Three articles in. Back to code — and a hard look in the mirror.
The first post, Aristotle: Teaching AI to Reflect on Its Mistakes, covered the design philosophy and a smooth implementation — three commits in one go. The second, claude-code-reflect: Same Metacognition, Different Soil, described the adaptation cost of moving the same philosophy to Claude Code — continuous iteration from V1 to V3. The third, Trust Boundaries: The Same Idea on Open and Closed Platforms, proposed a tiered trust model and a harness engineering framework.
Part three gave us theory. This article returns to code — using Aristotle’s refactoring to validate how those theories land in real engineering practice.
From “Smooth” to “Scars”
The first version of Aristotle was genuinely smooth to implement. Three commits. Complete SKILL.md to test script to README, done in one flow. Not because the problem was simple. OpenCode’s infrastructure solved the hardest parts.
In the first post, I confidently wrote three design principles. The second was “complete session isolation” — “reflection happens in a background sub-session, main session context is zero-pollution, won’t affect current tasks.” I also said “the entire process is transparent to users, won’t interrupt workflow.”
After actually using it, I found those two claims delivered on exactly nothing.
- The main session’s context was not zero-pollution. When
/aristotletriggered, the full 371-line SKILL.md was injected into the parent session. Reflection was supposed to be “isolated metacognition,” but just starting it consumed huge chunks of the main session’s tokens. - When the subprocess finished,
background_output(full_session=true)pulled the entire RCA report back to the parent session. Error classification, root cause chains, suggested rules — all flooded into the working context. The goal was to help the AI understand its limits. The process of understanding ended up disrupting normal work. - The sub-agent session created by
task()is non-interactive — this is OpenCode’s architectural limit. The first version assumed users could jump into the sub-agent’s session for review. In practice, users could only manually open another terminal. The review flow broke in actual use. - The process wasn’t transparent either. Startup popped a model selection dialog, consuming one round of conversation.
Promises vs. reality:
| Promise from Part 1 | Actual Behavior |
|---|---|
| Main session context zero-pollution | Massive context pollution: SKILL.md 371 lines fully injected + RCA report fully pulled back |
| Entire process transparent to users | Immediately demands user choice: model selection popup consumes one conversation round |
| Won’t interrupt workflow | Severely interrupts current workflow: results write directly into the main session. Even opening another terminal for review doesn’t work — because it’s a sub-agent session, review is structurally impossible. The flow is broken. |
Why such a gap between design and implementation?
The root cause: I over-trusted automated test results, so I didn’t test manually. 37 static assertions plus an E2E live test verified that the protocol steps executed in order — Coordinator starts Reflector, Reflector reads session, generates DRAFT. But tests verified “did the protocol execute correctly,” not “are the protocol’s side effects acceptable.” Tests won’t tell you the main session got stuffed with 371 lines of context. Tests won’t tell you users need to open another terminal to review. Tests gave a passing illusion. I thought the design principles had landed. In reality, the principles were violated at step one of implementation.
A self-fulfilling prophecy: “When tools are smooth enough, humans naturally treat review as optional.” Automated tests passing gave me the same smoothness — “protocol works” — and made me feel manual testing was unnecessary. So I skipped examining side effects. Until I used it myself.
Once the root cause was clear, the refactoring direction was obvious. The original design principles weren’t wrong — isolation, transparency, low friction. But the implementation didn’t enforce them. The refactoring isn’t about overthrowing the design. It’s about locking design principles into code structure, making violations structurally impossible.
From Four Problems to One Architecture
The four problems looked independent. But analysis revealed they all point to the same structural defect: the first version used a single agent skill, with no distinction between “coordinator” and “executor” roles and their responsibility boundaries.
- Context pollution: the coordinator doesn’t need to know the executor’s full protocol. But with only one agent role, everything got stuffed into a single skill file, and at runtime all of it was disclosed into the main session’s context.
- Report leakage: the coordinator doesn’t need to see the executor’s full output. But with only one agent, the output was sent back to the main session too.
- Broken review: the executor shouldn’t handle review — it’s non-interactive. But the first version had users reviewing in the executor’s session, only moving the reflection process into a sub-agent session. Because the first version only designed one agent role.
- Wasted attention: the coordinator’s startup flow should be zero-interaction. But the first version used a popup dialog at startup. I didn’t think through this interaction problem. Over-trusted the model and prompt’s ability to produce good design.
This version involved a critical investigation: the broken review. By examining OpenCode’s source code and database evidence, I confirmed that task() creates architecturally non-interactive sessions — all 47 task sessions had exactly 1 user message (the system prompt), none with follow-up interaction. OpenCode’s GitHub Issues #4422, #16303, and #11012 confirmed this too.
This means review can’t happen in a sub-agent session. It must be implemented in the main session. The original implementation idea needs to be scrapped. But the principle stands. What to do? File an issue with OpenCode and wait for them to add user interaction support in sub-sessions? Or change my own design? The answer is obvious.
From this constraint, a natural question: if user review is unavoidable in the workflow, and it can’t happen in a sub-session, what about launching a dedicated main session just for this? If review happens in the main session, the main session needs to know which reflection records exist — that’s the origin of aristotle-state.json. Need to load a specific record’s DRAFT report — that’s the /aristotle review N command. Need to handle confirm, revise, reject — that’s the interactive review flow.
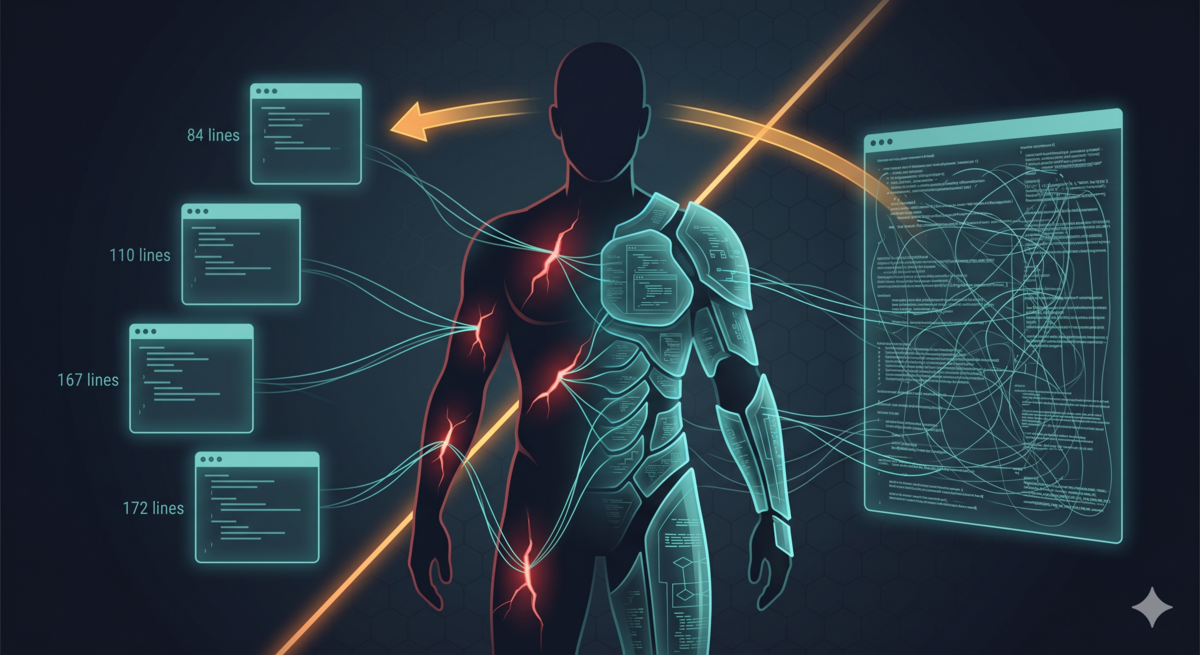
Further: since the review protocol and the startup protocol are only used in different scenarios, was it necessary to put them in the same 371-line file? Do both scenarios need the same content loaded? After splitting by responsibility: routing logic stays in SKILL.md (84 lines), reflection startup logic in REFLECT.md (110 lines), review logic in REVIEW.md (167 lines), sub-agent analysis protocol in REFLECTOR.md (172 lines). Each file is loaded only in its scenario. Context usage drops significantly. The main session’s context pollution is minimized.
After splitting, SKILL.md is just routing logic. But the first version had a model selection popup before startup, consuming one conversation round. Since starting reflection only needs REFLECT.md (+110 lines), the popup is completely unnecessary. Delete it, replace with command-line parameter --model. Default uses the current session model. Advanced users override via parameter. Starting reflection goes from a two-step operation to one.
Finally, information flow. The first version’s background_output(full_session=true) pulled the sub-agent’s complete analysis back to the main session. After refactoring, this call is deleted entirely. When the sub-agent finishes, the main session outputs one line of notification. When users want to review, they actively pull the DRAFT report via /aristotle review N. Information flow goes from “sub-agent pushes everything to main session” to “sub-agent writes state file, user pulls on demand.”
The entire reasoning process distills into three principles:
- Derive architecture from constraints, not from ideal flows. First confirm what the platform can do (task sessions are non-interactive), then design the flow.
- Split by responsibility, load by scenario. Each file corresponds to one clear responsibility. Each scenario loads only what it needs.
- Put the user in the driver’s seat. Notify, don’t push. Pull, don’t inject. Command-line parameters, not popups.
First Constraint: Context Boundary — 371 Lines to 84
Direct approach: split the 371-line SKILL.md monolith into four on-demand files.
| Scenario | Files Loaded | Lines |
|---|---|---|
| Command routing | SKILL.md | 84 |
| Starting reflection | SKILL.md + REFLECT.md | 194 |
| Reviewing rules | SKILL.md + REVIEW.md | 251 |
| Sub-agent analysis | REFLECTOR.md | 172 |
When /aristotle starts, only the 84-line routing file loads. The complete analysis protocol only goes to the sub-agent. The main session is protected from the start.
Implementation: the Coordinator passes the REFLECTOR.md location to the sub-agent via the SKILL_DIR environment variable, not by inlining the full protocol. The sub-agent receives the prompt and reads the file itself.
The first version had no context boundary between main session and sub-agent — the sub-agent’s protocol was unconditionally injected into the main session’s context. After the fix, each scenario loads only the minimum information it needs. Think of hiring an external auditor. The auditor needs to see all the books. But you don’t need the auditor’s working papers spread across your desk. You need the conclusion, not every page of scratch paper. Reflection is a post-incident activity. It shouldn’t interfere with ongoing incident response.
Git commit 39dffae completed this refactoring. 371 lines to 84 lines, a 77% reduction. Functionality didn’t decrease — it increased (the --focus parameter, state tracking, cross-session joint reflection, revision of already-written rules).
Second Constraint: Information Flow — One-Way Completion Notification
Delete the background_output() call entirely. When the sub-agent finishes, the parent session outputs one line:
🦉 Aristotle done [current]. Review: /aristotle review N
The parent session no longer retrieves any analysis content. Review happens via /aristotle review N in a dedicated review session — REVIEW.md (167 lines) loads, reads the DRAFT report, and presents it for user confirmation.
Information flow went from bidirectional to strictly one-way: sub-agent → state file → user actively pulls.
The DRAFT marker means “pending verification.” Users must see it with their own eyes, manually confirm, before rules land. Part three asked the Level 0 trust question: “how much authorization can this model’s RCA quality support right now?” The answer: not enough for fully automatic writing.
Another consideration: when the sub-agent finishes, it triggers a completion notification. If the main session is processing another user request at that moment, the analysis report flooding in will disrupt current work. One-way notification plus user pull hands information flow control to the user.
Interestingly, writing this I realize: claude-code-reflect’s /reflect review was forced (platform limitation), while Aristotle’s /aristotle review N is an active choice. Even if OpenCode had no limitations, after thinking it through I’d still design it this way — launch a dedicated main session to review DRAFTs — rather than the original approach of pulling up each sub-session individually.
How this design is implemented on OpenCode is worth explaining. Quite interesting.
Third Constraint: Architectural Reality — Review Returns to Main Session
This was the most convoluted problem.
The core issue: OpenCode’s task() creates non-interactive sessions — GitHub issues and database evidence both confirm this. The first version’s “user jumps into sub-session to review” flow wasn’t feasible in practice.
The solution wasn’t to bypass the limitation (like claude-code-reflect’s bypassPermissions). It was to acknowledge the limit and redesign the flow:
- Sub-agent only does analysis and generates DRAFT — no user interaction
- Leverage OpenCode’s openness and trust: review happens in the main session via
/aristotle review N - Introduce
~/.config/opencode/aristotle-state.jsonstate tracking file to manage reflection record lifecycle - Support multiple reflections, distinguished by serial number. Users find scenarios worth re-reflecting via
/aristotle sessions(in real life, we also occasionally recall mistakes we’ve made before, don’t we?)
State flow: draft → confirmed → revised (allows re-reflect for re-analysis)
Sub-agent does analysis. Main session does review and writing. This separation isn’t a forced compromise. OpenCode’s non-interactive task session limit looks like a platform constraint on the surface. Underneath, it’s a healthy architectural boundary: agents executing sub-tasks should maintain independent context, free from main session interference.
Compare with Part two’s claude-code-reflect. On Claude Code, this separation was achieved through V2→V3’s “move writes to resumed session” — lots of detours. On OpenCode, the platform’s architectural limit guided us directly to the correct separation.
A deeper observation: how much a platform trusts developers, and how much users trust AI — sometimes these align, sometimes they oppose. In Aristotle’s scenario, they aligned. OpenCode’s openness lets you make separation cleaner. Level 0 trust design requires exactly that cleanliness.
Fourth Constraint: Minimizing User Attention Cost
Simplest fix. Clearest principle.
Delete the question tool popup. Replace with command-line parameter: /aristotle --model sonnet. Unspecified defaults to current session model.
Small change. The principle behind it isn’t small: starting reflection should be low-barrier. Every added interaction step reduces the probability that users will start reflection. Model selection is an advanced need for different scenarios. Worth providing to users. Not worth making part of the default flow. So the configuration moves to startup time rather than asking again after launch. In real life, we also prefer working with people who explain the situation upfront, rather than asking permission at every step.
The first version used an interactive popup — every time relying on the user to make a choice. After changing to command-line parameters, “no popup” is structurally guaranteed. The default doesn’t depend on user judgment.
All Four Together: Progressive Disclosure Architecture
The four fixes aren’t isolated. Together they form Progressive Disclosure.
The final architecture diagram:
Reflect Phase Review Phase
───────────── ───────────
/aristotle /aristotle review 1
│ │
├─ Load REFLECT.md ├─ Load REVIEW.md
│ (110 lines) │ (167 lines)
│ │
├─ Fire Reflector ──────► ├─ Read Reflector session
│ (background task) DRAFT │ Extract DRAFT report
│ ──────► │
├─ Update state file ├─ Present DRAFT to user
├─ One-line notification ├─ Handle confirm/revise/reject
└─ STOP ├─ Write rules on confirm
└─ Re-reflect if requested
371 lines to 84 lines, a 77% reduction. Functionality didn’t decrease — it increased (the --focus parameter, state tracking, cross-session joint reflection, revision of already-written rules).
Four files in the final structure:
- SKILL.md (84 lines) — routing layer, parameter parsing and phase dispatch
- REFLECT.md (110 lines) — reflection phase protocol, sub-agent startup and state tracking
- REVIEW.md (167 lines) — review phase protocol, DRAFT review, rule writing, revision
- REFLECTOR.md (172 lines) — sub-agent analysis protocol, error analysis, DRAFT generation
Test assertions expanded from 37 to 63, covering file structure, progressive disclosure, SKILL.md content, hook logic, error pattern detection (Chinese and English), and architectural guarantees.
Every layer of this architecture is a product of trust judgments:
- File splitting: don’t trust the parent session to absorb the sub-agent’s full context impact without problems
- One-way notification: don’t trust users to immediately handle asynchronous information from the sub-agent
- Main session review: don’t trust the sub-agent session to properly handle user interaction — and it shouldn’t
- No popup by default: don’t trust user attention to be unlimited
But “don’t trust” here isn’t negative judgment. It’s precise trust calibration — each component is trusted to do what it’s best at, not trusted to do what’s beyond its capabilities. Think of a symphony orchestra. It’s not that you don’t trust the horn player to play violin. Each section keeps to its own score. When it’s your solo, you get the full part (REFLECTOR.md, 172 lines). When it’s not your turn, you only need to know what’s next (SKILL.md, 84 lines). Nobody needs the full score.
Back to the Origin: Trust-Driven Design Tradeoffs
Part three proposed a harness engineering framework: “between users, tools, and language models, let trust relationships drive architectural decisions — not the other way around.” Part four validates this framework through Aristotle’s refactoring.
The trust curve across both projects:
| Phase | Trust Judgment | Code Manifestation |
|---|---|---|
| First Aristotle | Implicit trust — didn’t consider boundaries | 371-line full injection, full report retrieval |
| Discovering problems | Trust calibration — realized boundaries were missing | Promise vs. reality comparison, four architectural defects exposed |
| Refactoring Aristotle | Active constraints — lock boundaries with code structure | Progressive Disclosure |
| claude-code-reflect | Constrained choices — platform limits shape the design | bypassPermissions, resumed session |
Two paths, same destination. Both converge to: sub-agent analyzes, main session reviews, user approves. The difference is, on OpenCode you have the opportunity to actively choose the correct constraints. On Claude Code, you’re forced to find workarounds under platform limits.
An open question: as model capabilities improve, Aristotle’s DRAFT report quality will gradually improve. When trust shifts from Level 0 to Level 1-2, does Progressive Disclosure architecture need to change?
Probably no. Even if sub-agent output quality is high enough, context isolation still has value. You trust the output quality. You don’t trust asynchronous information influx disrupting the main session. These two trust dimensions are independent.
Closing
Four scars became a set of armor.
Not every scar becomes armor. Some problems need platform-level support — like interactive capability for sub-agent sessions, auto-notification mechanisms. Some constraints under the current architecture can only be mitigated, not eliminated.
But when trust judgments can be transformed into code structure, scars become armor’s raw material. Progressive Disclosure isn’t about showing off architectural skills. It’s about solidifying trust relationships into verifiable code constraints. The boundary between main session and sub-agent, one-way information flow, main session review, no popup by default — every constraint is a concrete trust judgment.
Aristotle and claude-code-reflect aren’t about “which is better.” They’re two points on the same trust curve, twins that inspire and iterate on each other. The real question was never “whether there should be human in the loop.” It’s: how much authorization can this model’s reliability on this task in this environment support right now?
As model capabilities improve, that answer will change. Checkpoints will shift backward. Automation will increase. Review frequency will decrease.
But deciding “it’s time to shift” — that’s always human responsibility.
Aristotle project: https://github.com/alexwwang/aristotle