in the “Taming AI Coding Agents with TDD” series. The first covered test-driven requirements anchoring, the second covered the GEAR protocol for requirements disambiguation. This one fills the gap between them: after the PRD is done, what must the tech spec cover?
Requirements Locked, Code Still Wrong
Before the second Aristotle refactor, I spent two full days writing requirements. Following the structured approach from the previous article, I captured every acceptance criterion, boundary condition, error path, and platform constraint[1]. The AI consumed the document, passed all 37 static assertions plus end-to-end tests. The codebase was split into four files by responsibility. Information flow was switched from push to pull.
To clarify what “looked correct” means: the first article said the second refactor “solved the context contamination and review breakage problems”[2]—this was relative to the first version’s 371-line SKILL.md. The second version reduced the context load to 84 lines, a significant improvement. But “reduced” is not “eliminated.” Those 84 lines were still injected into the main session, and the async background mechanism still did not work as designed.
I installed it and ran it. The reflection feature still did not do what the requirements described.
The requirements were clear: “Reflection tasks must execute in an independent background session; the main session must not be contaminated.” The AI “understood” this requirement. It called OpenCode’s task(run_in_background=true) API and put the reflection work in a subprocess.
The root cause was missing technical investigation. No one verified before coding: “How does OpenCode’s task() async mechanism actually work?”
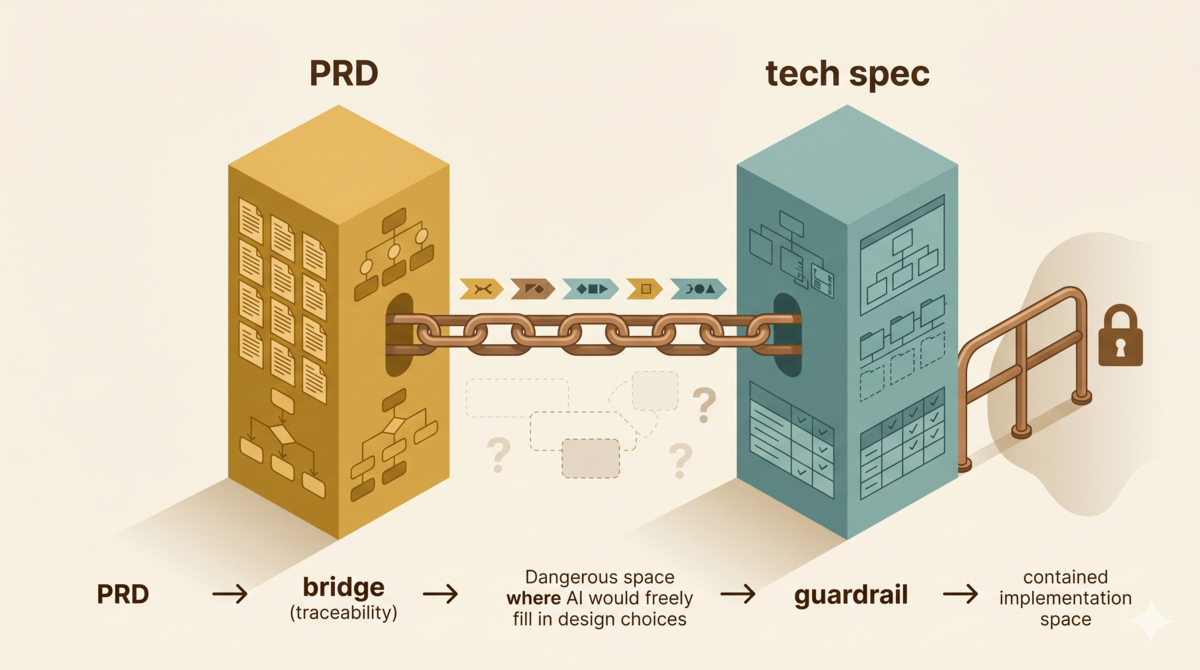
No matter how good the requirements layer is, it only answers what to build. It cannot answer how to build it.
What the PRD Should Cover
The PRD’s job is to define the user-observable behavior boundary—what the user does, how the system responds, where the edges are, what happens when things go wrong.
The tdd-pipeline project’s Phase 1 deliverable includes User Stories (with Priority), Acceptance Criteria (with Edge Cases column), and Constraints & Assumptions[3]. For clarity of exposition, this article separates Edge Cases and Priority into standalone sections, reorganized into five aspects:
1. User Stories
Who wants what and why. Format: As a <role>, I want <goal> so that <benefit>.
For Aristotle’s reflection feature:
| # | Priority | User Story |
|---|---|---|
| US-1 | Core | As a user, I want to trigger error reflection with a single command so that past mistakes inform future sessions |
| US-2 | Core | As a user, I want the main session to remain usable during reflection so that I can continue working |
| US-3 | Secondary | As a user, I want to review generated rules before they take effect so that I maintain control |
2. Acceptance Criteria
Expand each User Story into testable Given-When-Then. Binary—pass or fail, no “mostly passing.”
US-2 (main session remains usable) expanded into acceptance criteria:
| # | User Story | Priority | Acceptance Criterion | Edge Cases |
|---|---|---|---|---|
| AC-1 | US-2 | Core | Given a reflection task is running, When the user sends a new message, Then the main session responds normally and does not contain reflection output | User triggers reflection again while one is running |
| AC-2 | US-2 | Core | Given a reflection task has completed, When the system notifies the user, Then the notification content does not exceed 200 characters | Notification content when reflection fails |
3. Edge Cases & Error Scenarios
AC-2’s Edge Case already flagged “when reflection fails.” A formal PRD expands each criterion’s boundary conditions into standalone items:
- Reflection session creation fails → display error, prompt retry
- Rule generation times out → save draft, notify user for later processing
- User corrects multiple times in one conversation → trigger reflection only once
- Conversation history is empty → do not trigger reflection
4. Constraints & Assumptions
Declare known limitations and assumptions:
- OpenCode’s
task()creates non-interactive child sessions—review cannot happen in a child session - After reflection completes, the system can only notify the user, not push full output back to the main session—information flow must be pull-based
- Claude Code environment is not currently supported
5. Priority Classification
Every User Story and Acceptance Criterion labeled as core or secondary. Core is must-have; secondary is nice-to-have. This classification drives test depth in later stages—core items get happy path + edge cases + error scenarios; secondary items get basic coverage only.
These five aspects answer “what to build” and “why.” They let anyone reading the document judge whether the feature was built correctly or not.
But they do not answer “how to build it.”
PRD Done Right, Still Not Enough
The second refactor’s PRD did follow this structure. Acceptance criteria explicitly stated “zero main-session contamination” and “async non-blocking.” Boundary conditions and platform constraints were documented.
But the coroutine-O branch—Aristotle’s async orchestration prototype—exposed the PRD’s limit.
The goal of coroutine-O was non-blocking reflection workflows: the user triggers /aristotle, the main session returns immediately, the reflection task runs in the background. The PRD was clear—“zero main-session contamination,” “async non-blocking.” The AI consumed the requirements and started coding.
The problem: the PRD only stated what to build, not how. The AI had to answer a critical design question: what mechanism implements the background task?
The AI found the most common answer in its training data: call task(run_in_background=true). This parameter appears countless times in training data, the most direct implementation path. The AI did not ask: “Does OpenCode’s task() API actually support run_in_background?”
Later platform investigation revealed: OpenCode’s task() does not have a run_in_background parameter at all. The current version of task() is synchronous and blocking—the parent agent waits for the child agent to complete, it does not return immediately. The “non-blocking” requirement in the PRD could not be fulfilled with this approach.
The coroutine-O branch was eventually deleted, but it left a clear lesson:
The PRD locks down “what to build,” not “how to build it.” No matter how precise the requirements document is, it cannot replace the tech spec. AI fills design blanks with training data—if the tech spec does not explicitly state “use this mechanism for background tasks,” the AI defaults to the most common pattern in its training data, even if that pattern does not exist on the current platform.
What the Tech Spec Should Cover
The tech spec’s job is to answer “how to build it.” It takes every acceptance criterion from the PRD and outputs actionable engineering decisions.
The tdd-pipeline’s Phase 2 deliverable template includes Architecture Overview, Component Breakdown, Data Models / API Contracts, Key Decisions, Failure Mode Handling, Non-functional Constraints, Observability Design, Cost Estimation, Priority Downgrade Justifications, and Open Technical Questions—ten sections in total[3]. This article selects the core sections most relevant to AI-assisted development, ordered by necessity.
1. Architecture Overview (mandatory)
Describe component boundaries and data flow. No need for polished architecture diagrams—ASCII art works. The key is letting the reader (including the AI) know what the system consists of and how information flows before writing a single line of code.
Sequence diagram for Aristotle’s reflection flow:
User ──correction──→ Main Session
│
├──→ O (Router)
│ │
│ ├──→ Trigger reflection request
│ │
│ ←─── Return "submitted" (does not wait)
│
Independent Session ←─── Reflection task (background execution)
│
├──→ R generates rule (REFLECTOR.md)
│
├──→ C reviews rule (REVIEW.md)
│
└──→ Git commit rule
User ←──notification─── Main Session (pulls result)
This diagram resolves a critical question: information flow is pull-based. Both the first and second refactors broke this design—the first with full pullback, the second with the AI assuming callback notifications were available.
2. Component Breakdown (mandatory)
Decompose the Architecture Overview into concrete components, each with clear responsibilities, interfaces, and dependencies.
| Component | Priority | Responsibilities | Serves ACs | Dependencies |
|---|---|---|---|---|
| O (Router) | Key | Parse commands, route to appropriate flow | AC-1, AC-2 | MCP tools |
| Bridge Plugin | Key | Async task execution, R→C chain driving | AC-1, AC-2 | promptAsync, idle events |
| MCP Server | Key | Rule lifecycle management, state machine | AC-1 | Git, YAML frontmatter |
Note the “Serves ACs” column—every component must trace back to a PRD acceptance criterion. This is the mapping between PRD and tech spec.
3. Key Decisions (mandatory)
Record the rationale for each key decision and the alternatives rejected.
| Decision | Rationale | Alternatives Rejected |
|---|---|---|
| Bridge Plugin + promptAsync for async | True async non-blocking, zero main-session involvement | task(): synchronous blocking, run_in_background parameter does not exist |
The coroutine-O lesson lives directly in this row. If the second refactor’s tech spec had included this line, the AI would not have defaulted to the task() approach.
Platform investigation is not optional. Every decision involving a platform API must be validated: check official documentation to confirm parameters and behavior, write a minimal script to test key assumptions, record conclusions in the table. These three steps turn “I think this works” into “I verified this works.”
4. Failure Mode Handling (mandatory)
List possible failure scenarios and design responses.
| Failure Scenario | Priority | Design Response |
|---|---|---|
| Child session creation fails | Key | Execute in main session, mark “degraded mode” |
| Rule generation timeout | Key | Save draft asynchronously, notify user for later processing |
| Git repository uninitialized | Peripheral | Auto-detect on startup and initialize |
The PRD’s Error Scenarios listed “what if reflection fails.” The tech spec expands this into concrete design responses—what mechanism saves the draft, what channel delivers the notification, what degraded mode looks like.
5. Non-functional Constraints (project-dependent)
Concurrency, reversibility, data isolation, resource boundaries. Simple projects can skip this, but anything involving multi-process, data persistence, or external APIs must document it.
Aristotle’s key constraints:
| Dimension | Requirement |
|---|---|
| Concurrency | Reflection tasks do not block main session; multiple reflection tasks cannot run in parallel |
| Data isolation | Rule repository isolated via Git; consumers read stable versions via snapshot |
| Operation reversibility | All verified rules can be rolled back via git revert |
6. Observability (project-dependent)
Health indicators, logging strategy, alert conditions. Aristotle does not need this currently—the rule repository’s Git history serves as a natural audit log.
7. Cost Estimation (project-dependent)
Infrastructure, third-party services, development overhead. Aristotle’s cost is zero—purely local, no external dependencies.
Of these sections, the first four are non-negotiable for any AI-assisted project. The rest depend on project complexity. But one principle holds: every design decision in the tech spec must trace back to a PRD acceptance criterion. Design decisions without provenance are space for the AI to improvise.
From PRD to Tech Spec: The Mapping Logic
The PRD and tech spec are not independent. A bidirectionally traceable mapping exists between them.
PRD: Reflection tasks execute in independent background session (AC-1)
↓
Tech Spec:
Component: Bridge Plugin (Key) → Serves AC-1
Decision: promptAsync for async → Rationale: task() unsupported
Failure: Child session creation fails → Degraded mode
↓
Test Plan:
Verify process isolation is effective
Verify main session context is not contaminated
Verify degraded mode executes per design
This mapping is the core of the Requirements Traceability Matrix (RTM)[4]. Every test case in the test plan traces back to both a PRD acceptance criterion and a tech spec design decision.
Without traceable mappings, the AI freely “optimizes” the design during implementation—swapping option A for option B, changing pull to push—because it cannot see the constraint relationship between design decisions and acceptance criteria. RTM makes these constraints explicit.
The Core Insight: Docs Are Constraint Space for AI
This series keeps returning to one point: AI does not ask questions. When requirements are ambiguous, it does not ask. When design is missing, it does not ask either. It fills blanks with the most common pattern from its training data.
The PRD shrinks the “what to build” blank space. The tech spec shrinks the “how to build it” blank space. Together, the AI’s improvisation space is compressed to implementation details only—this is the range humans can tolerate.
This mechanism reduces the error space, but does not eliminate it. The tech spec itself is a collection of assumptions—if it contains incorrect assumptions, the AI faithfully executes a flawed design. The coroutine-O lesson: the AI and I together assumed a non-existent API parameter.
Since assumptions in the spec may be wrong, who catches them? Verifying each claim one by one—at Aristotle’s scale, the tech spec contains at least a dozen factual assertions—is neither reliable nor sustainable. The PRD may contain errors, tech spec investigation conclusions may be outdated, test plans may miss boundary conditions. Every layer can introduce errors, and humans lack the bandwidth to check every layer.
What is needed is a structured review mechanism: not one person reading end-to-end, but another AI independently reviewing from a different angle, finding factual errors, logical gaps, and missing boundary conditions. Review results must be actionable—not “suggest improvement,” but specific “line X’s claim contradicts the official documentation.”
The next article covers Ralph Loop: a multi-round review mechanism that uses independent AI subagents to review each phase’s deliverable, intercepting systematic errors at every stage.
References
- Structured requirements approach: Why AI-Assisted Development Must Start with the GEAR Protocol, Section 3 “How to Write Requirements”
- Two-refactor experience: Write Test Plans Before Test Code: Requirements Anchoring in AI Development, Section 1 “Prologue: Two Failed Refactors”
- tdd-pipeline project: github.com/alexwwang/tdd-pipeline, Phase 1 (phase-1-product-design.md) and Phase 2 (phase-2-technical-solution.md)
- ISO/IEC/IEEE 29148:2018, Systems and software engineering — Life cycle processes — Requirements engineering.
- Aristotle project repository: github.com/alexwwang/aristotle
The Aristotle project is open source on GitHub under the MIT license. Issues and PRs welcome.