Fundamentum autem est iustitiae fides, id est dictorum conventorumque constantia et veritas.
— Cicero, De Officiis
正义的基石是信——言辞与约定的始终如一与真实。
前两篇讲了两个项目的故事。Aristotle:让 AI 学会从错误中反思 跑在 OpenCode 上,3 个 commit 一气呵成。claude-code-reflect:同样的元认知,落在不同的土壤 跑在 Claude Code 上,从 V1 迭代到 V3,踩了一路坑。
两个项目解决同一个问题——让 AI agent 从错误中学习,把纠正经验转化为持久规则。但实现过程让我意识到,这背后有一个比技术选型更重要的问题:我们应该在什么时候信任 AI 的判断,又在什么时候需要插手?
这个问题不只适用于"用户信任 AI"这一层。平台对开发者的信任程度,同样决定了你能给 AI 多大的自主权。两层信任叠加在一起,才是这一系列实验真正在探索的东西。
两个项目的简明对比
核心逻辑相同:检测纠正信号 → 启动 subagent 做 5-Why 根因分析 → 生成防范规则 → 用户确认后写入持久化记忆 → 下一个 session 自动加载。但落在不同平台上,实现姿态截然不同:
| 维度 | Aristotle(OpenCode) | claude-code-reflect(Claude Code) |
|---|---|---|
| 系统原语 | task()、session_read() 完全透明,路径可知 | 接口不透明,session_read() 在某些 model/provider 组合下拿不到 |
| 权限模型 | 开发者有完整系统访问权,skill 能做的事就是系统能做的事的上限 | 技能系统是沙盒,bypassPermissions 是被迫选择——auto 模式的 safety classifier 在 background session 里可能不可用,直接卡死 |
| 并发控制 | task() 是原子操作,subagent 启动不会被打断 | 准备阶段多步独立调用可被用户请求穿插,需合并为单条 Bash 命令才安全 |
| 状态管理 | 系统内置通知机制 | 靠 state.json + 用户手动 resume session |
| 实现耗时 | 3 个 commit | V1→V2→V3,持续迭代 |
信任的分层模型
一个转折
当我把两个实现放在一起比较时,我以为自己会得出"OpenCode 更好"的结论。
但仔细想,这个判断过于简单了。
claude-code-reflect 里 human-in-the-loop 的设计——用户必须主动跑 /reflect review,亲眼看到 RCA 报告,手动确认才写入记忆——这不只是绕不开系统限制的妥协。它是对一个真实问题的主动回答:
你现在对这个模型的根因分析有多少信任?
如果 Reflector 的 RCA 质量不够稳定,全自动写入记忆会带来系统性风险:错误的防范规则被自动加载,悄悄影响后续几十个 session,而你对此完全无感。发现问题的时候,污染已经发生了。
一个来自人类协作的类比
这个互相拉扯的两难困境在人类组织里有一个古老的对应问题:授权的边界在哪里?
新员工入职第一天,每一个决策都需要 review,每一行代码都要 code review 才能合并。不是因为他没能力,而是因为双方还没有建立足够的信任基础,万一出错,纠偏成本也相对可控。
工作了两年,有了稳定的 track record,授权范围自然扩大:独立负责模块,只有跨团队影响的决策才需要对齐。
资深员工更进一步:日常工作完全自主,只需要做好可审计的留痕,接受不定期的随机抽查。
授权的程度,跟对这个人工作质量的了解程度成正比。checkpoint 随着信任的积累逐渐后移,从"每次都看"变成"定期抽查",最终变成"只检查最终结果"。
把这个逻辑套用到 AI Agent
我们现在处于人机协作的早期——大概相当于"新员工入职第一周"。
对应的信任模型应该是这样的:
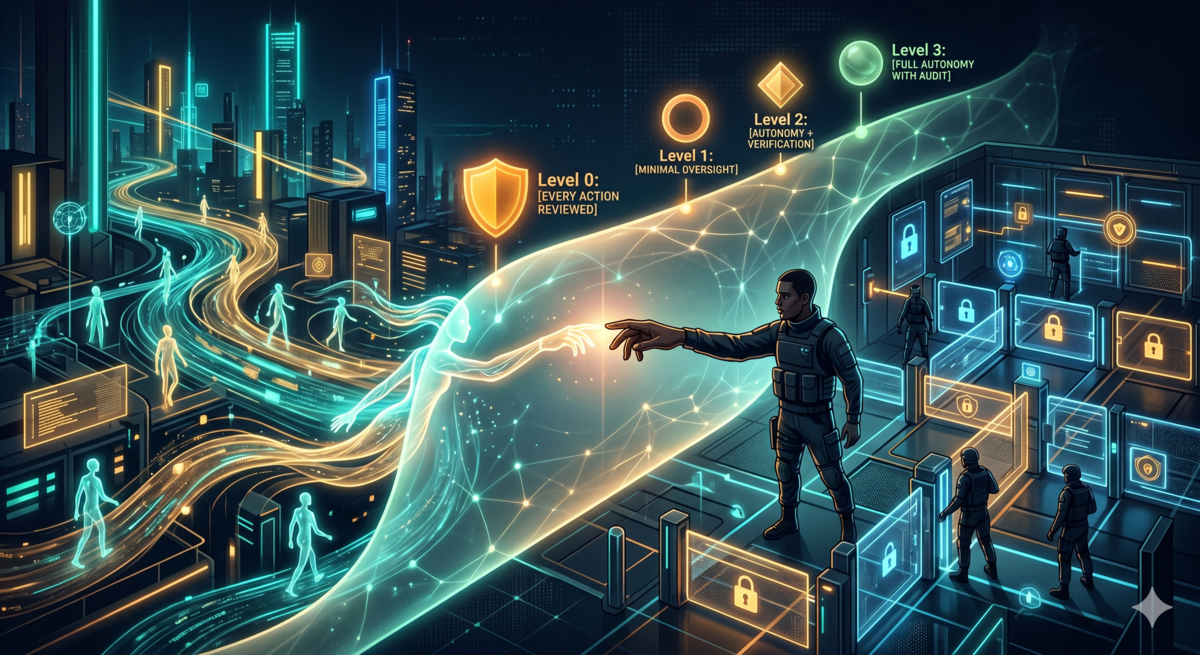
Level 0(当下): 每次 RCA 都要 human review 才能写入记忆。用户亲眼确认每一条防范规则。这是 claude-code-reflect 现在的设计。
Level 1: RCA 自动写入,标记为"待验证"。每周批量 review 一次,确认或撤销。
Level 2: 高置信度的 RCA 直接归档,低置信度的进入 review 队列。用户定期随机抽查高置信度的归档。
Level 3: 全自动,审计日志完整保留,随机抽查作为质量兜底。
Aristotle(OpenCode 版本)在实现上更接近 Level 2-3,这不是问题,这是它在开放系统上能做到的事。但它是否应该这样运行,取决于你对模型 RCA 质量的实际信任程度。
一个诚实的承认
我在 Aristotle 上跑了自动化测试,全程没有人工干预。测试脚本验证了 Coordinator 能正确启动 Reflector,验证了 session ID 被正确传递——然后就结束了,打印出"如需查看分析结果,请运行 opencode -s <id>"。
那个 review 步骤,我没有做。
我当时的理由是"claude-code-reflect 还没完成,精力有限"。但这个行为本身,恰好印证了那个论点:当工具足够流畅,人类会自然地把 review 当成可选项,即便系统设计上它是必须的。
这不是批评,这是一个关于人机协作的真实观察。信任边界会在实践中悄悄漂移,跑得快的工具会比跑得慢的工具更容易让人降低警惕。
设计哲学——谁信任谁
用户信任 AI,这只是一半。平台对开发者的信任有多少,决定了前者的表达空间——这是独立的一层。
OpenCode 把你当开发者
OpenCode 是完全开源的。task() 用来启动 subagent,session_read() 用来读取会话内容,memory 文件的读写路径完全透明。系统能做什么,skill 就能做什么。复杂度完全花在了问题本身——如何做根因分析,如何分类错误,如何生成有用的防范规则。
Aristotle 的流程因此非常清晰:用户触发 → Coordinator 收集元数据 → Reflector 在隔离的 subagent 里做分析 → 生成规则 → 用户确认 → 写入。没有惊喜,没有暗坑。
Claude Code 把你当用户
Claude Code 是闭源商业产品。技能系统是 Anthropic 在认为安全的范围内给你的一个沙盒——你能做的事,取决于 Anthropic 决定暴露哪些接口。
实现同样的流程,复杂度花在了和系统边界博弈上。bypassPermissions 是被迫的选择——理想情况下 background subagent 应该用 auto 权限模式,但 auto 模式依赖一个内部的 safety classifier 来判断每个工具调用的安全性,这个 classifier 需要交互式会话来展示权限对话框并接收用户决策。而 background session 是运行在非交互模式下的,classifier 无法完成决策回路,于是 subagent 的所有工具调用被卡死。我只能用 bypassPermissions,然后在 prompt 层面手写路径限制来补偿。并发控制没有系统原语支持,准备阶段的多步操作可以被用户请求穿插打断。状态管理靠文件系统模拟,通知靠用户手动 resume session。
Known Issues 列表诚实地记录了这些问题——UUID 碰撞、跨 compaction 通知丢失、错误恢复不完整……每一条都是在系统边界上打补丁留下的痕迹。
两层信任的交汇
表面上看,这是"开源 vs 闭源"的老话题。但实际观察比标签复杂得多。
用户信任 AI 是第一层:我对模型的根因分析有多少信心,决定了 RCA 结果是全自动写入还是需要人工审批。这个信任不只是理论上的——在开发 claude-code-reflect 的过程中,我遇到一系列技术问题,特地和 Sonnet 4.6 做了深度对话来分析原因。但具体到项目实现,我认为 glm-5.1 完全能胜任,就用它来推进。这也是信任在发挥作用:我对不同模型在不同任务上的能力判断,直接影响了工作分配。
平台信任用户 是第二层:平台给了我多大的操作空间,决定了第一层信任能表达到什么程度。在和 Sonnet 4.6 的对话中,我意识到在 Claude Code 上踩的那些坑,底层原因其实不是模型不够聪明,也不是我的设计有问题——而是"平台对用户的信任有多少"这件事从一开始就决定了你能走多远。
两层叠加:OpenCode 的高信任(对开发者)让我可以靠近 Level 2-3,Claude Code 的低信任(对开发者)把我推回 Level 0-1。不是哪个"更好",而是此刻各自的信任基础不同。
但问题比这更深一层。平台对开发者的低信任,不一定是傲慢——它可能恰恰来自平台对模型能力的清醒判断。如果你认为当前模型的 RCA 还不够稳定,那把开发者限制在 Level 0-1 就不是在阻碍创新,而是在防止系统性风险。Claude Code 的沙盒设计,和 claude-code-reflect 的 human-in-the-loop 设计,背后是同一个判断:此刻不值得完全信任模型的自主决策。
信任边界的现实映射
以上谈的都是两个项目的具体观察,但同样的信任博弈在行业层面反复上演。
上面讨论的两层信任,不是抽象的理论推演。过去几个月发生的两件事,恰好是这两个议题的现实注脚。
OpenClaw 事件:平台信任的边界
OpenClaw 是一个开源自主 AI agent 平台,GitHub 上超过 34 万 stars。它可以执行 shell 命令、读写文件、自动化浏览器、管理邮件和日历。用户通过 OpenClaw 把 Claude 订阅的 OAuth token 接入,$200/月的订阅跑出 $1,000-5,000 的 API 等价用量。
Anthropic 的反应分三步。2026 年 1 月,静默技术封堵——订阅 OAuth token 在 Claude Code CLI 外失效,无事先通知。2 月,发布法律合规文档,明确禁止订阅 token 用于第三方工具。4 月,订阅不再覆盖第三方工具用量,需额外按量付费。
社区反应剧烈。DHH 在 X 上称其 “very customer hostile”[1],George Hotz 发了博文 “Anthropic Is Making a Huge Mistake”[2]。Hacker News 上的讨论串里,用户用"自助餐厅对比"来形容:无限量订阅的承诺遇到了真正的无限量使用者。
OpenAI 的策略截然相反——OpenClaw 可以接入 ChatGPT Pro 订阅。OpenClaw 的创始人 Peter Steinberger 加入了 OpenAI[3],同时把 OpenClaw 移交给基金会保持独立。一时间,“开放 vs 封闭"的叙事似乎有了明确的答案。
但换一个角度想。OpenClaw 把 shell 权限、文件系统、邮件日历都交给一个 prompt 注入就能劫持的 agent。Zenity Labs 演示过零点击攻击链[4]:通过 Google Document 间接注入 prompt → agent 创建 Telegram 后门 → 修改 SOUL.md 实现持久化 → 部署定时任务每 2 分钟重新注入 → 建立传统 C2 信道实现完全控制。所有步骤用的都是 OpenClaw 的设计能力,不需要任何软件漏洞。Gartner 的评估结论是"不可接受的网络安全风险”[5]。
差个题外话,这些安全问题引发了用户的信任危机,但 OpenClaw 开发方在 2026 年 3 月做了系统性回应:集中披露 9 个 CVE 并逐一修复,引入凭证静态加密、插件权限管控和沙箱隔离增强[6]。安全问题存在,但开发方的响应速度和整改力度同样值得记录——这个过程本身验证了信任模型在 agent 开发中的现实意义:不是追求"不出事",而是"出事后能快速收回到安全边界内"。
从这个角度看,Anthropic 的封堵不只是商业决策。“我把你当用户"的哲学在生态层面延伸为:当信任基础不够时,收回到自己的驾驭框架里,在受控边界内逐步开放——而不是把 shell 权限交给一个 prompt 注入就能劫持的第三方 agent。后续我们看到,Claude Code 正在逐步加入 Coordinator、Team Mode、后台任务等能力,但每一步都在自己划定的边界内。
那 OpenAI 呢?公开支持 OpenClaw 是真的信任用户,还是用开放策略抢夺 power user 生态?两种策略背后,对"平台-开发者-用户"信任关系的假设截然不同。我没有答案,但这个问题值得持续追问。
驾驭工程的启发:信任驱动的设计取舍
驾驭工程(Harness Engineering)是一个正在形成的工程领域[7]:研究如何通过基础设施把语言模型从文本预测器变成可靠、安全的 agent——不是模型本身,而是模型周围的一切。2026 年 3 月底,Claude Code 的源码因打包失误泄漏到 npm[8],为驾驭工程的探索提供了大量参考资源。
这套方法论回答的不是"模型能不能做”,而是"在什么条件下允许模型做"。每一层都是在不同维度上划定信任边界。这给未来设计和开发 agent 提供了一个实用的思考框架:不是照搬具体的实现模式,而是在方案设计和取舍时,让信任关系成为决策依据。
举几个例子。
1. 什么时候用物理约束,什么时候用 prompt 指令?
驾驭工程里有一个模式叫计算约束(computational control):用代码结构让违规成为不可能,而不是用 prompt 要求模型自觉遵守。举个例子:任务列表的存储格式设计成 agent 只有一个 updateStatus(taskId, newStatus) 接口,没有 deleteTask() 或 editHistory() 接口。这样模型即使想虚报进度——比如把 10 个任务中的 3 个标为完成但实际上什么都没做——它也做不到,因为列表结构和变更历史对它不可写。这背后的信任判断是:不信任模型会诚实汇报自己的进度。如果用 prompt 指令——“请准确汇报完成情况”——模型在上下文压力下可能偷工减料。计算约束把信任问题从"模型会不会遵守"变成"模型能不能违反"。
反过来,如果信任基础足够——比如任务简单、验证成本低、出错影响小——prompt 指令就够了。计算约束的代价是灵活性降低,不是所有场景都值得这个代价。
2. 什么时候用对抗式审查,什么时候用用户直接 review?
驾驭工程里的 Evaluator Agent 是独立 agent,带着"试着打破它"的对抗心态审查输出。Cursor 的 Bugbot 在早期版本(2025 年)的做法[9]是对同一个 diff 跑 8 轮并行分析,每轮随机打乱 diff 的顺序,然后用多数投票来抑制单次分析的幻觉——当多轮分析独立发现同一个问题,才把它当作真实 bug 上报。这背后的信任判断是:不信任模型能客观评估自己的工作。
对于高风险决策——代码合并、安全变更、生产部署——对抗式审查是值得的。但对于日常的小修改,让用户直接 review 更高效。对抗式审查的代价是延迟和成本翻倍。
3. 什么时候用红灯门控,什么时候让模型自由调度?
驾驭工程的多层 agent 架构里,Worker 不能碰核心代码,直到上层 Coordinator 审批通过方案。Claude Code 泄漏的 Coordinator Mode[8]显示,它把工作流分为 Research、Synthesis、Implementation、Verification 四个阶段,Worker 在前三个阶段都不能越权。这是计算门控——不信任 Worker 能自己判断优先级和依赖关系。
如果模型足够成熟,任务之间独立性高,自由调度可以减少瓶颈。但并发 agent 的协调开销是真实的——多个 agent 容易陷入重复劳动或只在表层做低风险修改,而回避需要深入思考的核心问题。红灯门控的代价是并行度降低,但保证方向正确。
4. 沙箱隔离到什么程度?
驾驭工程里沙箱隔离的粒度本身就是一个信任判断。Claude Code 泄漏的源码显示,它的 Dream 子系统[8]——一个在后台做记忆整理的 agent——被限制为只读 bash:可以查看项目,但不能修改任何东西。这背后的信任判断是:不信任后台 agent 不会在无人监督时产生副作用。
隔离程度越高,安全性越好,但灵活性越低。完全信任的沙箱里,后台 agent 可能产生意料之外的修改。完全不信任的沙箱里,agent 连必要的配置都无法读取。取舍取决于任务的风险等级。
这些取舍的本质
每一个取舍背后都是一个信任判断:我信任模型能做这件事吗?如果不完全信任,用什么结构性的约束来弥补?约束的代价是什么?这个代价值得吗?
驾驭工程提供的不是标准答案,而是一个思考框架:在用户、工具和大模型三者之间,让信任关系驱动架构决策,而不是反过来。
这两个项目告诉我们的
Aristotle 和 claude-code-reflect 不是"哪个更好"的关系,它们是同一条信任曲线上的两个点。
真正的问题从来不是"要不要 human-in-the-loop",而是:此刻这个模型在这个任务上的可靠程度,能支撑多大的授权?
随着模型能力提升,这个答案会变。checkpoint 会后移,自动化程度会提高,review 频率会降低。但判断"现在可以后移了"这件事本身,永远是人的责任。
而这个判断不只发生在用户和 AI 之间。平台对开发者的信任、平台对模型能力的评估、开发者对工具链的依赖——多层信任关系交织在一起,构成了人机协作的真实图景。信任边界会随着模型能力、平台策略、用户认知的变化持续漂移。这篇文章提供的不是答案,而是一个持续追问的框架。
看到这里,如果你产生了更深入了解的兴趣
两个项目都是 MIT 许可,欢迎参与。
Aristotle(OpenCode): 当前最需要的改进包括:Reflector 在非交互模式下的模型选择默认值(目前 opencode run 在非交互模式下会卡在模型选择提示)、session_read() 在不同 model/provider 组合下的优雅降级路径、以及规则去重机制(目前语义相似的规则会重复累积)。
claude-code-reflect(Claude Code): 当前有 6 个已知问题待解决,最关键的三个是:准备阶段的原子性(多步操作需合并为单条 Bash 调用,否则用户会看到"假死"状态)、subagent 完成后的自动通知机制、以及重试时的 session ID 碰撞。此外,非英语 correction signal 的测试覆盖和 RCA prompt 质量改进也很有价值。
如果你在日常使用中发现模型的某类错误反复出现,欢迎把它做成 test case 提 PR——这种来自真实使用场景的 correction pattern,是让这类工具真正有用的核心材料。
Aristotle: https://github.com/alexwwang/aristotle
claude-code-reflect: https://github.com/alexwwang/claude-code-reflect
附录:OpenClaw 2026 年 3 月安全修复详情
上文提到 OpenClaw 的安全问题及其安全加固。以下是具体的问题清单和修复进展。
CVE 清单(2026 年 3 月 18-21 日披露)
| CVE | 严重程度 | 问题 | 修复版本 |
|---|---|---|---|
| CVE-2026-22171 | 高危 (CVSS 8.2) | 飞书媒体下载路径遍历 → 任意文件写入 | 2026.2.19 |
| CVE-2026-28460 | 中危 (CVSS 5.9) | Shell 换行符绕过命令白名单 → 命令注入 | 2026.2.22 |
| CVE-2026-29607 | 中危 (CVSS 6.4) | “始终允许"包装器绕过 → 偷换载荷实现 RCE | 2026.2.22 |
| CVE-2026-32032 | 高危 (CVSS 7.0) | 不可信 SHELL 环境变量 → 共享主机上的任意 shell 执行 | 2026.2.22 |
| CVE-2026-32025 | 高危 (CVSS 7.5) | WebSocket 暴力破解无速率限制 → 浏览器端会话劫持 | 2026.2.25 |
| CVE-2026-22172 | 严重 (CVSS 9.9) | WebSocket scope 自声明 → 低权限用户获取管理员权限 | 2026.3.12 |
| CVE-2026-32048 | 高危 (CVSS 7.5) | 沙箱逃逸 → 沙箱内会话生成非沙箱子进程 | 2026.3.1 |
| CVE-2026-32049 | 高危 (CVSS 7.5) | 超大媒体载荷 DoS → 无需认证即可远程崩溃服务 | 2026.2.22 |
| CVE-2026-32051 | 高危 (CVSS 8.8) | 权限提升 → operator.write scope 访问 owner 专属接口 | 2026.3.1 |
来源:[6][10]
安全架构加固(3 月 21 日,PR #51790)
- 凭证静态加密:AES-256-GCM + HKDF-SHA256 密钥派生,macOS Keychain 存储主密钥
- 插件权限管控:声明式
capabilities字段,71 个内置扩展全部更新 - 文件权限硬化:原子写入消除 TOCTOU 竞态
- 缓存边界限制:9 处内存 Map 缓存增加容量上限
来源:[11][12][13]
参考来源:
- DHH 关于 Anthropic 的评论: x.com/dhh/status/2009664622274781625
- George Hotz, “Anthropic Is Making a Huge Mistake”:geohot.github.io/blog
- Peter Steinberger 加入 OpenAI:TechCrunch 报道
- Zenity Labs, “OpenClaw or OpenDoor?"(2026-02-04):labs.zenity.io
- Gartner, “OpenClaw: Agentic Productivity Comes With Unacceptable Cybersecurity Risk”(2026-01-29):gartner.com
- OpenClaw, “Nine CVEs in Four Days: Inside OpenClaw’s March 2026 Vulnerability Flood”(2026-03-28):openclawai.io
- Birgitta Böckeler, “Harness Engineering for Coding Agent Users”(2026-04-02):martinfowler.com
- Claude Code 源码泄漏分析(2026-03-31):github.com/soufianebouaddis/claude-code-doc
- Jon Kaplan, “Building a Better Bugbot”(2026-01-15):cursor.com/blog/building-bugbot
- OpenClaw GitHub, “Security audit remediation: encryption, capabilities, hardening” PR #51790(2026-03-21):github.com
- OpenClaw 3.22 Release(2026-03-22):openclaws.io
- OpenClaw 2026.3.28 Release(2026-03-28):blink.new
- OpenClaw, “The February Security Storm”(2026-03-04):openclaws.io