in the “Taming AI Coding Agents with TDD” series. The first article covered requirement anchoring at the test layer[1]. Tests assume clear requirements. This one goes upstream — to the practice of disambiguating requirements before a single line of code gets written.
The v1 Lesson: One-Line Requirement, 371 Lines of Pollution
Aristotle v1 had no GEAR protocol[2]. No role separation. The entire reflection feature lived in a single 371-line SKILL.md. The requirement was roughly one sentence: the system should detect when a user corrects an AI mistake, then generate a reusable rule.
The AI took that sentence and ran. Three commits. SKILL.md, test scripts, README — done in one pass. All 37 static assertions passed. End-to-end tests were green across the board[3].
After deployment, reality set in. The reflection task never ran in a background session. It executed inside the main session, injecting all 371 lines of SKILL.md into the context. When the subprocess finished, background_output(full_session=true) pulled the entire RCA report back into the main session. The review process was worse — task() creates a non-interactive subagent session (an OpenCode architecture constraint), so users had no way to approve or reject anything inside the subprocess.
The design principles said “zero context pollution in the main session” and “transparent process for the user.” Not a single one was met.
Why? Because the requirement never specified three things:
- Reflection must run in an isolated background session. The main session must stay clean. — Not written. The AI picked the simplest implementation: stuff everything into the same session.
- Review must happen in an interactive environment where the user can confirm or reject. — Not written. The AI didn’t know
task()creates a non-interactive session. It assumed the subprocess could handle user interaction. - After reflection completes, notify the user only. Don’t push the full output back into the main session. — Not written. The AI chose the most direct information transfer: push everything.
This wasn’t a bug in the AI. It was a gap in my requirements. The AI filled in every detail I left unspecified, using the most common patterns from its training data. A human developer would have asked about these constraints. The AI doesn’t ask — it fills in the blanks.
Why AI Doesn’t Ask Follow-Up Questions
LLMs are structurally incapable of initiating clarification loops. They are trained to produce answers, not to raise questions. This isn’t a flaw. It’s a design goal.
You give a prompt. The model searches its training data for the most probable continuation. Its training objective is to maximize next-token prediction accuracy. Asking a question means halting that prediction. That contradicts the training objective.
This property is an advantage when generating content. It’s a disaster in requirements engineering.
The fuzzier and more incomplete your requirement, the more detail the AI fills in. That detail doesn’t come from what you want. It comes from what’s statistically most common in the training data. By the time you notice the drift, hundreds of lines of code are already written.
AI has no intrinsic motivation to ask “what do you mean?” You have to close the gaps upstream. Not ambiguity — absence. What you don’t write, the AI invents.
The GEAR Protocol: A Structured Method Born from Failure
GEAR stands for Git-backed Error Analysis & Reflection. It wasn’t planned from the start. It was forced out by the four failures of v1.
V1 had a single agent role. All logic crammed into one 371-line SKILL.md. After the failure, I split it into four files: routing logic stayed in SKILL.md (84 lines), reflection launch moved to REFLECT.md, review to REVIEW.md, and the subagent analysis protocol to REFLECTOR.md. Each file loads only in its own scenario.
Splitting files solved context pollution. But a deeper problem remained: who writes the rules, who reviews them, who consumes them — these role responsibilities were undefined. After the split, I realized I needed a protocol to define the relationships between roles. That’s where GEAR started.
GEAR’s core is the PAC model (Production-Audit-Consumption) and the Δ decision factor. PAC separates three roles completely: Production (R) writes rules but doesn’t judge them, Audit (C) reviews rules but doesn’t modify them, Consumption (L) applies rules but doesn’t audit them. The Δ factor determines review level based on confidence, risk weight, and historical data — new rules require mandatory human review, with gradual automation as sufficient data accumulates. This mechanism addresses rule quality management[4].
But GEAR governs error reflection workflows. It doesn’t prescribe how to write requirements. The tdd-pipeline project[5] uses User Stories with Given-When-Then acceptance criteria, plus core/secondary priority levels, at the requirements stage. That’s independent of GEAR’s PAC/Δ model.
This article is about requirement gaps. GEAR’s value here isn’t in directly guiding requirement writing. Its value is the lesson it taught: without a structured protocol, AI fills in the blanks the easiest way it can. That lesson applies equally at the requirements layer.
How to Write Requirements That Leave No Room for Guessing
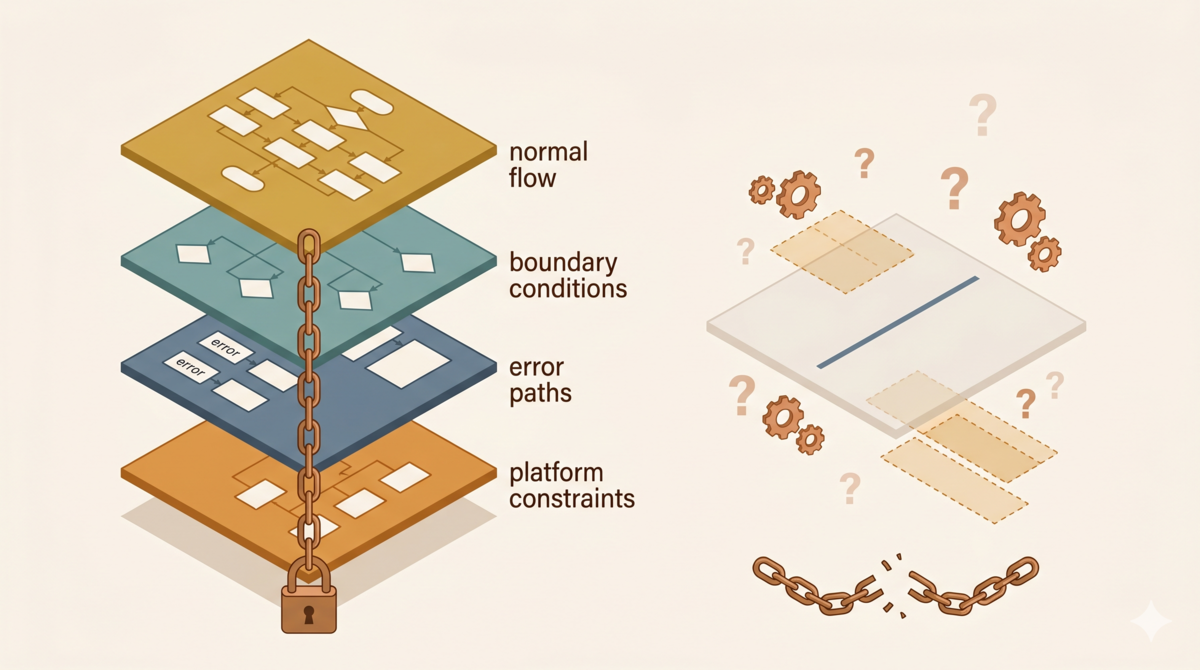
V1 had a one-line requirement. What should a structured requirement document include? Working backward from the v1 failures, at least four parts.
Take the reflection trigger feature as an example.
The Vague Version
“When a user corrects an AI mistake, the system should prompt the user to start a reflection workflow.”
The Structured Version
Requirement ID: AC-001 Module: Reflection Trigger Priority: core
Happy Path
- User sends a message containing an explicit error correction → system displays a reflection prompt card
- User clicks “Start Reflection” → system creates an isolated reflection session, keeping the main session clean
- Reflection completes → system generates a rule and submits it for review, notifying the user to check the result
Boundary Conditions
- User says “that’s wrong” without specifying the actual error → still trigger the prompt
- User corrects a product design opinion, not a factual error → do not trigger the prompt
- User makes multiple corrections in the same conversation turn → show the prompt only once
- Conversation history is empty → do not trigger the prompt
- Correction keywords appear inside a code block comment → do not trigger the prompt
Error Paths
- Reflection session creation fails → display an error message, guide the user to retry
- Rule generation fails → display the failure reason, do not fail silently
- Review process times out → auto-save as draft, notify the user for follow-up
Platform Constraints
task()creates a non-interactive subagent session — review cannot happen in the subprocess; it must be implemented in the main session- After reflection completes, only notify the user — do not push the full output back into the main session. Information flow must be pull-based
Compare the two. The vague version says “what to do.” The structured version specifies “when to do it,” “when not to do it,” “what happens when it fails,” and “what the platform can and can’t do.” The AI doesn’t need to guess.
Pay attention to the “Platform Constraints” section. This was completely missing from v1 requirements. It’s the direct cause of the failure. If I had written “task() creates a non-interactive session” as a constraint, the AI would never have assumed users could review inside the subprocess.
These four parts aren’t defined by GEAR. They’re standard industry practice for acceptance criteria, boundary conditions, and error paths. The principle is one line: whatever you don’t specify, the AI will invent. The more you write, the less room the AI has to improvise.
How to Force Yourself to Write All Four Parts
Knowing you should write four parts doesn’t mean you can. During v1, I didn’t even realize “platform constraints” was a thing worth writing down. I didn’t know what I didn’t know.
The tdd-pipeline project[5] uses a method to solve this: Socratic questioning. During the requirements phase (Phase 1), the workflow mandates a deep-interview with the user — at least 3 clarifying questions, targeting 3-5. The questions include:
- What problem does this solve?
- Who are the participants?
- Where are the system boundaries?
- What is explicitly out of scope?
Then comes a critical step: challenge vague terms. Words like “fast,” “secure,” “user-friendly” must be forced to quantifiable definitions. Undeclared constraints (regulatory, performance, compatibility) must be identified. No ambiguity is allowed to survive before moving to the next phase.
This isn’t hoping the AI will ask on its own. It’s a process-level mandate: you must ask. At least 3 questions. No moving forward until every ambiguity is resolved.
In traditional development, this questioning happens inside a developer’s head. Experienced developers ask these questions naturally. AI doesn’t. So you have to externalize “the questions in your head” into process steps. That’s what tdd-pipeline does.
Series Preview
This article covered structured requirements — closing the gaps before AI fills them for you. Every stage of the pipeline has its own pitfalls and lessons worth sharing:
- Design layer: Mapping PRDs to technical solutions — during the second rewrite, requirements were clear, but
task(run_in_background=true)async behavior wasn’t validated upfront. Agent O still got pulled into the main session. Why skipping technical investigation lets the AI fill in the blanks on its own. - Review mechanism: The design philosophy behind the Ralph Loop — AI errors are systematic, not random. They need structured review, not spot-checking.
- Full pipeline summary: One diagram from requirements to code — the marginal cost of strict process decreases with project complexity and increases in necessity with AI involvement.
The core argument of this series: AI coding agents are amplifiers. They amplify your engineering capability and your engineering debt. Taming them requires more process discipline than traditional development, not less.
References
- Previous article: Write Test Plans Before Test Code: Requirement Anchoring in AI Development
- GEAR protocol RFC: Three Lives of a Markdown: From Static Rules to a Git-Versioned MCP Server
- Aristotle rewrite journal: From Four Scars to a Suit of Armor: Harness Engineering in the Aristotle Rewrite
- GEAR protocol specification: DOI 10.5281/zenodo.19660780
- tdd-pipeline project: https://github.com/alexwwang/tdd-pipeline