in “Taming AI Coding Agents with TDD.” The first covered test-driven requirements anchoring, the second introduced the GEAR protocol for disambiguation, the third laid out what the tech spec must nail down. This one covers the last line of defense: review.
The Problem the Tech Spec Cannot Solve
Article 3 ended with an uncomfortable admission. The PRD locks down “what to build.” The tech spec locks down “how to build it.” Together they compress the AI’s improvisation space down to implementation details. That is a huge improvement.
But the tech spec itself is a collection of assumptions. Platform API behavior, framework limitations, dependency interfaces — these are factual claims generated by AI or, at best, verified once by a human. A single tech spec for a project like Aristotle contains at least a dozen such claims. Checking each one by hand takes more time than writing the spec.
The problem in one sentence: structured documents shrink the error space. They do not solve the trust problem.
We need a mechanism that systematically audits every deliverable at every stage — without a human reading every line.
Why Glancing at the Output Does Not Count as Review
The common move is “ask the AI to review its own work.” Same session, same context. The AI finishes coding, then you prompt it to go back and check. Two problems with this.
Problem one: the AI reviewing its own work has confirmation bias. The AI that wrote the code already made a chain of implicit assumptions — “this API parameter exists,” “this framework supports async callbacks,” “this data structure is thread-safe.” When the same AI reviews its own output, it validates conclusions using the same assumptions. If the assumption is wrong, the review will not catch it.
Problem two: line-by-line human review creates the illusion of thoroughness. When a person reads an AI-generated document, checking each factual claim one by one, attention starts to decay around the third item. By the tenth item, even obvious errors slip through. This is not a discipline problem. It is a structural limit of human attention.
Both problems share a root cause: AI errors are not random. They are systematic. A single wrong assumption — say, task() supports async execution — does not affect one module. It spreads. The reflection module uses it. The notification module uses it. The state manager builds on it. Spot-checking catches random errors. Systematic errors need systematic review.
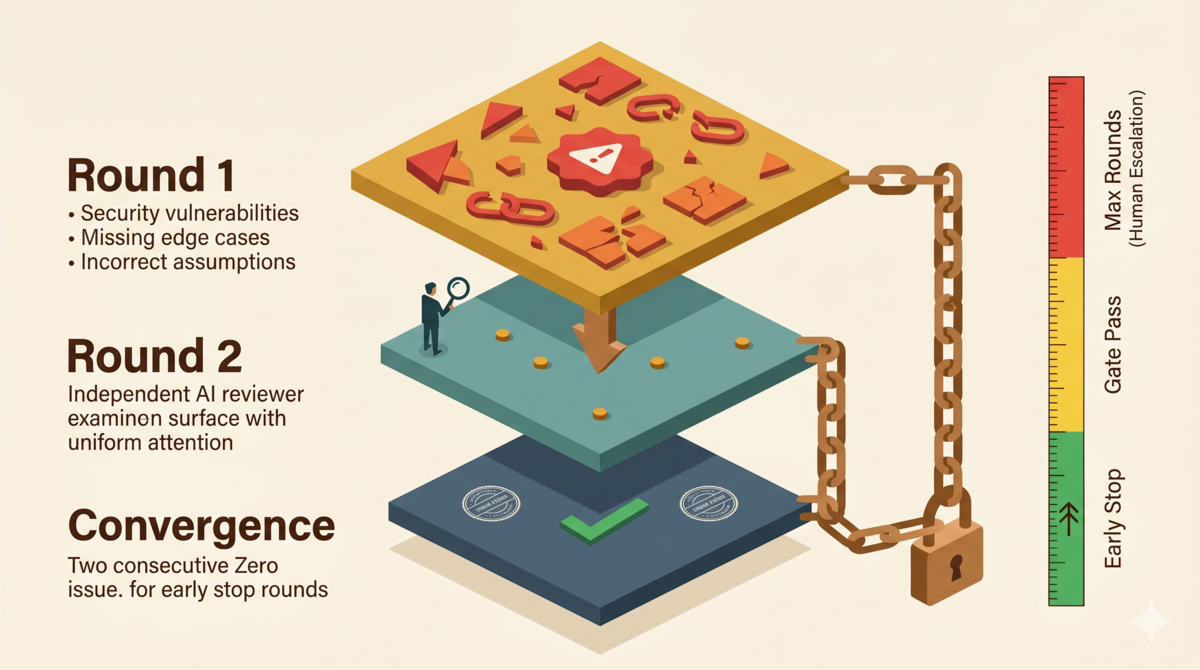
Ralph Loop: Multi-Round Convergent Review
Ralph Loop is the review protocol defined in the tdd-pipeline project[1]. Three elements make it work.
1. Independent Reviewer
The reviewer must be a different AI session from the creator. The reviewer did not participate in building the deliverable, so it does not inherit the creator’s implicit assumptions.
In practice: the main session’s AI writes the code. A subagent launched via task() reviews it. Both can read the project files. Neither shares conversation history.
2. Severity Grading
Every issue found must carry a severity label:
| Level | Meaning | Action |
|---|---|---|
| Critical | Fundamental error; deliverable unusable | Must fix immediately, blocks progress |
| High | Major defect; severely weakens deliverable | Must fix this round, does not block parallel work |
| Major | Violates requirements or best practices | Must fix before delivery, can defer to next round |
| Low | Minor improvement, style issue | Optional |
| Info | Observation, suggestion, no defect | No action needed |
The grading defines exit conditions. Only when C/H/M reach zero can the review end. L and I can carry into the next stage. The distinction between the top three levels is urgency: Critical blocks now, High blocks this round, Major can wait one round.
3. Three Exit Paths
Ralph Loop has three outcomes:
1. Early Stop: 2 consecutive rounds with zero issues (C/H/M/L all zero) → pass immediately
2. Gate Pass: From round 5 onward, current round has C/H/M = 0 (L acceptable) → pass
(Most reviews converge in 3-4 rounds. Rounds 5+ with only L-level noise is normal tail behavior.)
3. Max Rounds: After 10 rounds, C/H/M issues remain → pause, escalate to human
If reviewer and creator disagree on severity — reviewer marks Major, creator says it is just style — the protocol sides with the reviewer. The reviewer has the independent perspective. The creator has confirmation bias. If the creator believes the reviewer misjudged, they can present evidence in the next round for reassessment. Max Rounds is itself an escalation mechanism: 10 rounds without convergence means the disagreement cannot be resolved between AIs. A human must decide.
The most important detail is the Early Stop condition: two consecutive clean rounds. Not one. Two.
Typical Error Patterns by Pipeline Phase
Ralph Loop does not apply a flat review. Each pipeline phase produces distinct error types. The review focuses accordingly.
Requirements Phase (Phase 1)
The most common AI mistake: treating vague requirements as precise ones.
“The system should respond quickly” — the AI interprets “quickly” as 200ms, the most common threshold in its training data. It does not ask the user what “quickly” means. The reviewer must check: is every acceptance criterion testable? Is every criterion a binary pass/fail? Does any criterion contain subjective adjectives?
Design Phase (Phase 2)
The most common AI mistake: designing around APIs that do not exist.
Coroutine-O’s task(run_in_background=true) is the textbook case[2]. The reviewer must check: for every decision involving a platform API, is there an investigation conclusion? Does the conclusion cite its source?
Test Phase (Phase 3)
The most common AI mistake: writing happy-path tests and skipping edge cases.
Coroutine-O Round 1 uncovered missing coverage: empty results, empty workflow_id, malformed JSON — all boundary conditions the AI skipped by default. The reviewer must check: does every acceptance criterion have edge-case tests?
Code Phase (Phase 4-5)
The most common AI mistake: security holes and flaky tests.
Coroutine-O Round 1 found a workflow_id path traversal vulnerability. The AI concatenated user input into a file path without validation. This pattern is rare in training data — most code does not handle malicious input — but fatal for any user-facing API. The reviewer must check: is all external input validated? Are there injection risks?
Why Two Clean Rounds, Not One
This is the most easily overlooked design decision in Ralph Loop. Why does one clean round not suffice?
Real review data from the Coroutine-O merge task[2]:
Round 1 found 26 issues across 5 categories:
| Category | Count | Typical Issue |
|---|---|---|
| Security vulnerability | 1 | workflow_id path traversal |
| Data integrity | 1 | Non-atomic write risking corruption |
| Error handling | 2 | Silent failure, unknown event type returning done |
| Injection attack | 1 | Prompt injection in O_INTENT_PROMPT |
| Test quality | 3 | Flaky timestamp test, flaky latency test |
| Test coverage | 4 | Missing empty result, empty workflow_id boundary tests |
| Other | 14 | Duplicate assertions, gitignore checks, etc. |
After fixing all 26 issues, Round 2 found 0 new issues. All 16 fixes passed verification. No regressions. Under a “one clean round and you’re done” rule, this review ends here.
But what if Round 1’s fixes introduced new problems? The developer patches the path traversal with a regex, but the regex itself is wrong. This “fix one bug, introduce another” pattern is common in AI-generated code. A single clean round could be a false negative: the reviewer happened not to cover the new issue, or the fix’s side effects are invisible in the current review dimension.
Two consecutive clean rounds rule out this false negative. The first zero proves the previous round’s fixes introduced no new issues. The second zero proves the first round’s review itself missed nothing. Double confirmation of convergence.
Structural Isomorphism with Cauchy Convergence
This wasn’t just a gut call. It has a direct structural isomorphism with the Cauchy convergence criterion from mathematical analysis[3].
The Cauchy criterion states: a sequence {aₙ} converges if and only if, for every ε > 0, there exists N such that for all m, n > N: |aₘ − aₙ| < ε. In plain language: convergence is not about how close a particular term is to the limit. It is about how close any two sufficiently distant terms are to each other.
Map Ralph Loop review rounds onto a sequence: {a₁, a₂, a₃, …}, where aₙ is the number of issues found in round n. We want this sequence to converge to zero.
One clean round means aₙ = 0. This does not prove convergence — aₙ₊₁ could be positive, and the sequence is still oscillating. Two consecutive clean rounds means aₙ = aₙ₊₁ = 0. The difference between consecutive terms is zero. This captures the core intuition of the Cauchy condition: we are not checking the distance between aₙ and the limit (the limit is unknown). We are checking the distance between terms. And because issue counts are non-negative integers, two consecutive zeros make further deviation impossible without an external change — this effectively satisfies the Cauchy condition.
The tdd-pipeline protocol document explicitly lists “common mistakes”[1], the most frequent being treating one clean round as an early stop:
❌ Wrong: Round 3 = 0 issues → stop
Reason: 1 zero round is not early stop, need 2 consecutive
❌ Wrong: Round 3 and Round 5 both = 0 → early stop
Reason: Round 3 and Round 5 are not consecutive, Round 4 breaks the sequence
These mistakes are all variations on the same error: using non-consecutive rounds or a single round to declare convergence.
Why Not Three Rounds
If two rounds are better than one, is three better than two?
In theory, yes. In practice, every review round costs tokens and time. Two-round confirmation has a low enough false-negative rate in real use. Coroutine-O’s Round 2 was completely clean. Bridge Plugin (another project in the Aristotle ecosystem) had a 6-round review ending with 2 consecutive clean rounds. Both cases support the effectiveness of two-round confirmation.
This aligns with the engineering principle of “two independent verifications.” Cryptography uses two independent entropy sources to confirm randomness[4]. Aerospace uses two independent sensors to confirm state[5]. Two independent confirmations drive the false-positive rate to an acceptable level. The marginal return of a third confirmation does not justify its marginal cost.
A Complete Pipeline Dataset
The Coroutine-O data above shows single-review convergence. Here is a different project — a Python data backfill service[6] — that ran the full tdd-pipeline across all five phases:
Reviewer roles: Oracle and Council are agent roles provided by OMO-Slim (a lightweight version of oh-my-opencode). Oracle is a single AI reviewer responsible for deep code review, architecture analysis, and issue discovery — like having a senior architect do your CR. Council is a multi-model consensus mechanism that calls multiple AI models to independently review the same deliverable and synthesize a consensus report — used for architecture decisions that need multi-perspective validation.
| Deliverable | Reviewer | Rounds | Result |
|---|---|---|---|
| Product Design v2.0 | Oracle | 12 | ✅ Pass |
| Technical Solution v1.1 | Oracle + Council | 5 | ✅ Pass |
| Test Plan v1.2 | Oracle | 4 | ✅ Pass |
| Test Code | Oracle | 2 (early stop) | ✅ Pass |
| Implementation Code | Oracle | 2 (early stop) | ✅ Pass |
Final verification: 1,219 tests passed, Pyright type check 0 errors.
Two observations:
- Rounds decrease as the pipeline advances. Product design needed 12 rounds because the requirements phase has the highest uncertainty — the boundary of “what to build” only sharpens through review. By the test code and implementation phases, scope is locked. Reviews finish in 2 rounds via early stop. The contrast between early-stage divergence and late-stage convergence is stark. Earlier phases need more rounds.
- The technical solution introduced Council — multiple AI models reviewing in parallel and synthesizing opinions, complementing the single reviewer. Architecture decisions involve multi-dimensional trade-offs (performance, security, maintainability). A single perspective can miss things.
The Core Insight: Review Is Another AI’s Job
Across four articles, this series has built a pipeline: the PRD locks down “what,” the tech spec locks down “how,” the test plan locks down “how to verify,” and Ralph Loop locks down “how to confirm nothing slipped through.”
But Ralph Loop has an implicit premise: the reviewer is another AI, not a human.
The human’s role in this pipeline is decision-maker, not reviewer. The human decides what to build (PRD approval), decides what counts as passing (acceptance criteria), decides what to do at Max Rounds (escalation). The line-by-line code review and fact-checking should go to an independent AI subagent.
This is not because AI review is more reliable than human review. AI attention does not decay. Line 100 gets the same scrutiny as line 1. Human attention starts fading by line 10. For a tech spec with dozens of factual assertions, that difference is decisive.
The essence of Ralph Loop: use AI’s unlimited attention to compensate for limited human attention, use independent review to compensate for self-review’s confirmation bias, use double confirmation to compensate for single-round false convergence.
References
- tdd-pipeline: github.com/alexwwang/tdd-pipeline, ralph-review-loop.md
- Coroutine-O merge dev log: Aristotle repo, branch commit history and internal docs
- Cauchy convergence: Rudin, W. Principles of Mathematical Analysis, 3rd ed., McGraw-Hill, 1976, Theorem 3.11.
- Independent entropy source combination: NIST SP 800-90B, Section 6.3.
- Dual sensor redundancy: RTCA DO-178C, Section 6.4.
- Python backfill service project: internal project, review data from CI build logs.
The Aristotle project is open source on GitHub under the MIT license. Issues and PRs welcome.