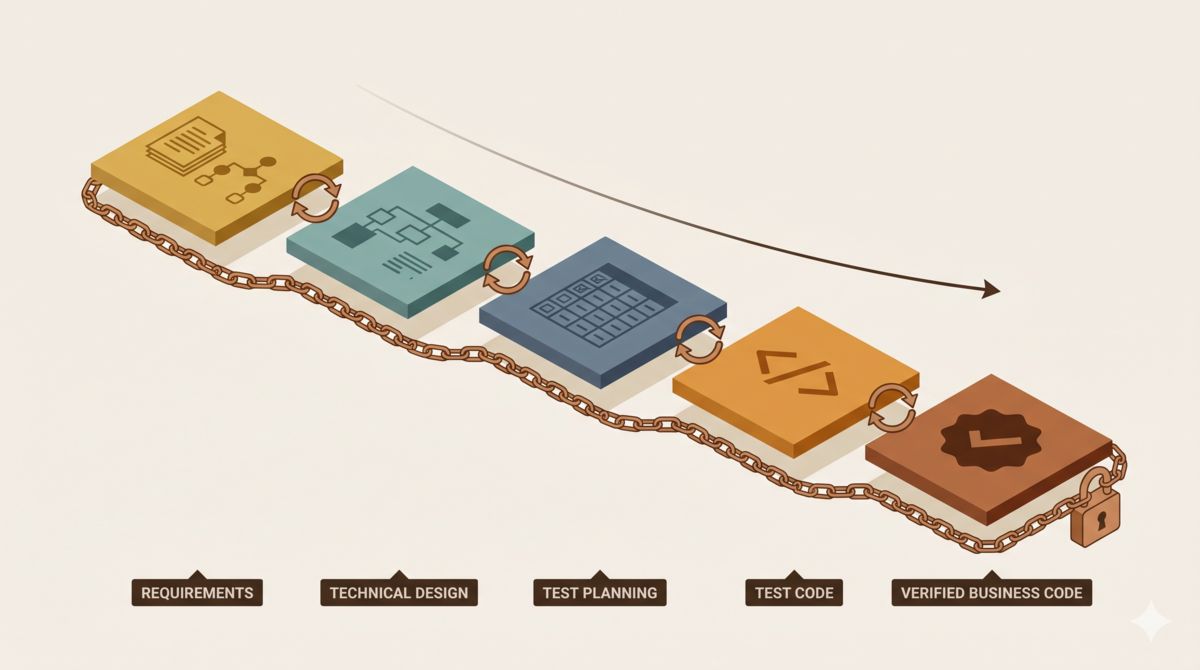
The Invisible Blank Layer
Series: Breaking to Build: TDD Process Iterations (Post 3) Post 1: What a Failed Experiment Got Right · Post 2: Using the Method to Improve the Method TL;DR: Phase 6 already does diagnostics at the integration level — drilling into each bug’s root cause. What it doesn’t do: cross-defect pattern scanning, component gap checking, execution order analysis. Those belong to Phase 7. In small systems, Phase 7 catches a few more bugs. As the system grows, those same three tasks produce something different — building test infrastructure, hardening CI rules, driving architectural evolution. Phase 7 doesn’t make architecture decisions. But it provides the scarcest input for those decisions: evidence-based problem localization. ...