上一篇文章 从四道伤疤到一套铠甲:Aristotle 改造中的驾驭工程实践 的结尾处,Aristotle 有了一份精简的路由器(SKILL.md 从 371 行压缩到 84 行),一个按需加载的 Progressive Disclosure 架构,和一个还算能用的反思→审核→确认流程。
但有一条暗线一直没有展开:确认之后的规则,到底存在哪里?
这篇文章就讲这条线。它不是一开始就规划好的,而是在实际使用中,被三个具体的问题一步步逼出来的设计。
一、Append-Only 的困境
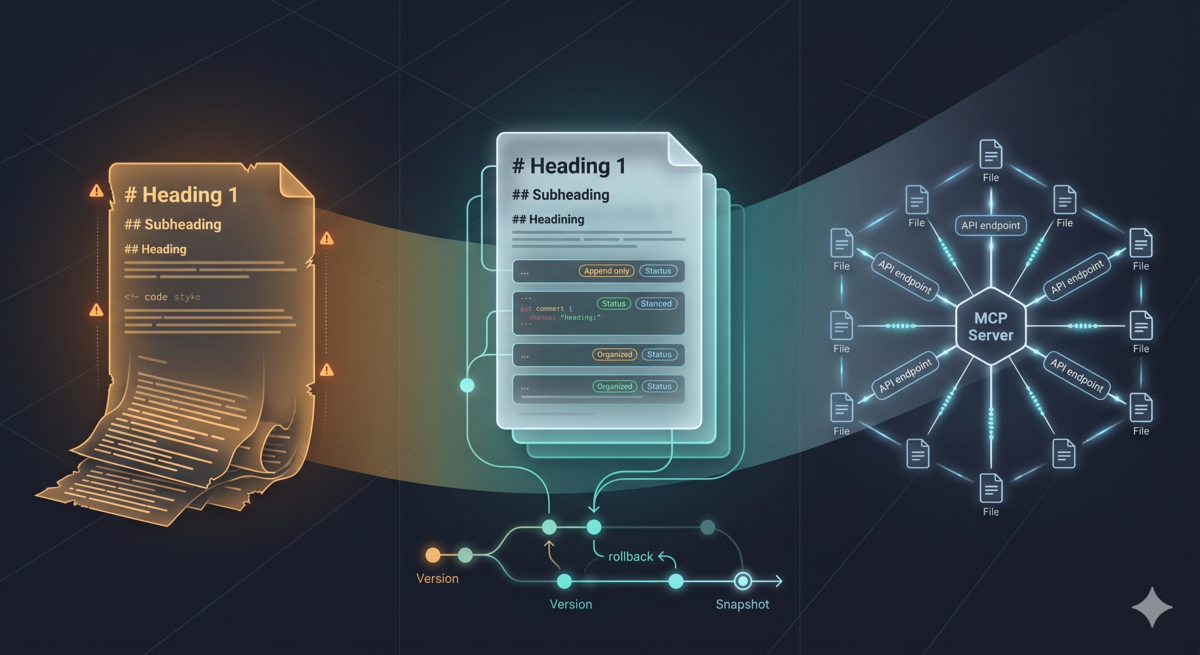
Aristotle 的反思结果最终要写入一条规则——一段 Markdown 文本,告诉未来的 AI session “遇到这类情况时该怎么做”。最初的实现简单粗暴:所有规则追加到 ~/.config/opencode/aristotle-learnings.md,一份文件,不断 append。
这个方案能用。但用了两周之后,三个问题浮出水面。
问题一:规则无法回滚
有一天 AI 生成的规则说"pandas 的 groupby 结果必须用 .reset_index() 处理才能正常序列化"——这条规则本身没错,但触发条件写得太宽,导致后续在做简单聚合分析时也强制加了 reset_index(),反而破坏了多层索引的结构。它被确认写入后,后续的每个 session 都在读到这条规则——直到我手动打开文件,找到那条规则,删掉它。
这不是"删一行"那么简单。在 Markdown 混合文本中找到特定规则需要肉眼扫描。删错了,没有 git history 可以恢复。规则是不可变的——一旦写入,它就一直在那里,直到你手动干涉。
问题二:项目级规则散落各处,没有统一管理
初版设计确实区分了用户级和项目级——用户级规则存 ~/.config/opencode/aristotle-learnings.md,项目级规则存各项目目录下的 .opencode/aristotle-project-learnings.md。两级文件分开的思路是对的。
但分开了之后,各自的困境一模一样——都是 append-only,都没有版本管理。更尴尬的是,项目级规则散落在各处。当我在十个项目里各自积累了五条教训,这五十条规则分布在十个不同目录下,检索和管理成了噩梦。想查"之前哪个项目踩过数据泄露的坑",得挨个目录翻文件。
问题三:规则之间没有结构
几十条规则平铺在 Markdown 文件里,每条就是一个标题加几行正文。没有分类标签,没有置信度,没有"这条规则是怎么来的"。当我想找"所有和数据清洗相关的教训"时,只能全文搜索关键词——而 AI 生成规则时用的措辞,和我搜索时用的措辞经常不一样。比如规则里写的是"空值处理遗漏",我搜的是"缺失值",两者匹配不上。
三个问题的共同根源:扁平的 append-only 文件,承载不了"有状态的知识管理"这个需求。 即使用户级和项目级分开了,没有版本管理、没有结构化元数据、没有统一的检索入口,分离只是物理上的隔离,没有带来真正的治理能力。
二、为什么是 Git?四个决策点
改进方向的第一反应并非 Git。但代码是文本,规则也是文本——为什么规则不能像代码一样有版本管理呢?
但"直觉上合适"和"经得起推演"是两回事。在和 AI 的反复讨论中,Git 的引入经历了四个关键的决策点。每一个解决的都是多 agent 协作中的物理确定性问题。
决策一:版本回退——“后悔药”
如果 agent B 在审核 agent A 产出的规则时产生了幻觉或逻辑错误,把文件改坏了怎么办?如果我们自己写版本管理——比如每次修改前备份 .bak 文件——复杂度会迅速失控:备份的备份怎么管?多版本之间怎么 diff?
Git 是全球最成熟的"后悔药"系统。git revert 或 git checkout 可以秒级回退到任意历史版本,零额外成本。
决策二:读写冲突的物理隔离
当一个 agent 正在写入规则文件时,另一个 agent 尝试读取,可能读到"写了一半"的残缺内容。这在单机单进程的软件中不是问题,但在多个 AI session 并行运行的环境中是真实风险。
Git 的暂存区(Index)和提交历史(Commit History)天然提供了逻辑隔离。写操作在磁盘上进行,读操作通过 git show HEAD:file 直接从 Git 的对象库中读取上一个稳态版本。这种**快照读(Snapshot Read)**彻底终结了读写冲突——读者和写者看到的永远是不同版本。
决策三:从"修改文件"到"提交事务"
简单的文件状态标记(在文本里写 status: pending)并不可靠。物理状态和逻辑状态可能脱节——文件存在磁盘上,但状态位是错的;或者状态位是对的,但文件内容被意外覆盖了。
我们需要把"修改文件"和"生效文件"变成两个独立的动作。git commit 本质上是一个原子化的事务(Transaction)。只有执行了 commit,这条规则才算在系统中"正式上线"。没被 commit 的,一律视为不可信。这为消费者提供了一个绝对可靠的边界。
决策四:轻量与透明
评估过 SQLite。数据库在查询能力上更强,但有两个致命缺点:一是不可见——你无法直接用文本编辑器打开数据库看规则内容,调试和审计成本高;二是部署成本——需要额外的运行时依赖。
Git 是基于文件的。你可以直接打开文件夹看 .md 内容,同时获得数据库级别的版本控制能力。这种"看得见、摸得着"的透明性,对于一个调试频繁的早期系统至关重要。
四个决策的共同结论
选择 Git,实际上是将版本控制、物理隔离、事务机制、审计溯源这四个工程难题,通过一个轻量的现有工具一并解决了,而这个工具又是用户必备的。
在 Git 提供的这块"安全底座"上,后续的原子写入、状态机、读写分离等设计才有基础。
三、Git-backed 文件系统的设计细节
原子写入
规则文件写入磁盘时采用"临时文件 + 重命名"策略——先写到一个 .tmp 文件,写完再 os.rename() 替换原文件。这保证了两个性质:
- 其他进程(包括同时运行的 AI session)永远不会读到"写了一半"的文件。
- 即使写入过程中崩溃,原文件不受影响。
听起来像过度工程?其实不是。AI agent 经常在多个 session 中并行运行。如果 session A 正在写规则文件,session B 恰好同时在读,没有原子写入的保证,B 可能读到残缺内容,然后基于残缺内容做决策。这不是理论上的风险,而是在实际使用中会遇到的问题,在数据库的写入场景很常见,这也是数据库写入使用锁的原因。考虑到反思内容写入文件的尺寸会更大,而同个反思文件的更新频率并不会很高,因此出于轻量和非阻塞的缘故,我没有选择锁的策略。
状态机
规则不再只有一个"已写入"状态,而是有了完整的生命周期:
pending → staging → verified
↘ rejected(可恢复)
pending:规则刚生成,还没经过审核。文件存在磁盘上,但没有进入 Git。staging:审核者正在检查。这一步把规则"锁"住,防止在生产者审核过程中被修改。verified:审核通过,执行git add && commit。这是终态——消费者只能看到这个状态的规则。rejected:审核失败。但不是删除,而是移到rejected/目录,保留所有元数据,未来可以恢复。
为什么 rejected 规则要保留而不是直接删?因为我发现,有些被拒绝的规则不是"完全错误",而是"在特定场景下不适用"。保留它们,未来可以通过 restore 重新激活,而不是从零开始重新生成。
读写分离
消费者(未来的 Agent L)读取规则时,不直接读磁盘上的文件,而是通过 git show HEAD:file 读取 Git 提交的快照。这意味着消费者永远只看到 verified 状态的规则,永远不会读到生产者写了一半的草稿。
读写分离是一个关键设计决策。它解决的不是性能问题,而是信任问题——消费者不需要信任磁盘上的文件状态,只需要信任 Git 提交历史。Git commit 的原子性,成了生产者和消费者之间的契约。
冷启动
第一次运行时,系统检测到旧的 aristotle-learnings.md 文件,自动执行迁移:解析旧的 Markdown 格式,为每条规则生成 YAML frontmatter(包含状态、分类、置信度等字段),写入 Git 仓库。迁移完成后,旧文件重命名为 .bak 备份。
迁移不是"把旧文件切开分份"那么简单。旧规则没有结构化元数据,需要启发式推断——从 Markdown 标题中解析错误分类,从段落中提取规则摘要。推断不一定准确,所以迁移时默认置信度设为 0.7(保守值),verified_by 标记为 "migration",方便后续人工复核。
这些设计思路来自和 AI 的反复讨论。我前后保存了 9 份讨论记录,从最初的"Git-MCP 技能管理方案"到最终收敛为"GEAR 协议规范",一步步迭代,每一步都记录了当时的问题、设计的决策以及这么选择的理由。
四、为什么是 MCP Server?
有了设计思路,下一步是实现。一个关键的技术选型问题:这些 Git 操作应该在哪里执行?
最直接的方案是在 SKILL.md 里写 bash 命令——让 AI agent 自己调用 git add 和 git commit。但我很快排除了这个选项,原因有三:
可靠性。AI 生成的 git 命令可能有拼写错误、路径错误、甚至破坏性操作(比如误
git reset --hard)。规则仓库是用户的长期知识积累,一个错误的 git 命令可以毁掉全部历史。一致性。每条规则写入时都要执行相同的状态检查、frontmatter 格式化、原子写入流程。把这些逻辑放在 prompt 里让 AI 自己执行,一致性无法保证——模型有时会"创造性"地跳过某些步骤。
可测试性。prompt 里描述的流程很难自动化测试。
这三个原因也体现了任务的特性:这是确定性极强的标准动作,可以使用程序实现逻辑,并通过测试用例保证质量,覆盖从初始化到迁移到生命周期管理的每个节点。把这些操作包装成标准化的工具,让 AI 按需调用,这是确定性更高、更稳妥的选择。
于是 MCP(Model Context Protocol)登场了:一个独立的 Python 进程,通过 stdio JSON-RPC 与 AI agent 通信。Agent 不直接执行 git 命令,而是调用 MCP 提供的工具实现目的,几轮迭代之后,已经定义了 8 个这样的工具:
| 工具 | 对应操作 | 作用 |
|---|---|---|
init_repo | 初始化 | 创建目录结构、Git 仓库、迁移旧规则 |
write_rule | 生产 | 创建规则文件(pending 状态),写入 YAML frontmatter |
read_rules | 检索 | 多维度组合查询(状态、分类、意图标签、错误摘要) |
stage_rule | 审核 | 标记规则进入 staging 状态 |
commit_rule | 确认 | 状态设为 verified,执行 git add && commit |
reject_rule | 拒绝 | 移入 rejected/ 目录,保留元数据 |
restore_rule | 恢复 | 从 rejected/ 还原到正式目录 |
list_rules | 列表 | 轻量元数据查询(不加载规则正文) |
每个工具都是一个确定的 Python 函数,有输入校验、有错误处理、有测试覆盖。AI agent 通过调用这些工具来操作规则仓库,但永远无法绕过工具直接执行 git 命令。
MCP Server 不是给 AI 更多能力,而是给 AI 的能力加上边界。 这和第四篇讨论的信任校准是一脉相承的设计哲学:不是不信任 AI,而是通过结构化接口把"可能出错的地方"收窄到可预测的范围内。
五、检索维度:怎么找到"相关的"规则?
MCP Server 有了,规则有了生命周期,有了 Git 版本管理。但还有一个问题:当 AI 开始一个新任务时,怎么知道哪些规则和当前任务相关?
最初的实现只支持按状态(verified)和分类(HALLUCINATION 等 8 种)过滤。但实际使用中发现,同一个分类下的规则可能涵盖完全不同的技术场景——“HALLUCINATION” 既可以指"编造了一个不存在的 API 方法",也可以指"错误地声称某个配置项不存在"。分类太粗,不够用。直接使用大模型按语义比较吗?这样 MCP 的工具太重了,也丢失了 MCP 中工具的确定性。因此我决定查询过滤只使用正则匹配,而将语义的比较转化为关键词的查询。
经过思考,我在查询设计中引入了三个检索维度:
- 意图标签(intent_tags):规则适用的技术领域(
domain)和具体目标(task_goal)。比如domain: "database_operations",task_goal: "connection_pool_management"。 - 失败技能(failed_skill):出错的工具或技能。比如
failed_skill: "prisma_client"。 - 错误摘要(error_summary):一句话描述错误现场。比如
"P2024 connection pool timeout in serverless"。
这三个维度是 AI 生成规则时自动填写的。生成时加一步推断——从错误的上下文中推断技术领域,从用户的原始请求推断任务目标,从涉及的代码推断出错的工具。
检索时可以组合使用:查"所有数据库操作相关"的规则,或者更精确地查"连接池管理 + 涉及超时"的规则。500 条规则,Phase 1 的 frontmatter 过滤只需 80ms。
流式过滤
实现检索时有一个工程细节值得提。read_rules 工具采用两阶段搜索:
Phase 1:只读每个文件的前 50 行(YAML frontmatter 通常在前 20 行内结束),用正则匹配 frontmatter 中的 KV 对。不匹配的文件直接跳过,不做 YAML 解析。
Phase 2:对 Phase 1 命中的文件,才做完整的 frontmatter 解析和规则正文加载。
为什么要分两阶段?因为 YAML 解析比正则匹配慢一个数量级。500 条规则如果全部做 YAML 解析,检索延迟会从 80ms 飙到接近 1 秒。两阶段设计把"确定不需要的文件"尽早排除,只在必要的地方付出解析成本。(不过未来是不是本地能积累到500条规则,我现在并不清楚)
六、S:把意图翻译成查询
有了三个检索维度,下一个问题是:谁来把"我要做数据库迁移"这种自然语言,翻译成 MCP 的查询参数?
回答看起来显而易见——为了不污染上下文,反正不能让 L 做。进一步,自然的想法是:放到 Agent O 里吧,让它同时负责路由、意图提取、查询构造。但是这样会不会导致SKILL.md上下文爆炸呢?尤其是查询构造的部分要调用 MCP 服务获得反思结果,这样的话会返回大量的内容。
所以再次用到了渐进式披露的思想(其实我认为它和程序设计里的解耦是同一个概念在不同场景的表述),查询构造被提取为一个独立的关注点,命名为 S(Searcher)。S 的输入是意图标签(domain: "database_operations", task_goal: "schema_migration"),输出是 read_rules() 的参数字典。S 做的事很具体:
- 如果有
domain,设intent_domain参数。 - 如果有
task_goal,设intent_task_goal参数。 - 如果有
failed_skill,设failed_skill参数。 - 如果有错误描述,从中提取 2-3 个关键词,用
|连接作为keyword参数。 - 所有参数 AND 组合,调用
read_rules()。
S 不做语义理解,不做模糊匹配——它是一个确定性的参数构造函数。
这里有一个刻意的设计选择:S 在设计方案中拥有独立的角色身份,但在当前实现中只是 O 内部的一个函数调用。 不是矛盾,是分阶段策略。目前查询构造足够简单,不值得启动一个独立 subagent 来做。但未来如果需要语义检索(向量匹配)、跨仓库联合查询、或查询结果缓存,S 的复杂度会显著增加。协议层面的角色身份,预留了从函数升级为独立进程的演进路径。
先轻量实现,协议层预留—— 整个项目的设计哲学保持一致。
但 S 只是检索链路的一环。S 返回的结果可能是 20 条规则——如果全部丢给正在执行用户任务的 agent,那 20 条规则的完整正文会直接填满上下文窗口,主线任务的空间被挤占。
这引出了一个更深层的设计问题:谁站在 L 和反思基础设施之间,做过滤和压缩?
因此先用 O 来接,如果未来遇到上下文爆炸的问题,这里还可以再拆出一个 Agent 处理过滤的任务,从而控制住每个任务的上下文长度,这是利用工具链的思维控制单个节点的复杂度,而上下文长度是 Agent 任务复杂度的直观度量。分阶段实现不影响架构原则——下一节会说明,O 居间不是权宜之计,而是学习链路的架构必需。
七、O 的角色延展:从路由器到知识服务提供者
O(Orchestrator)在 Aristotle 最初的设计里只是一个路由器——用户输入 /aristotle,O 解析参数,决定启动反思还是审核,然后交棒。
但到了学习链路,O 的角色发生了质变。它不再只是分发任务,而是变成了一道隔离层。
L 和 O 不是同一个 agent
这里有一个我(和帮我做设计的 AI)都踩过的坑。
Aristotle 的历史实现中,O、R、C 的角色曾都在同一个主会话上下文中完成——加载 SKILL.md 变成 O,加载 REFLECT.md 启动反思,加载 REVIEW.md 做审核。全部在同一条 agent 进程里。
所以当设计学习链路时,AI 自然地假设 L 也是同一个 agent——“L 直连 S 就行了,O 是不必要的中间人”。它还用了 CQRS 做类比:命令走协调者,查询直接取,天经地义。
我纠正了这个判断。
L 是正在帮用户写代码的那个 agent,O 是 Aristotle 这个独立的反思 skill。它们运行在不同的上下文中。L 的上下文应该尽可能留给用户的主线任务——反思基础设施的任何细节(MCP、frontmatter、查询构造)都不应进入 L 的上下文。
这个区分在 P1+P2 阶段不重要,因为反思和审核本身就是用户主动发起的操作,占用主会话上下文是合理的。但到了学习链路,L 在执行用户的主线任务——此时任何反思基础设施对 L 上下文的侵入,都是污染,而只有那个帮助解决当下任务遇到问题的反思规则才是 L 需要的。
O 居间的三件事
O 在学习链路中做三件 L 不应该做的事:
1. 意图提取。 L 说"我要做数据库迁移,之前踩过坑吗?"——O 从这句话中推断 domain: "database_operations", task_goal: "schema_migration"。L 不需要知道什么是 intent_tags。
2. 查询构造和执行。 O 调用 S 函数,构造 MCP 查询参数,调用 read_rules(),获取原始结果。这些是反思基础设施的内部操作,对 L 不可见。
3. 过滤和压缩。 S 可能返回 20 条规则。O 做去重、按相关性排序、最多保留 5 条,然后把每条规则压缩成 3-4 行摘要——错误描述、避坑要点、正反例、规则 ID。L 只看到这个精炼后的摘要。
L 的视角很简单:问了一个问题,收到几条教训。不知道 MCP,不知道 read_rules,不知道 frontmatter。这是最小污染。
一次有价值的犯错
值得提一句的是,那个"O 是不必要中间人"的错误判断,后来被 Aristotle 自己的反思机制做了一次 5-Why 根因分析。根因结论很有意思:
对"间接层"有默认的负面判断——认为每多一层协调就是不必要复杂度。这个判断在一般软件设计中通常是合理的,但在 Aristotle 的场景下是错误的。Aristotle 的间接层不是开销,它是产品本身。整个 skill 的存在意义就是让反思基础设施对主线 agent 不可见。去掉间接层等于去掉产品价值。
AI 在设计反思系统时犯了错误,反思系统反思了这个错误,生成了一条预防规则。有点套娃,但确实是这个系统设计的初衷——从错误中学习,哪怕是设计者自己的错误。
八、角色分离:O、R、C、S、L 各司其职
有了 S 和 O 的延展设计,五个角色的完整图景就清晰了:
| 角色 | 目标 | 追求 |
|---|---|---|
| O(Orchestrator) | 统筹 + 隔离 | 路由正确、上下文最小污染 |
| R(Resource Creator) | 生产规则 | 召回率——宁可多生成,不遗漏 |
| C(Checker) | 审核规则 | 精确率——格式、逻辑、去重 |
| S(Searcher) | 意图→查询 | 确定性翻译,不做猜测 |
| L(Learner) | 消费规则 | 执行主线任务 + 规避已知陷阱 |
R 和 C 的职责有本质区别——R 追求覆盖面,C 追求准确率。把它们混在一起,两个目标会互相干扰。角色分离不是为了"分工",而是为了目标隔离。
更直白地说:R 是自动化的 agent,它产出的内容可能存在逻辑错误甚至幻觉。如果 R 生成的规则不经审核直接进入生产环境——被 L 当作"必须遵守的教训"——一条错误规则就会污染后续所有 session 的决策。这不是假设,是我在实际使用中遇到过的:R 把一条触发条件过宽的规则直接写入后,L 在后续任务中误用了它,产生了新的错误。规则仓库的影响力是全局的,一条坏规则的破坏力远大于一条好规则的收益。
C 的存在就是为了阻断这个风险。C 是系统中唯一拥有 git commit 权限的角色——R 只管写,C 才能放行。R 生产的规则必须经过 C 的 schema 校验、格式检查、和去重验证,才能变成 verified 状态被 L 看到。这个"生产-审计"的两步流程,本质上就是软件工程中的 Code Review——不是不信任开发者,而是单视角的盲区需要另一个视角来补。
L 和 R/C 之间没有直接通信,只通过 Git 仓库间接交互。O 是唯一的协调者——L 向 O 发请求,O 向 L 返回摘要。L 不知道 R 和 C 的存在。
R 只管写,C 只管审,L 只管学,O 居间协调,S 做翻译。读写分离保证了 L 永远不会读到 R 写了一半的草稿。这种隔离不是过度设计——第四篇讨论的 Progressive Disclosure 架构,本质上就是角色分离的一种实现形式。
九、从实现到协议:GEAR
到这一步,Aristotle 有了一个完整的规则管理系统:Git-backed 存储、YAML frontmatter schema、状态机、多维度检索、角色分离。
在整理文档时,我意识到这些设计不局限于 Aristotle——任何需要"从错误中学习并跨 session 持久化知识"的 AI agent 都面临同样的问题。于是把核心设计抽象成了一个独立的协议规范,命名为 GEAR(Git-backed Error Analysis & Reflection)。
GEAR 定义了五个角色(O/R/C/L/S)、一套状态机、一个 frontmatter schema、和一个 Δ 决策因子。Aristotle 是 GEAR 的第一个实现——O 由 SKILL.md + REFLECT.md + REVIEW.md 实现,R 由 REFLECTOR.md 实现,C 由 REVIEW.md 中的 schema 校验实现。L 和 S 尚在计划中。
Δ 决策因子
Δ 因子目前仅停留在协议设计层面,Aristotle 尚未实现。以下为前瞻性说明——当前所有规则仍走固定的 semi 模式。
GEAR 中有一个机制还在设计中——Δ 决策因子:
Δ = confidence × (1 − risk_weight)
它决定了规则从 staging 到 verified 的路径:
| Δ 值 | 审核行为 |
|---|---|
| Δ > 0.7 | auto:自动 commit,不需要人工确认 |
| 0.4 < Δ ≤ 0.7 | semi:展示 diff,等待用户确认 |
| Δ ≤ 0.4 | manual:强制人工审核 |
risk_weight 由错误分类决定——幻觉(HALLUCINATION)权重 0.8,语法错误(SYNTAX_API_ERROR)权重 0.2。高风险规则需要更多审查,低风险规则可以更快速通过。
目前 Aristotle 固定使用 semi 模式——所有规则都经过用户确认。这是因为系统还在积累数据,成功率统计不够充分,还不具备自动升降审核级别的条件。等 P4 阶段实现 evolution_stats.json 后,Δ 因子才能真正落地。
Δ 因子的设计思路借鉴了渐进式信任模型——不是一刀切地信任或不信任 AI 的规则,而是根据置信度和风险权重动态调节审核门槛。和第四篇讨论的"信任校准"一脉相承,也是为了让用户可以量化“偷懒”的风险。
十、当前状态和下一步
GEAR 协议的实现目前完成了 P1 和 P2(前两个阶段):
- P1(MCP 基础设施):8 个工具、YAML frontmatter schema、多维度检索、原子写入、冷启动迁移。75 个 pytest 测试全部通过。
- P2(Aristotle Skill 层集成):REVIEW.md 改造为 MCP 工具调用链、REFLECTOR.md 输出协议扩展、C 角色 schema 校验。
尚未实现的:
- P3(Learner + Searcher):让 AI 在任务开始前自动检索相关规则。这是 GEAR 自愈闭环的关键——从"人工触发反思"进化为"自动学习避坑"。
- P4(进化模型):Δ 决策因子的实际接入,以及审核级别的自动升降。
- P5(文档收尾)。
回顾这条设计路径:从一份 append-only 的 Markdown 文件,到 Git-backed 文件系统,到 MCP Server,到 GEAR 协议。每一步都不是提前规划好的,而是被实际使用中遇到的具体问题逼出来的。
规则无法回滚 → 引入 Git。读写互相干扰 → 引入读写分离和状态机。AI 直接执行 git 命令不可靠 → 引入 MCP Server。规则之间没有结构 → 引入 YAML frontmatter 和检索维度。生产和审核目标冲突 → 引入角色分离。设计可以复用 → 抽象为 GEAR 协议。
每一步解决一个具体问题。而串联起来,这条路径指向了一个终极目标——自愈闭环:
L 执行任务 → O 通过 S 检索相关规则 → L 学习后仍犯错
→ 向 O 提交错误报告 → O 拉起 R 生成新规则
→ C 审核 → verified → 下次 L 通过 S 检索到更新后的规则
每一次失败都创造新的知识,每一次新的知识都减少同类失败的概率。闭环不是从第一天就设计出来的,但每一步迭代都在为它铺垫——Git 给了版本管理,MCP 给了结构化接口,检索维度给了精准匹配,角色分离给了信任边界,O 的居间给了上下文隔离。所有这些加在一起,闭环才跑得通。
不是在系统设计之初就把所有可能的需求都考虑进去,而是在使用中发现问题,在解决问题中提炼抽象。 这是驾驭工程的核心方法——在最小的可用方案上迭代,让每一次迭代都解决一个真实的问题,最终发现闭环已经在脚下。
附录:GEAR 协议的 Conformance 要求
一个声称符合 GEAR 的系统必须满足以下条件:
- 角色分离。生产(R)、审核(C)、消费(L)由不同的 agent 或进程处理。同一 agent 不能同时对同一条规则执行两个角色。
- Git-backed 存储。所有
verified规则必须通过 git commit 进入仓库。消费者通过git show HEAD:或等价机制读取。 - 状态机强制。规则只能通过
pending → staging → verified或rejected的路径转换,不允许跳步。 - Frontmatter schema。每条规则必须包含 YAML frontmatter,至少有
id、status、scope、category、confidence、risk_level、intent_tags、created_at字段。 - 意图驱动检索。系统必须支持按
intent_tags.domain和intent_tags.task_goal检索规则。 - Rejected 规则保留。被拒绝的规则保留原始元数据,可以通过
restore操作恢复。 - 原子写入。规则文件通过"写临时文件 + 重命名"的方式写入,不允许出现部分写入。
参考链接
- Aristotle 项目仓库:github.com/alexwwang/aristotle
- GEAR 协议规范(项目内
GEAR.md文件,当前在git-mcp分支) - 上一篇 从四道伤疤到一套铠甲:Aristotle 改造中的驾驭工程实践
Aristotle 项目在 GitHub 开源,MIT 协议。欢迎提交 Issue 和 PR。