This is the first article in the series “Taming AI Coding Agents with TDD.” The series has one thesis: AI-assisted development demands stricter process discipline than traditional development, and here is exactly how to enforce it at every step.
The series follows the pipeline order — requirements, design, testing, review, implementation. This article starts at the testing layer. During Aristotle’s third refactoring, the test plan document was where I learned the hardest lesson. I’ll cover this layer first, then work backward and forward in subsequent posts.
Backstory: Two Crashes, Then I Learned to Walk
Aristotle is an AI error reflection tool I built. I refactored it twice. Both times, it failed to deliver what the requirements described.
The first time around, 37 static assertions all passed. E2E tests were green across the board. But after deployment, I discovered the main session had been injected with 371 lines of context. The review workflow couldn’t run in a non-interactive sub-session [1]. The tests verified “did the protocol execute correctly.” They never checked “are the side effects acceptable.”
That first crash exposed a core problem: the requirements document had too much ambiguity. AI doesn’t ask follow-up questions. It fills in the gaps with its own assumptions. To close this loophole, I designed the GEAR protocol — a requirement disambiguation protocol that forces every requirement to spell out its acceptance criteria, boundary conditions, and error paths. I’ll cover this protocol in a future article.
The second refactoring used GEAR to lock down requirements. The context pollution and broken review workflow were fixed. Code structure: split. Information flow: pull model. Design principles: seemingly in place. But after installation, the reflection feature still didn’t do what the requirements described. The accuracy of detecting correction signals was far below expectations. The generated rules didn’t match correctly in most scenarios. The second refactoring fixed the side effects from v1, but nobody had asked: “Does the requirement-described capability actually exist after installation?”
Both failures pointed to the same root cause: no test plan document. Test code only covered execution paths, not the requirements themselves. The first time, it missed the design principle constraints. The second time, it missed functional correctness.
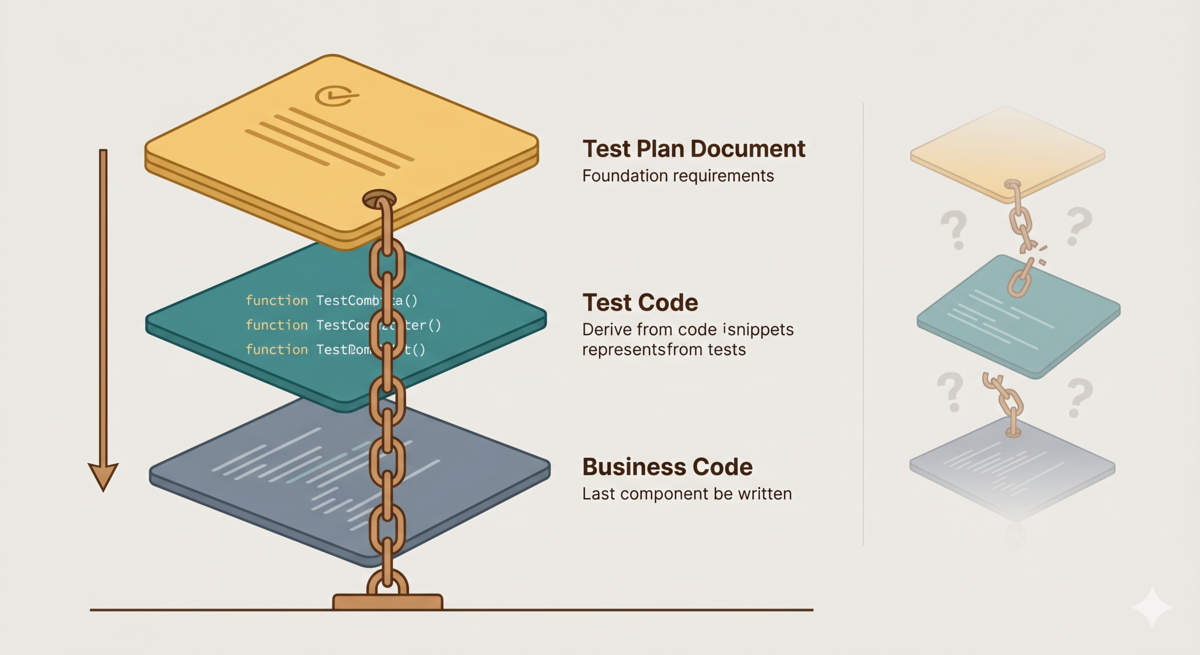
The third time, I changed my approach. No more jumping straight to code. I followed the pipeline step by step: GEAR protocol for requirements → product design document → technical design document → test plan document → test code → business code. Each phase had an independent reviewer. Nothing moved forward until the reviewer found zero issues.
This article covers the test plan document — why it must exist before test code, how its role shifts in AI-assisted development, and how to write one.
Why “Test Code Before Business Code” Matters More with AI
Classic TDD says: write a failing test, write the minimum business code to pass it, then refactor [2]. That sequence works well enough in traditional development. But in AI-assisted development, the weight of “write tests first” goes up by an order of magnitude.
Three reasons.
First, AI has zero awareness of ambiguity in natural language. An experienced developer reads “users should be able to register” and immediately asks: “What email format requirements? Password length limits? How do you handle duplicate registrations?” AI doesn’t ask. It translates “users should be able to register” into a pile of happy-path code — standard email, eight-character password, everything normal. It looks like it works, until edge cases expose the gaps.
Test cases are the most precise tool for eliminating ambiguity. should_reject_registration_with_duplicate_email() leaves no room for interpretation. It passes or it doesn’t. The most precise language you can give an AI is a test case. Not a user story in a requirements document. Not an architecture diagram in a technical spec.
Second, AI generates code far faster than humans can review it. Human developers have a natural rhythm — the thinking that happens during writing is itself a checkpoint. AI can produce hundreds of lines per second. Human review speed can’t keep up. Without tests as an automated quality gate, bugs hidden in AI-generated code will accumulate faster than in traditional development. Not because AI writes worse code, but because humans can’t read it fast enough.
Third, AI errors aren’t random. They’re systematic. Misunderstanding requirements, assuming context, oversimplifying — in Aristotle’s eight-category error taxonomy, each pattern has a clear signature [3]. Systematic errors demand systematic constraints. The test plan document is the carrier for those constraints. It’s not a post-hoc verification tool. It’s a pre-emptive guardrail against systematic drift.
So in AI-assisted development, TDD isn’t just “good engineering practice.” It’s indispensable risk control. Without it, AI’s high output isn’t efficiency — it’s technical debt accumulating under the illusion of speed.
Requirement Anchoring: Where the Test Plan Document Fits
This method isn’t invented from scratch. The Requirements Traceability Matrix (RTM) is a standard practice defined in ISO/IEC/IEEE 29148 — every requirement must trace to a test case, and every test case must trace to a requirement [5]. Gojko Adzic’s Specification by Example (2011) argues for defining requirements through concrete examples rather than abstract descriptions. Those examples become executable acceptance tests [6]. Acceptance Test-Driven Development (ATDD) is the workflow that chains these concepts together.
These methods are well-established in traditional software development. My contribution isn’t inventing new concepts. It’s answering one question: when the coder changes from human to AI, why do these existing practices go from “nice to have” to “can’t work without them”?
In traditional development, RTM and SBE are quality assurance measures. Even without them, human developers ask questions during coding, discuss ambiguities, and catch omissions in code review. AI does none of this. It takes a vague requirement and outputs code. Fast enough that you can’t correct it mid-process. The human safety net is gone — RTM and SBE shift from “quality bonus” to “the only quality gate.”
From this perspective, I gave the combined application of RTM + SBE + ATDD a shorthand name: Requirement Anchoring. One sentence captures it — tests anchor on requirements, not on implementation. The name isn’t a new concept. It’s just easier to remember.
In traditional development, practitioners of RTM and SBE have always done “derive tests from requirements.” But implementation code can still exist before tests. In AI-assisted development, this order must be strictly enforced. AI is too fast. Two minutes after you finish the requirements, it tells you “implementation done.” You haven’t had time to design the test plan, and the code already “runs.” By the time you discover the requirements were misunderstood, you’re staring at a pile of code that needs to be thrown out.
Requirement Anchoring pulls the test plan document ahead of implementation. The flow becomes:
Product Design → Technical Design → Test Plan Document → Test Code → Business Code
The test plan document answers “how do we verify the requirement was correctly implemented?” not “how do we verify the code does what it does?” That distinction matters.
Take Aristotle’s reflection feature:
- Derived from implementation: test whether
Reflector.generate_rca()returns correctly formatted JSON. You’re testing the code’s behavior. - Derived from requirement anchoring: test whether “after the user triggers reflection, the system generates an auditable report containing root cause analysis.” You’re testing whether the requirement is satisfied.
The former validates code. The latter validates intent. When AI changes the implementation from approach A to approach B, the former probably breaks. The latter stays solid. Tests anchor on requirements, not on implementation.
The Four-Layer Structure of a Test Plan Document
A test plan document contains four layers: test scenario identification, test point enumeration, test case definition, and test development document. Each layer refines the previous one. Each has clear inputs and outputs.
Layer 1: Test Scenario Identification
Input: acceptance criteria from the requirements document.
Method: expand each acceptance criterion into test scenarios. One acceptance criterion typically maps to multiple scenarios — happy path, boundary conditions, error paths.
Take Aristotle’s reflection trigger. The acceptance criterion reads: “When a user corrects an AI error during conversation, the system should prompt the user to initiate reflection.”
Expanded into test scenarios:
- User explicitly corrects an AI error → should trigger prompt
- User vaguely says “that’s wrong” → should trigger prompt
- User corrects a difference of opinion, not a factual error → should not trigger
- User makes multiple corrections in the same conversation turn → should prompt only once
- Conversation history is empty → should not trigger
Notice that this expansion process is itself a second pass at validating the requirements. Writing scenario 3 forces you to answer: “Where is the boundary between a difference of opinion and a factual error?” If you can’t answer, the acceptance criterion isn’t precise enough. This is the value of Requirement Anchoring — test scenarios force ambiguities to the surface.
Layer 2: Test Point Enumeration
Input: test scenario list.
Method: define specific test points for each scenario. Test points are binary — pass or fail, no middle ground. This layer answers “what to test,” not “how to test.”
Scenario 1 expanded into test points:
- User message contains correction keywords → trigger
- Correction keyword appears inside a code block comment → do not trigger
- Two consecutive messages constitute one correction → trigger
- Correction keyword followed by “never mind, don’t change it” → do not trigger
Notice the distinction between Layer 2 and Layer 3. Layer 2 lists check items — “correction keyword in code comment should not trigger.” It refines the scenario but doesn’t yet have specific preconditions and step-by-step procedures. Layer 3 expands each check item into a full executable case — given what input, performing what operation, expecting what output. Enumerating check items before writing full cases prevents scenarios from getting lost in the details.
Each test point corresponds to one executable assertion. At this point, testing shifts from “verifying requirements” to “defining interfaces.” The test name should_trigger_on_explicit_correction() is essentially defining the public interface of CorrectionDetector.
Layer 3: Test Case Definition
Input: test point list.
Method: organize test points into concrete test cases. Each case includes preconditions, steps, and expected results.
This is the most precise instruction you can give an AI. A test case format:
Case: Explicit correction triggers reflection prompt
Precondition: Conversation history contains 3 normal interaction turns
Action: User sends "Your answer in turn 2 had the wrong API endpoint, it should be /api/v2/reflect not /api/v1/reflect"
Expected: System includes reflection prompt in the next response
An AI reading this case knows the input, the expected output, and where the boundaries are. More precise than any natural-language requirement description.
Layer 4: Test Development Document
Input: test case list, technical design document.
Method: map test cases to specific test files, test function names, and test types (unit / integration / e2e).
This layer produces the test coverage matrix. In the tdd-pipeline project [4], I define it as the core deliverable of Phase 3. Here’s an example from Aristotle:
| # | Acceptance Criterion | Test Type | Test File | Test Function | Description |
|---|---|---|---|---|---|
| 1 | AC-1 | Unit | test_detector.py | should_trigger_on_explicit_correction | Explicit correction triggers prompt |
| 2 | AC-1 | Unit | test_detector.py | should_not_trigger_in_code_comment | Correction in code comment does not trigger |
| 3 | AC-1 | Unit | test_detector.py | should_trigger_on_multi_turn_correction | Cross-turn correction triggers |
This table is the core deliverable of the test plan document. Every row is an executable contract. Subsequent test code only needs to implement the table. Business code only needs to make every row pass.
Why the Test Plan Document Prevents Systematic AI Bias
Back to the opening lesson. Two refactors of Aristotle, both skipping the test plan document.
The first time, test code only covered the protocol’s execution paths. Coordinator started Reflector, Reflector read the session, generated DRAFT. All passed. But the design had three principles: instant trigger, session isolation, and human-in-the-loop (critical operations require user confirmation). The tests covered the execution path of “instant trigger” and completely ignored the constraints of “session isolation” and “human-in-the-loop.”
The second refactoring fixed the side effects. Context pollution eliminated, review workflow functional. But the reflection feature’s own correctness — detecting correction signals, generating matching rules — still had no test coverage. Because neither time had a test plan document, I had never systematically asked myself: “Which test scenarios correspond to each requirement? Which test scenarios correspond to each design principle?”
The test plan document forces you to do this. Its first layer — test scenario identification — requires starting from acceptance criteria and covering happy paths, boundaries, and error paths. If an acceptance criterion includes “session isolation,” the test scenarios must include:
- Main session’s context token count change before and after reflection ≤ N
- Reflection process output is not auto-injected into the main session
- User must actively pull the review report
These scenarios aren’t derived from implementation. They’re anchored in requirements. Whether AI implements reflection as a subprocess, a sub-agent, or a remote call, these test scenarios stay the same.
The test plan document is the safety net for AI coding. It transforms “did the AI understand the requirement correctly?” from “AI judges for itself” to “AI executes against a table.” Humans define the table. AI fills in the implementation. With a test plan document, the focus of human review shifts from “does the code implement the requirements?” to “is the table complete enough?” But code review itself hasn’t disappeared. Security vulnerabilities, performance issues, maintainability still need human eyes. The test plan document narrows the review scope. It doesn’t replace review.
Third Refactoring: Test Plan Document in Practice
During Aristotle’s third refactoring, I wrote a complete test plan document following the four-layer structure. The payoff was immediate — not from the tests themselves, but from problems surfaced during the writing process.
Two defects emerged while writing test scenarios. Both had gone undetected before.
The first was a test methodology mismatch. Aristotle’s reflection trigger has two paths: synchronous fallback and async notification. Previous tests used non-interactive mode (opencode run --format json), which doesn’t support async notification callbacks. But the test scenarios defined the async path. So test results flickered — pass, fail, pass. The tested logic was stable. The test environment was fundamentally wrong. Three rounds of patches, each “looking a bit more convergent,” and then a claim of “verification passed.” In reality, we were testing the wrong thing from start to finish.
The root cause: no test plan document. Test code was derived directly from the implementation, without first asking “what is the actual runtime environment of the feature under test?” Layer 1 of the test plan document — test scenario identification — forces you to answer this question.
The second was test blind spots. After completing the test plan document, I had a reviewer cross-check it against the requirements. The review found 13 test blind spots. One typical example: static verification passed for the retry_pending route, but runtime routing behavior had no coverage. Static verification checks configuration structure, not runtime decisions. Without the systematic cross-referencing of a test plan document, blind spots like “correct configuration, wrong behavior” are nearly impossible to catch.
Meanwhile, user testing also exposed bugs that the test plan document could have prevented. A P0 bug: first-time installation didn’t initialize a git repository, causing write_rule() to fail immediately. If the test scenarios had included “fresh install, then run a complete reflection flow,” this bug would have been caught during development.
The third refactoring’s test plan document ultimately defined 95 new tests. Not a number pulled from thin air — derived layer by layer from requirements. Every test traces back to a specific acceptance criterion or design principle. That’s the fundamental difference from the first two attempts. The first two covered “what the code does.” This one covered “what the requirements demand.”
From Test Plan to Test Code: The TDD Pipeline
I packaged this method into a reusable tool: [tdd-pipeline][4].
It breaks AI-assisted development into five phases. Each phase has clear deliverables and a review gate:
Product Design → Technical Design → Test Plan Document → Test Code → Business Code
One rule: when test code doesn’t exist, or exists but hasn’t failed, writing business code is forbidden.
This rule is best practice in traditional development. In AI-assisted development, it’s survival. AI generates business code too fast. Without the test plan document as an anchor, AI delivers a “looks like it runs” implementation in two minutes. You don’t have time to judge whether it actually satisfies the requirements.
The five phases in tdd-pipeline correspond to five documents. Between each pair, a mandatory review mechanism (Ralph Loop) — an independent reviewer sub-agent audits each phase’s deliverables. Nothing moves forward until two consecutive review rounds find zero issues. This gates quality at every step. It also prevents AI from carrying errors from one phase into the next.
The test plan document (Phase 3) is the critical node in this pipeline. It receives the architectural design from Phase 2 and outputs the test coverage matrix. Phase 4 test code implements strictly against the matrix. Phase 5 business code targets making every test pass. Skip any link, and everything downstream is built on sand.
Principle: If you can’t write a failing test for a feature, you don’t understand it well enough to start writing code.
Reflection
“Tests are executable requirements specifications” — this idea isn’t new. Kent Beck wrote it in 2002 [2]. But in the context of AI-assisted development, it takes on a new urgency.
In traditional development, the cost of vague requirements is rework. Human developers ask questions, discuss ambiguities, and catch errors during coding. AI does none of this. It takes a vague requirement and outputs code. Fast enough that you can’t correct it mid-process. By the time you spot the drift, a pile of code already needs rewriting. The cost of throwing it out is far higher than the cost of defining requirements precisely upfront.
So the test plan document’s role changes in AI development. It’s not just a reference during the development phase. It’s the final arbiter of requirements. Requirements documents can be ambiguous. Technical designs can have gaps. But test cases are binary. A test passes or it doesn’t. That certainty is the only anchor in the face of AI’s speed.
Two failed refactors of Aristotle taught me: “tests passing doesn’t mean requirements are met, and side effects fixed doesn’t mean the feature works.” That lesson produced tdd-pipeline and the “test plan document before test code” workflow. It also produced this series of articles.
Honestly, not every project needs the full test plan document workflow. A 50-line script, a simple CRUD endpoint — writing test code directly is fine. The value of this method scales with project complexity and AI involvement. When the volume of AI-generated code exceeds what you can review line by line, the test plan document goes from “nice to have” to “can’t ship without it.”
Series Preview
This article covered the test plan document. The pipeline has other stages, each with its own pitfalls:
- Requirements layer: The GEAR protocol — LLMs have no natural incentive to question requirements. You must eliminate ambiguity upstream.
- Design layer: Mapping PRD to technical design — skip this step, and AI fills the gaps on its own.
- Review mechanism: The design philosophy behind the Ralph Loop — AI errors are systematic, demanding structured review, not ad-hoc feedback.
- Full pipeline summary: One diagram from requirements to code — strict process has a marginal cost that drops with project complexity and becomes necessary as AI involvement grows.
One sentence: Test cases are the most precise language you can give an AI. Before letting an AI write a single line of code, figure out how you’ll verify it.
References
- For the testing illusion in Aristotle’s initial version, see From Scars to Armor: Harness Engineering in Practice
- Kent Beck, Test-Driven Development: By Example, Addison-Wesley, 2002
- For Aristotle’s eight-category error taxonomy, see Aristotle: Teaching AI to Reflect on Its Mistakes
- tdd-pipeline source code: https://github.com/alexwwang/tdd-pipeline
- ISO/IEC/IEEE 29148:2018, Systems and software engineering — Life cycle processes — Requirements engineering
- Gojko Adzic, Specification by Example, Manning Publications, 2011