
TL;DR: You changed a skill. How do you know it’s actually better, not just confirmation bias? I ran a double-blind experiment: two versions, four scenarios, independent blind scoring. The scorer saw X=2.44, Y=2.41 and said “can’t tell them apart.” After unblinding: simplified version won 4/0.
The 0.03 Gap
I shortened a review skill from 159 lines to 89 lines. Wanted to verify the simplified version actually worked better, so I ran a double-blind experiment.
The raw scores came back: X averaged 2.44, Y averaged 2.41. A difference of 0.03. Out of 3 points max, a 0.03 gap tells you nothing.
Two weeks of work. 8 evaluator instances. 4 scenarios. 8 dimensions in the rubric. The conclusion: “no difference.”
I didn’t buy it. Not because I’m stubborn—I looked at the scores per scenario. In every scenario, X and Y each had wins. No scenario was a tie. So how could the averages be so close?
I checked secret-mapping.txt and saw the problem.
In a double-blind experiment, the mapping between X/Y and variants is randomized. In S1, X was A (original), Y was B (simplified). In S2, X was B, Y was A. In S3, X was A again. In S4, X was B again. The scorer doesn’t know the mapping, so it just averaged all four X’s and all four Y’s.
Four X’s contain two A scores and two B scores. Same for Y. A and B get mixed together in the average, so the difference disappears.
This isn’t a bug in the scorer; it’s designed to only see X and Y, without knowing the mapping. The mistake was in my experiment design: the scorer shouldn’t aggregate across scenarios. That step should be done by someone who knows the secret mapping.

After mapping back to A/B:
| Variant | S1 | S2 | S3 | S4 | Average |
|---|---|---|---|---|---|
| A (original) | 2.500 | 2.375 | 2.250 | 2.125 | 2.313 |
| B (simplified) | 2.750 | 2.500 | 2.375 | 2.500 | 2.531 |
0.03 became 0.218. B won all four scenarios.
Breaking Down the Four Scenarios
After revealing the secret mapping:
| Scenario | X actually was | Y actually was | Who won | Gap |
|---|---|---|---|---|
| S1 | Variant A | Variant B | B | +0.250 |
| S2 | Variant B | Variant A | B | +0.125 |
| S3 | Variant A | Variant B | B | +0.125 |
| S4 | Variant B | Variant A | B | +0.375 |
4/4 sweep. Average: A=2.313, B=2.531.
Why did 0.03 turn into 4/4 wins? Because the scorer only saw X and Y labels, not which variant they represented. Randomization smoothed out the experimenter’s systematic bias. In S2 and S4, B was labeled X and A was labeled Y. The scorer still gave X (which was B) higher scores in those scenarios, proving B’s advantage is real, not a labeling effect.
Designing the Protocol
Step 1: Define Variants
- Variant A: Current version ralph-review-loop.md, 159 lines
- Variant B: Signal Purity simplified version, 89 lines (removed derivable content)
Step 2: Design Rubric
8 dimensions, 0-3 points each:
- Prompt Contamination (includes stop conditions/counts → cleaned up)
- Dual-Pass Adherence (skips fact collection → strict Recall→facts→Precision)
- Severity Accuracy (multiple misclassifications → all correct)
- Defect Discovery (missed ≥2 real defects → found all)
- False Positive Control (≥3 false positives → zero false positives)
- Suggestion Quality (vague → all specific and actionable)
- Critical Opinion Substance (manufactured → deep strategic insight)
- Format Compliance (missing sections → fully compliant)
Step 3: 4 Scenarios
| Scenario | Target code | Focus |
|---|---|---|
| S1 | Python user service | Basic defect detection |
| S2 | React payment form | UI state management |
| S3 | Java order processor | Concurrency issues |
| S4 | Node.js cache | Race conditions |
Each scenario runs once per variant, 8 evaluator runs total.
Step 4: Blind Mapping
Randomly assign X/Y labels. Independent scorer doesn’t know the correspondence:
S1: X=A (current) Y=B (simplified)
S2: X=B (simplified) Y=A (current)
S3: X=A (current) Y=B (simplified)
S4: X=B (simplified) Y=A (current)

Step 5: Independent Scorer
Use a fresh AI instance for scoring. No knowledge of secret mapping. Score each dimension independently, then average.
Real-World Pitfalls
The experiment wasn’t smooth. I hit two real problems.
S1’s ANSI Contamination
First run S1-A scored 0.625, far below other scenarios. The output file was contaminated with ANSI escape sequences, terminal color codes mixed into the text, making the file nearly unreadable.
Not a protocol flaw, an execution issue. After re-running, the score normalized: 2.500.
S4’s Reversal
In S4 (Node.js cache), Variant A actually won in two dimensions: Defect Discovery and Suggestion Quality. A found the race condition and gave more specific fix suggestions (using Map instead of Object, using Object.create(null) to avoid prototype chain pollution). Variant B still had a higher total score in S4 (2.500 vs 2.125), but won on Dual-Pass Adherence and Format Compliance, not on finding bugs.
This proves “simplification” isn’t a cure-all. Signal Purity removed derivable content, but in some scenarios, that content provided heuristic cues that helped the model discover specific problems.
B’s Real Advantage
Comparing 8 dimensions, B’s core strength is in Dual-Pass Adherence:
- B explicitly shows the three-stage flow (Recall→Facts→Precision)
- A often skips the fact collection step, going straight to Precision phase
The data makes this clear:
| Dimension | A average | B average | Gap |
|---|---|---|---|
| Dual-Pass Adherence | 2.00 | 3.00 | +1.00 |
All other dimensions had gaps under 0.5. B didn’t win because it was “simpler”—it won because it more strictly enforced the two-stage protocol.
Five Failure Modes
This experiment didn’t work the first time. In an earlier attempt, five failure modes occurred in succession, showing me how deep the rabbit hole goes for AI agent experiments.
1. Phantom Delivery
Wrong file path. The evaluator couldn’t find the file. But instead of erroring out, it kept running with empty input and produced a result that looked normal but had actually reviewed nothing. You think it ran, but it saw nothing.
2. Self-Scoring
The orchestrator scored its own results. Bias went straight into the evaluation.
3. Single-Scenario Claims
One data point with huge variance. You tell yourself “this scenario is too hard,” but that’s rationalizing. A single data point can’t support any conclusion.
4. Ground Truth Favoritism
Most items in your ground truth directly test your variable. If you suspect “simpler is better,” you ask “is the output concise” in the ground truth; you’re self-validating.
5. Context Contamination
Same agent runs evaluator first, then scorer. Context leakage contaminates the results.
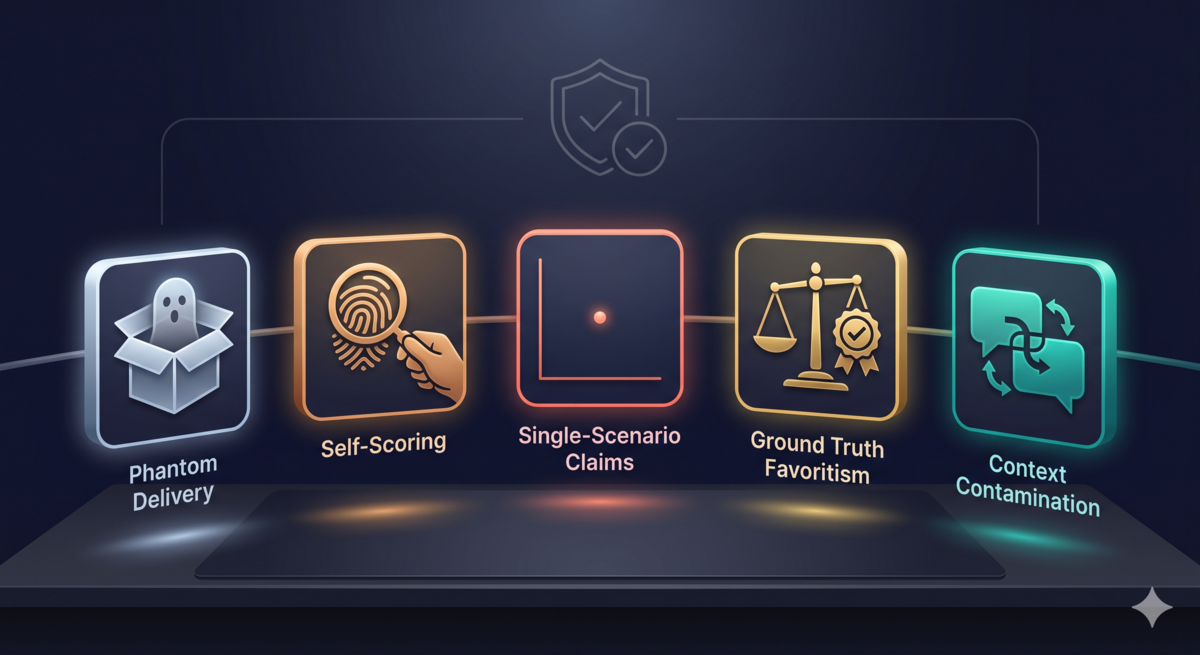
These five failure modes are now in a skill (/double-blind-experiment). Every time I run an experiment, I check against them.
Double-Blind Isn’t a Silver Bullet
The double-blind protocol solves one problem: preventing contamination in the comparison process. It doesn’t solve these:
- Rubric design bias—your rubric may favor certain characteristics
- Scenario selection bias—the scenarios you choose may favor your variable
- Ground truth quality—reference answers may contain errors
- Aggregation logic errors—like the 0.03 gap in this article, an AI scorer may aggregate scores incorrectly
This isn’t about proving the simplified version is better. It’s about making a point: when you change a skill, you need a reliable testing framework. Otherwise you don’t know if you’re improving or just getting lucky.