可接受"。测试不会告诉你主 session 被占了 371 行的上下文空间,也不会告诉你用户需要另开终端才能审核。测试给了通过的假象,让我以为设计原则落地了,实际上原则在实现的第一步就被违反了。
一语成谶:“当工具足够流畅,人类会自然地把 review 当成可选项”。自动测试通过给了我同样的流畅感——“协议跑通了”——让我觉得不用人工测了,于是跳过了对副作用的审视,直到自己去用。
找到了问题根因后,改造方向自然清晰。初版的设计原则本身没有错——隔离、透明、低摩擦——但实现没有守住这些原则。改造要做的不是推翻设计,而是用代码结构把设计原则锁定,让违反原则的行为在结构上不可能发生。
从四个问题到一套架构
四个问题表面上各自独立,但分析后发现它们指向同一个结构性缺陷:初版的设计使用一个 agent skill,没有区分"协调者"和"执行者"的角色及它们的职责边界。
上下文污染的本质是:协调者本不需要知道执行者的完整协议,但初版因为只有一个 agent 角色,因此它把反思的所有任务都塞进同一个 skill 文件里,并在执行时将它们全部披露进了主 session 的上下文。
报告泄漏的本质是:协调者本不需要看到执行者的完整输出,但初版只有一个 agent,于是它把输出也发回了主 session。
审核断裂的本质是:执行者不应该负责审核——它是非交互式的——但初版却实现成了用户在执行者的 session 里审核,只是把反思的过程放进了子 agent 的 session,因为初版只设计了一个 agent 角色。
注意力浪费的本质是:协调者的启动流程应该零交互,但初版在启动时使用了弹对话框的方案,因为我没有细想这个交互问题,过度信任了模型和提示词提供的设计能力。
这一版的改造涉及一个关键的调研:审核断裂的调查。通过查阅 OpenCode 源码和数据库实证,确认了 task() 创建的 session 是架构性非交互式的——47 个 task session 全部只有 1 条 user message,还是 system prompt,所有都没有后续交互,从 OpenCode 在 GitHub 上的 Issues #4422、#16303、#11012 也确认了这一点。
这意味着审核不能在子 agent session 中进行,必须在主 session 中实现,原先设想的实现要推翻,但原则要坚持,怎么做?是给 OpenCode 提 issue,等他们实现子 session 支持用户交互?还是改自己的设计?答案显然是后者。
从这条约束出发,自然想到一个问题:如果用户审核在 workflow 中不可避免,又不能在子 session 中进行,那起一个主 session 专门做这个事情行不行?那么如果审核在主 session 中,主 session 需要知道有哪些反思记录——这就是 aristotle-state.json 状态追踪文件的由来。需要加载某条记录的 DRAFT 报告——这就是 /aristotle review N 命令。需要处理确认、修订、拒绝——这就是交互式审核流程。
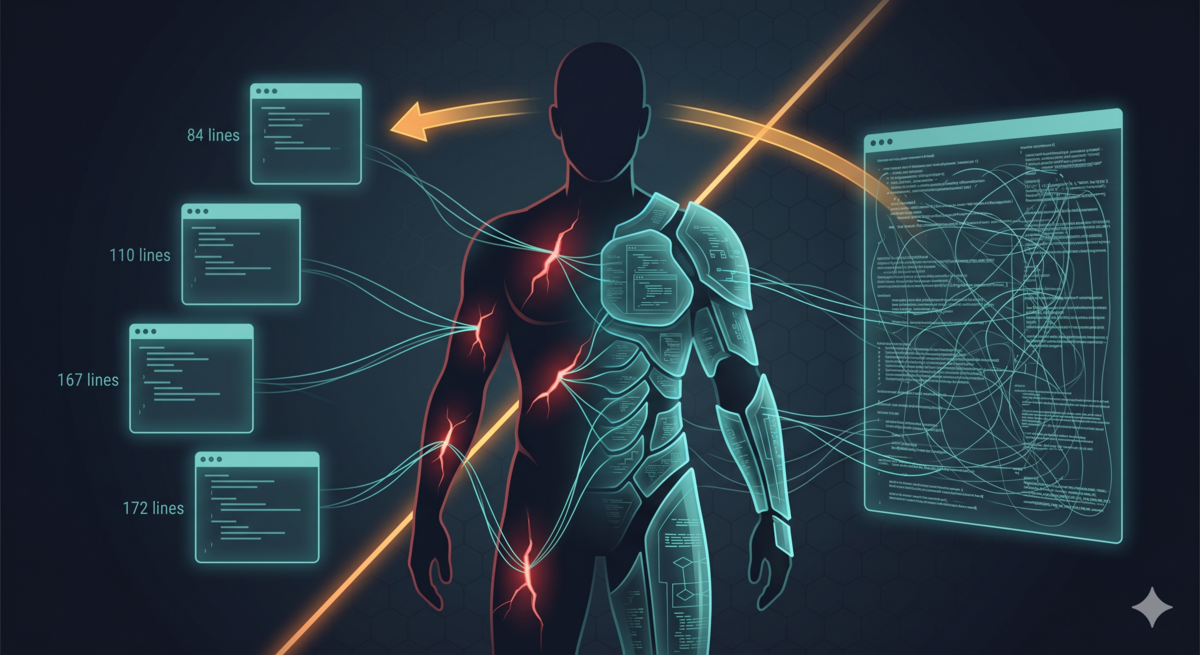
进一步,既然审核协议和启动协议只在不同场景被使用。初版把它们放在同一个 371 行的文件里是否有必要?两种场景需要加载相同内容吗?按职责拆分后:路由逻辑留在 SKILL.md(84 行),启动反思的逻辑在 REFLECT.md(110 行),审核的逻辑在 REVIEW.md(167 行),子 agent 的分析协议在 REFLECTOR.md(172 行)。每个文件只在一个场景被加载,上下文占用显著减少,主 session 的上下文污染问题也减少到最低。
拆分之后,SKILL.md 只剩路由逻辑。但初版在启动前有一个模型选择弹窗,消耗一轮对话。既然启动反思只需要加载 REFLECT.md(+110 行),弹窗完全多余。删除弹窗,改为命令行参数 --model。默认使用当前会话模型,高级用户通过参数覆盖。启动反思从两步操作变成一步操作。
最后是信息流。初版的 background_output(full_session=true) 把子 agent 的完整分析拉回主 session。改造后彻底删除这个调用。子 agent 完成后,主 session 只输出一行通知。用户需要审核时,通过 /aristotle review N 主动拉取 DRAFT 报告。信息流从"子 agent 全量推送到主 session"变成"子 agent 写状态文件、用户主动拉取"。
整个推演过程可以提炼成三条原则:
- 从约束推导架构,而不是从理想流程推导。先确认平台能做什么(task session 非交互式),再设计流程。
- 按职责拆分,按场景加载。每个文件对应一个清晰的职责,每个场景只加载它需要的文件。
- 把用户放在主动位置。通知而非推送,拉取而非注入,命令行参数而非弹窗。
二、第一道约束:上下文边界——从 371 行到 84 行
做法直接:把 SKILL.md 从 371 行的单一大文件拆成 4 个按需加载的文件。
| 场景 | 加载文件 | 行数 |
|---|---|---|
| 命令路由 | SKILL.md | 84 |
| 启动反思 | SKILL.md + REFLECT.md | 194 |
| 审核规则 | SKILL.md + REVIEW.md | 251 |
| 子 agent 分析 | REFLECTOR.md | 172 |
启动 /aristotle 时只加载 84 行的路由文件,完整的分析协议只传给子 agent 。主 session 的上下文从一开始就被保护了。
实现上,Coordinator 通过 SKILL_DIR 环境变量把 REFLECTOR.md 的路径传给子 agent,不内联完整协议。子 agent 收到 prompt 后自行 Read 文件。
初版的问题在于主 session 和子 agent 之间没有上下文边界——子 agent 的协议被无条件注入主 session 的上下文。修复后,每个场景只加载它需要的最小信息。像请外部审计师来查账——审计师需要看所有账本,但你不需要把审计师的工作底稿全部摊在自己的办公桌上。你需要的是结论,不是过程中每一页草稿。反思是事后行为,不应该干扰现场补救措施的执行。
git commit 39dffae 完成了这次重构。371 行到 84 行,77% 的削减。功能没有减少——反而增加了(--focus 参数、状态追踪、跨 session 联合反思、已写入规则的修订)。
三、第二道约束:信息流向——单向完成通知
直接删掉 background_output() 调用。子 agent 完成后,父 session 只输出一行通知:
🦉 Aristotle done [current]. Review: /aristotle review N
父 session 不再取回任何分析内容。审核通过 /aristotle review N 在专门的审核主 session 中进行——此时加载 REVIEW.md(167 行),读取 DRAFT 报告,呈现给用户确认。
信息流从双向变成了严格单向:子 agent → 状态文件 → 用户主动拉取。
DRAFT 标记意味着"待验证"。用户必须亲眼看到、手动确认,规则才落盘。第三篇提出过信任 Level 0 的问题:“此刻这个模型的 RCA 质量能支撑多大的授权?"——答案是不能全自动写入。
另一个考虑:子 agent 完成时触发 completion notification,如果主 session 正在处理用户的其他请求,分析报告涌入会干扰当前工作。单向通知 + 用户主动拉取,是把信息流控制权交给用户。
有意思的是,写到这里我发现,claude-code-reflect 的 /reflect review 是被迫的(平台限制),而 Aristotle 的 /aristotle review N 是主动选择——即使 OpenCode 没有限制了,经过思考我还是会选择这样设计(起一个专职主 session 来审批 DRAFT),而非最初的每个子 session 单独拉起。
下面说说OpenCode上这个设计如何实现,挺有意思。
四、第三道约束:架构现实——审核从子 agent 回到主 session
这是最波折的一个问题。
问题本质是 OpenCode 的 task() 创建的 session 是非交互式的——Github 的 issues 和数据库实证都确认了这一点。初版假设的"用户切入子 session 审核"流程在实践中不可行。
解决路径不是绕过限制(像 claude-code-reflect 那样用 bypassPermissions),而是承认限制并重新设计流程:
- 子 agent 只做分析和生成 DRAFT,不处理用户交互
- 利用 OpenCode 的开放和信任,把审核放在主 session 中通过
/aristotle review N拉起 - 引入
~/.config/opencode/aristotle-state.json状态追踪文件,管理反思记录的生命周期 - 引入多次反思的功能,通过序列号区分,通过
/aristotle sessions查找需要再反思的错误场景(现实中我们也会时不时回忆起自己犯过的一些错误,不是么?)
状态流转:draft → confirmed → revised(允许 re-reflect 重新分析)
子 agent 做分析、主 session 做审核和写入——这个职责分离不是被迫的妥协。OpenCode 的 task session 非交互式限制,表面上是平台约束,实际上恰好是一个健康的架构边界:执行子任务的 agent 应该保持独立的上下文而不被主 session 干涉。
对比第二篇的 claude-code-reflect:在 Claude Code 上,这个职责分离是通过 V2→V3 迭代中"把写入移到 resumed session"来实现的,绕了很多弯路。在 OpenCode 上,平台的架构限制恰好引导出了正确的职责分离。
一个更深的观察:平台对开发者的信任程度,和用户对 AI 的信任程度,有时候方向一致,有时候方向相反。 Aristotle 的场景里方向一致——OpenCode 的开放性让你把职责分离做得更干净,而信任 Level 0 的设计要求恰好需要这种干净。
五、第四道约束:用户注意力的最小化消耗
解决过程最简单,但原则最清晰。
删除 question 工具弹窗,改为命令行参数:/aristotle --model sonnet。不指定则默认使用当前会话模型。
这是一个小改动,但背后的原则不小:反思的启动应该是低门槛的。每增加一步交互,用户启动反思的概率就降低一分。模型选择是为了适应不同场景的高级需求,有必要提供给用户,但不应作为默认流程的一部分,因此将其配置前置到启动环节,而非启动后再多问一次(现实中我们也总是更喜欢和能把情况提前说清楚而非走一步问一步的人合作)。
初版用交互式弹窗——每一次都依赖用户做选择。改为命令行参数后,“不弹窗"是结构保证的,默认不依赖用户的判断。
六、四道约束合在一起:Progressive Disclosure 架构
四个修复不是孤立的,合在一起就是 Progressive Disclosure(渐进式披露)。
最终的架构图:
Reflect Phase Review Phase
───────────── ────────────
/aristotle /aristotle review 1
│ │
├─ Load REFLECT.md ├─ Load REVIEW.md
│ (110 lines) │ (167 lines)
│ │
├─ Fire Reflector ──────► ├─ Read Reflector session
│ (background task) DRAFT │ Extract DRAFT report
│ ──────► │
├─ Update state file ├─ Present DRAFT to user
├─ One-line notification ├─ Handle confirm/revise/reject
└─ STOP ├─ Write rules on confirm
└─ Re-reflect if requested
371 行到 84 行,77% 的削减。功能没有减少——反而增加了(--focus 参数、状态追踪、跨 session 联合反思、已写入规则的修订)。
最终由 4 个文件构成:
- SKILL.md(84 行)— 路由层,参数解析和 phase 分发
- REFLECT.md(110 行)— 反思阶段协议,启动子 agent 和状态追踪
- REVIEW.md(167 行)— 审核阶段协议,DRAFT 审阅、规则写入、修订
- REFLECTOR.md(172 行)— 子 agent 分析协议,错误分析、DRAFT 生成
测试断言也从 37 个扩展到 63 个,覆盖了文件结构、progressive disclosure、SKILL.md 内容、hook 逻辑、错误模式检测(中英文)、以及架构保证。
这套架构的每一层都是信任判断的产物:
- 文件拆分:不信任父 session 能承受子 agent 的完整上下文冲击而不出问题
- 单向通知:不信任用户当下能立刻处理来自子 agent 的异步信息
- 主 session 审核:不信任子 agent session 能恰当处理用户交互——也不应该信任
- 默认不弹窗:不信任用户的注意力是无限的
但"不信任"在这里不是负面判断,而是精确的信任校准——每个组件被信任做它最擅长的事,不被信任做超出它能力范围的事。像一支交响乐队——不是不信任圆号手能拉小提琴,而是每个声部守好自己的谱子。该你独奏时给你完整的分谱(REFLECTOR.md 172 行),不该你发声时你只需要知道下一首要演什么(SKILL.md 84 行)。没有人需要看总谱。
七、回到系列原点:信任驱动的设计取舍
第三篇提出了驾驭工程的思考框架:“在用户、工具和大模型三者之间,让信任关系驱动架构决策,而不是反过来。“第四篇用 Aristotle 的改造验证了这个框架。
从两个项目的完整经历看信任曲线:
| 阶段 | 信任判断 | 代码体现 |
|---|---|---|
| 初版 Aristotle | 隐式信任——没考虑边界 | 371行全量注入、报告全量取回 |
| 发现问题 | 信任校准——意识到边界缺失 | 承诺与现实对比,四个架构级缺陷暴露 |
| 改造 Aristotle | 主动约束——用代码结构锁定边界 | Progressive Disclosure |
| claude-code-reflect | 条件信任——平台限制倒逼主动设计 | bypassPermissions、resumed session |
两种约束殊途同归:最终都收敛到"子 agent 做分析、主 session 做审核、用户做审批"的职责分离。区别在于,OpenCode 上你有机会主动选择正确的约束,Claude Code 上你不得不在平台限制下寻找变通方案。
一个开放问题:随着模型能力提升,Aristotle 的 DRAFT 报告质量会逐渐提高。当信任从 Level 0 后移到 Level 1-2 时,Progressive Disclosure 架构需要改变吗?
答案可能是否——即使子 agent 的输出质量足够高,上下文隔离仍然是有价值的。信任的是输出质量,不信任的是异步信息涌入对主 session 的干扰。这两个信任维度是独立的。
结语
四道伤疤变成了一套铠甲。不是每道伤疤都能变成铠甲——有些问题需要平台层面的支持,比如子 agent session 的交互式能力、自动通知机制。有些约束在当前架构下只能缓解不能消除。
但当信任判断能转化为代码结构时,伤疤就是铠甲的原材料。Progressive Disclosure 不是为了炫耀架构技巧,而是为了把信任关系固化成可验证的代码约束。主 session 和子 agent 之间的边界、单向信息流、主 session 审核、默认不弹窗——每一道约束都是一个信任判断的具象化。
Aristotle 和 claude-code-reflect 不是"哪个更好"的关系,它们是同一条信任曲线上的两个点,是互相启发共同迭代的孪生子。真正的问题从来不是"要不要 human-in-the-loop”,而是:此刻这个模型在这个环境中处理这个任务上的可靠程度,能支持多大的授权?
随着模型能力提升,这个答案会变。checkpoint 会后移,自动化程度会提高,review 频率会降低。但判断"现在可以后移了"这件事本身,永远是人的责任。
Aristotle 项目地址:https://github.com/alexwwang/aristotle