The previous article, From Scars to Armor: Harness Engineering in Practice, ended with Aristotle having a streamlined router (SKILL.md compressed from 371 lines to 84), an on-demand progressive disclosure architecture, and a working reflect→review→confirm workflow.
But one thread never got pulled: Where do confirmed rules actually live?
This article follows that thread. It wasn’t planned from the start. Three concrete problems in actual use forced the design out, step by step.
First Hurdle: The Append-Only Trap
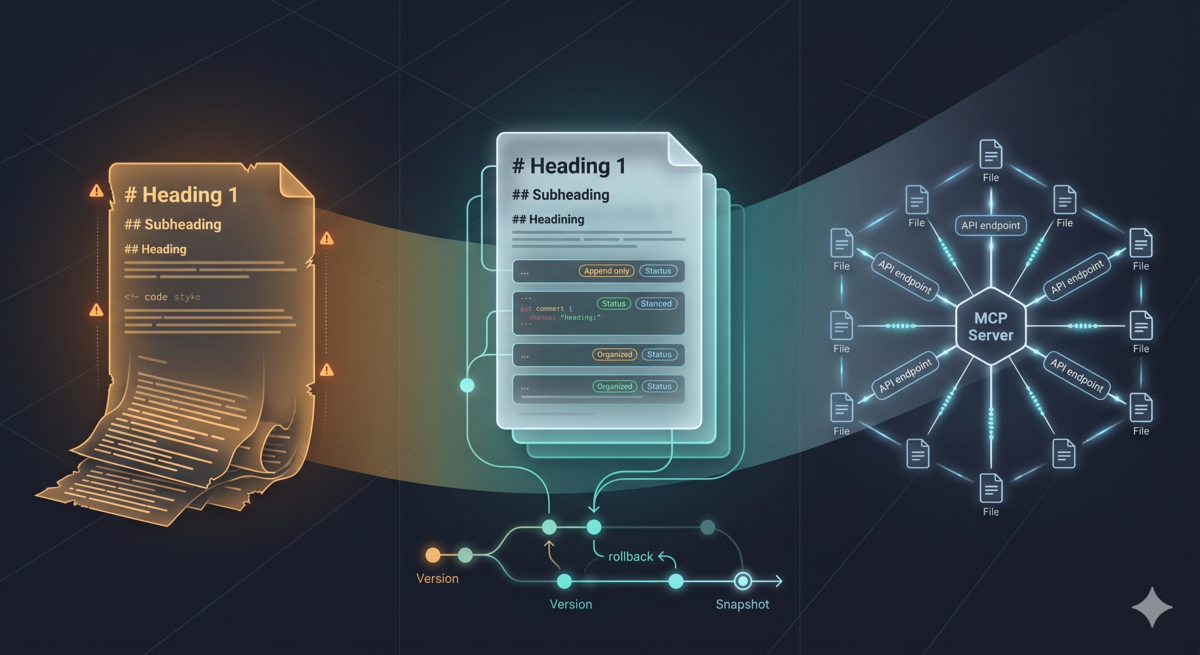
Aristotle’s reflection ultimately writes a rule — a Markdown snippet telling future AI sessions “how to handle this type of situation.” The initial implementation was crude and brutal: all rules appended to ~/.config/opencode/aristotle-learnings.md, a single file constantly growing with new rules.
This approach worked. But after two weeks of use, three problems surfaced.
Problem One: No Way to Roll Back
One day AI generated a rule: “pandas groupby results must be processed with .reset_index() for proper serialization.” The rule itself wasn’t wrong, but the trigger condition was written too broadly. Subsequent simple aggregation tasks forced reset_index() calls too, which actually broke multi-index structures. Once confirmed and written, every subsequent session read that rule — until I manually opened the file, found that rule, deleted it.
This wasn’t as simple as “delete one line.” Finding a specific rule in mixed Markdown content requires visual scanning. Delete the wrong one, and there’s no git history to recover. Rules were immutable — once written, they stayed there until manual intervention.
Problem Two: Project-Level Rules Scattered Everywhere, No Unified Management
The first design did distinguish between user-level and project-level — user-level rules in ~/.config/opencode/aristotle-learnings.md, project-level rules in each project’s .opencode/aristotle-project-learnings.md. Separating the two files was the right idea.
But after separation, both had identical dilemmas — both append-only, neither had version control. Worse, project-level rules were scattered. When I accumulated five lessons across ten projects, those fifty rules were distributed across ten different directories. Searching and managing became a nightmare. Want to check “which project previously hit a data leak pitfall”? You had to flip through directories one by one.
Problem Three: No Structure Between Rules
Dozens of rules laid flat in a Markdown file, each just a heading plus a few lines. No category tags, no confidence scores, no “how this rule came to be.” When I wanted to find “all lessons related to data cleaning,” I had to keyword search — but the wording AI used when generating rules, and the wording I used when searching, often didn’t match. Rule says “null value handling omission.” I search for “missing values.” No match.
Common root of all three problems: flat append-only files can’t support “stateful knowledge management.” Even with user-level and project-level separation, without version management, without structured metadata, without unified search entry points, separation is just physical isolation, not true governance capability.
Second Hurdle: Why Git? Four Decision Points
My first thought for improvement wasn’t Git. But code is text, rules are text too — why can’t rules have version management like code?
“Feels right” and “stands up to scrutiny” are different things. In repeated discussions with AI, introducing Git went through four key decision points. Each solved a physical determinism problem in multi-agent collaboration.
Decision One: Version Rollback — The “Undo Button”
What if agent B produces hallucinations or logic errors when reviewing agent A’s output rule and corrupts the file? If we wrote our own version management — like backing up .bak files before each change — complexity would spiral: how to manage backups of backups? How to diff between multiple versions?
Git is the world’s most mature “undo button” system. git revert or git checkout can roll back to any historical version in seconds, zero extra cost.
Decision Two: Physical Isolation of Read-Write Conflicts
When one agent is writing a rule file, another agent trying to read might read “half-written” incomplete content. In single-process software this isn’t a problem, but in environments where multiple AI sessions run in parallel, it’s a real risk.
Git’s staging area and commit history naturally provide logical isolation. Write operations happen on disk, read operations use git show HEAD:file to read directly from Git’s object store for the previous stable version. This Snapshot Read eliminates read-write conflicts — readers and writers always see different versions.
Decision Three: From “Modify File” to “Commit Transaction”
Simple file state marking (writing status: pending in text) isn’t reliable. Physical state and logical state can decouple — file exists on disk, but status flag is wrong; or status flag is right, but file content got accidentally overwritten.
We need to make “modify file” and “activate file” two independent actions. git commit is essentially an atomic transaction. Only after commit does a rule become “officially live” in the system. Anything uncommitted is considered untrusted. This provides consumers with an absolutely reliable boundary.
Decision Four: Lightweight and Transparent
I evaluated SQLite. Databases are stronger on query capability, but have two fatal flaws: invisibility — you can’t directly open the database with a text editor to see rule content, debugging and audit costs are high; deployment cost — needs extra runtime dependencies.
Git is file-based. You can directly open folders to view .md content while gaining database-level version control. This transparency — visible and tangible — is crucial for an early system with frequent debugging.
Common Conclusion of Four Decisions
Choosing Git actually solved four engineering problems — version control, physical isolation, transaction mechanism, audit traceability — through one lightweight existing tool. A tool users already have.
On this “secure foundation” Git provides, subsequent designs like atomic writes, state machines, read-write separation have something to build on.
Third Hurdle: Git-Backed Filesystem Design Details
Atomic Writes
When rule files write to disk, I use “temporary file + rename” strategy — first write to a .tmp file, then os.rename() to replace the original. This guarantees two properties:
- Other processes (including simultaneously running AI sessions) never read “half-written” files.
- Even if a crash happens during write, the original file stays intact.
Sounds like over-engineering? Actually not. AI agents often run in parallel across multiple sessions. If session A is writing a rule file and session B happens to be reading at the same time, without atomic write guarantees, B might read incomplete content, then make decisions based on that incomplete content. This isn’t theoretical risk. It’s a problem encountered in actual use. Common in database write scenarios — that’s why databases use locks. Given reflection content written to files will be larger and the same reflection file won’t update frequently, I chose not to use locking for lightweight non-blocking reasons.
State Machine
Rules no longer have just one “written” state, but a full lifecycle:
pending → staging → verified
↘ rejected (recoverable)
pending: rule just generated, not reviewed yet. File exists on disk, but not in Git.staging: reviewer is checking. This step “locks” the rule to prevent modification while reviewer is working.verified: review passed, executegit add && commit. This is terminal state — consumers only see rules in this state.rejected: review failed. But not deleted — moved torejected/directory, preserving all metadata, can be restored later.
Why preserve rejected rules instead of deleting directly? Because I discovered some rejected rules aren’t “completely wrong,” but “not applicable in specific scenarios.” Keeping them lets future restore reactivate them, rather than regenerating from scratch.
Read-Write Separation
When consumers (future Agent L) read rules, they don’t read files on disk directly, but by using git show HEAD:file to read Git committed snapshots. This means consumers only ever see verified state rules, never read producer’s half-written drafts.
Read-write separation is a key design decision. It doesn’t solve performance problems. It solves trust problems — consumers don’t need to trust disk file state, only Git commit history. Git commit’s atomicity became the contract between producer and consumer.
Cold Start
First run, system detects old aristotle-learnings.md file, automatically executes migration: parse old Markdown format, generate YAML frontmatter for each rule (including status, category, confidence, etc.), write to Git repo. After migration completes, old file renamed to .bak backup.
Migration isn’t as simple as “cutting old files into pieces.” Old rules have no structured metadata, need heuristic inference — parse error categories from Markdown headings, extract rule summaries from paragraphs. Inference isn’t necessarily accurate, so during migration confidence defaults to 0.7 (conservative), verified_by marked as "migration", convenient for later manual review.
These design ideas came from repeated discussions with AI. I saved nine discussion records total. From initial “Git-MCP skill management plan” to finally converging on “GEAR protocol spec,” step-by-step iteration, each step recording the problems at that time, design decisions, and reasons for those choices.
Fourth Hurdle: Why MCP Server?
With design direction, next step is implementation. A key technical selection question: where should these Git operations execute?
Most direct approach: write bash commands in SKILL.md — let AI agent call git add and git commit itself. But I quickly excluded this option for three reasons:
Reliability. AI-generated git commands can have spelling errors, path errors, even destructive operations (like accidental
git reset --hard). The rule repo is user’s long-term knowledge accumulation. One wrong git command can destroy entire history.Consistency. Every rule write needs to execute same state checks, frontmatter formatting, atomic write flows. Putting this logic in prompt for AI to execute, consistency cannot be guaranteed — models sometimes “creatively” skip certain steps.
Testability. Flows described in prompts are hard to test automatically.
These three reasons also reflect task characteristics: this is highly deterministic standard action. It can use programs to implement logic, and guarantee quality through test cases, covering every node from initialization to migration to lifecycle management. Wrapping these operations as standardized tools for AI to call on demand is the higher-determinism, safer choice.
So MCP (Model Context Protocol) entered: an independent Python process, communicating with AI agent via stdio JSON-RPC. Agent doesn’t execute git commands directly, but calls MCP-provided tools to achieve goals. After several iterations, defined eight such tools:
| Tool | Operation | Purpose |
|---|---|---|
init_repo | Initialize | Create directory structure, Git repo, migrate old rules |
write_rule | Produce | Create rule file (pending state), write YAML frontmatter |
read_rules | Retrieve | Multi-dimensional combined query (status, category, intent tags, error summary) |
stage_rule | Review | Mark rule entering staging state |
commit_rule | Confirm | Status set to verified, execute git add && commit |
reject_rule | Reject | Move to rejected/ directory, preserve metadata |
restore_rule | Restore | Restore from rejected/ to official directory |
list_rules | List | Lightweight metadata query (doesn’t load rule body) |
Each tool is a deterministic Python function with input validation, error handling, and test coverage. AI agent operates rule repo by calling these tools, but never bypasses tools to execute git commands directly.
MCP Server doesn’t give AI more capability, it adds boundaries to AI’s capability. This design philosophy follows the trust calibration discussed in Part four: not distrusting AI, but narrowing “places where errors can happen” to predictable ranges through structured interfaces.
Fifth Hurdle: Retrieval Dimensions — How to Find “Relevant” Rules?
MCP Server ready, rules have lifecycle, Git version management. But another problem remains: when AI starts a new task, how does it know which rules relate to the current task?
Initial implementation only supported filtering by status (verified) and category (HALLUCINATION and other 8 types). In actual use, I found rules under same category might cover completely different technical scenarios — “HALLUCINATION” can mean “invented a non-existent API method,” or “incorrectly claimed a config item doesn’t exist.” Categories too coarse, not enough. Use large models for semantic comparison directly? That makes MCP tools too heavy and loses MCP tool determinism. So I decided query filtering only uses regex matching, converting semantic comparison to keyword queries.
After consideration, I introduced three retrieval dimensions in query design:
- Intent tags (intent_tags): rule’s applicable technical field (
domain) and specific goal (task_goal). Likedomain: "database_operations",task_goal: "connection_pool_management". - Failed skill (failed_skill): errored tool or skill. Like
failed_skill: "prisma_client". - Error summary (error_summary): one-sentence description of error site. Like
"P2024 connection pool timeout in serverless".
These three dimensions are automatically filled by AI when generating rules. When generating rules, an inference step is added — infer technical field from error context, infer task goal from user’s original request, infer errored tool from involved code.
Retrieval can combine: query “all database operation related” rules, or more precisely query “connection pool management + timeout involved” rules. 500 rules, Phase 1 frontmatter filtering only needs 80ms.
Streaming Filter
Here’s one engineering detail worth mentioning when implementing retrieval. read_rules tool uses two-phase search:
Phase 1: only read the first 50 lines of each file (YAML frontmatter usually ends within first 20 lines), use regex to match KV pairs in frontmatter. Files not matching directly skip, no YAML parsing.
Phase 2: only do complete frontmatter parsing and rule body loading for files hit in Phase 1.
Why two phases? Because YAML parsing is an order of magnitude slower than regex matching. If all 500 rules did YAML parsing, retrieval latency would spike from 80ms to nearly 1 second. Two-phase design excludes “definitely unneeded files” as early as possible, only paying parsing cost where necessary. (Though whether my local system can accumulate to 500 rules, I genuinely don’t know yet.)
Sixth Hurdle: S — Translating Intent to Queries
With three retrieval dimensions, next question: who translates “I want to do database migration” natural language into MCP query parameters?
Answer seems obvious — can’t let L do it to avoid polluting context. Further, natural thought: put it in Agent O, let it handle routing, intent extraction, query construction together. But would this cause SKILL.md context explosion? Especially query construction needs to call MCP service to get reflection results, which returns a lot of content.
So progressive disclosure thought used again (actually I think it’s the same concept as decoupling in programming design, just expressed in different scenarios), query construction extracted as an independent concern, named S (Searcher). S’s input is intent tags (domain: "database_operations", task_goal: "schema_migration"), output is read_rules() parameter dict. S does specific things:
- If it has
domain, setintent_domainparameter. - If it has
task_goal, setintent_task_goalparameter. - If it has
failed_skill, setfailed_skillparameter. - If it has error description, extract 2-3 keywords from it, connect with
|askeywordparameter. - All parameters AND combined, call
read_rules().
S doesn’t do semantic understanding, doesn’t do fuzzy matching — it’s a deterministic parameter constructor.
Here’s a deliberate design choice: S has independent agent identity in the design scheme, but in current implementation it’s just a function call inside O. Not a contradiction — a phased strategy. Query construction is simple enough for now, not worth starting an independent subagent. But if future versions need semantic retrieval (vector matching), cross-repo joint queries, or query result caching, S’s complexity will grow. The agent identity in the design reserves an evolution path from function to independent process.
Lightweight implementation first, protocol layer reservation — entire project’s design philosophy stays consistent.
But S is only one link in retrieval chain. S might return 20 rules — if we throw all to the agent executing user task, those 20 rules’ complete bodies will directly fill context window, main task space squeezed out.
This introduces deeper design question: who stands between L and reflection infrastructure, doing filtering and compression?
So first use O to handle, if future context explosion encountered, can split out another agent to handle filtering tasks, controlling each task’s context length. This uses toolchain thinking to control single node complexity, and context length is intuitive measure of agent task complexity. Phased implementation doesn’t affect architectural principles — next section explains, O in-between isn’t expedient, but architectural necessity for learning chain.
Seventh Hurdle: O’s Expanded Role — From Router to Knowledge Service Provider
O (Orchestrator) in Aristotle’s original design was just a router — user inputs /aristotle, O parses parameters, decides to start reflection or review, then hands off.
But in learning chain, O’s role fundamentally changed. It no longer just distributes tasks, it becomes an isolation layer.
L and O Aren’t the Same Agent
Here’s a pitfall I (and AI helping me design) both stepped in.
Aristotle’s historical implementation had O, R, C roles all completed in same main session context — load SKILL.md become O, load REFLECT.md start reflection, load REVIEW.md do review. All in same agent process.
So when designing learning chain, the AI naturally assumed L was also same agent — “L connects directly to S is fine, O is unnecessary middleman.” It even used CQRS as analogy: commands go through coordinator, queries directly get, as a matter of course.
I corrected this judgment.
L is the agent helping user write code, O is Aristotle this independent reflection skill. They run in different contexts. L’s context should be left to user’s main task as much as possible — any reflection infrastructure details (MCP, frontmatter, query construction) shouldn’t enter L’s context.
This distinction doesn’t matter in P1+P2 phases, because reflection and review themselves are user-initiated operations, occupying main session context is reasonable. But in learning chain, L executes user’s main task — at this point any reflection infrastructure intrusion into L’s context is pollution, and only that reflection rule helping solve current task’s problem is what L needs.
Three Things O Does In-Between
O in learning chain does three things L shouldn’t do:
1. Intent extraction. L says “I want to do database migration, any pitfalls encountered before?” — O infers domain: "database_operations", task_goal: "schema_migration" from this sentence. L doesn’t need to know what intent_tags are.
2. Query construction and execution. O calls S function, constructs MCP query parameters, calls read_rules(), gets raw results. These are reflection infrastructure internal operations, invisible to L.
3. Filtering and compression. S might return 20 rules. O does deduplication, sorts by relevance, keeps at most 5, then compresses each to 3-4 line summary — error description, pitfall avoidance points, positive and negative examples, rule ID. L only sees this refined summary.
L’s perspective is simple: asked a question, received a few lessons. Doesn’t know MCP, doesn’t know read_rules, doesn’t know frontmatter. This is minimal pollution.
A Valuable Mistake
Worth mentioning: the “O is an unnecessary middleman” judgment later got a 5-Why root cause analysis from Aristotle’s own reflection mechanism. The conclusion is telling:
A default negative judgment toward “indirect layers” — assuming every extra coordination layer is unnecessary complexity. This judgment is usually reasonable in general software design, but wrong for Aristotle. Aristotle’s indirect layer isn’t overhead. It’s the product itself. The entire skill exists to make reflection infrastructure invisible to the mainline agent. Remove the layer, remove the product value.
AI made an error while designing a reflection system. The reflection system reflected on that error and generated a prevention rule. Somewhat matryoshka — but that’s exactly the point. Learn from errors, even the designer’s own.
Eighth Hurdle: Role Separation — O, R, C, S, L Each Does Their Job
With S and O’s expanded design, five roles’ complete picture becomes clear:
| Role | Goal | Pursues |
|---|---|---|
| O (Orchestrator) | Coordinate + Isolate | Route correctly, minimize context pollution |
| R (Resource Creator) | Produce rules | Recall rate — better over-generate than miss |
| C (Checker) | Review rules | Precision — format, logic, deduplication |
| S (Searcher) | Intent → Query | Deterministic translation, no guessing |
| L (Learner) | Consume rules | Execute main tasks + avoid known traps |
R and C responsibilities have essential difference — R pursues coverage, C pursues accuracy. When mixed together, the two goals interfere with each other. Role separation isn’t for “division of labor,” but for goal isolation.
More bluntly: R is automated agent, its output might have logical errors even hallucinations. If R-generated rules without review enter production environment — treated as “must-follow lessons” by L — one wrong rule will pollute all subsequent sessions’ decisions. This isn’t assumption, it’s problem I encountered in actual use: R wrote a rule with overly broad trigger conditions directly, L misused it in subsequent tasks, generated new errors. Rule repo’s influence is global, one bad rule’s destructive power far exceeds one good rule’s benefit.
C exists to block this risk. C is system’s only role with git commit permission — R only writes, C can approve. R-produced rules must pass C’s schema validation, format check, deduplication verification, before becoming verified state for L to see. This “production-audit” two-step flow, essentially is software engineering’s Code Review — not distrusting developers, but single perspective blind spots need another perspective to complement.
L and R/C don’t communicate directly, only interact indirectly through Git repo. O is only coordinator — L sends requests to O, O returns summaries to L. L doesn’t know R and C exist.
R only writes, C only reviews, L only learns, O coordinates in-between, S translates. Read-write separation guarantees L never reads R’s half-written drafts. This isolation isn’t over-design — Progressive Disclosure architecture discussed in Part four, essentially is one implementation form of role separation.
Ninth Hurdle: From Implementation to Protocol — GEAR
At this step, Aristotle has a complete rule management system: Git-backed storage, YAML frontmatter schema, state machine, multi-dimensional retrieval, role separation.
When organizing documentation, I realized these designs aren’t limited to Aristotle — any AI agent needing “learn from errors and persist knowledge across sessions” faces the same problems. So abstracted core designs into an independent protocol spec, named GEAR (Git-backed Error Analysis & Reflection).
GEAR defines five roles (O/R/C/L/S), a state machine, a frontmatter schema, and a Δ decision factor. Aristotle is GEAR’s first implementation — O is implemented by SKILL.md + REFLECT.md + REVIEW.md, R by REFLECTOR.md, C by schema validation in REVIEW.md. L and S still in planning.
Δ Decision Factor
This mechanism is part of the GEAR protocol spec but not yet implemented in Aristotle. It is documented here as forward-looking design — the current behavior remains fixed semi mode for all rules.
One mechanism in GEAR still in design — Δ decision factor:
Δ = confidence × (1 − risk_weight)
It decides rule’s path from staging to verified:
| Δ Value | Review Behavior |
|---|---|
| Δ > 0.7 | auto: automatic commit, no manual confirmation needed |
| 0.4 < Δ ≤ 0.7 | semi: show diff, wait for user confirmation |
| Δ ≤ 0.4 | manual: force manual review |
risk_weight determined by error category — hallucination (HALLUCINATION) weight 0.8, syntax error (SYNTAX_API_ERROR) weight 0.2. High-risk rules need more review, low-risk rules can pass faster.
Currently Aristotle fixedly uses semi mode — all rules go through user confirmation. The system is still accumulating data. Success rate statistics aren’t sufficient. It doesn’t have conditions to automatically adjust review levels. After P4 phase implements evolution_stats.json, Δ factor can truly land.
The Δ factor borrows from progressive trust models — not a blanket trust or distrust of AI rules, but dynamically adjusting the review threshold based on confidence and risk weight. Consistent with the “trust calibration” discussed in Part four, and also to let users quantify the risk of being lazy.
Current Status and Next Steps
GEAR protocol implementation currently completed P1 and P2 (first two phases):
- P1 (MCP Infrastructure): 8 tools, YAML frontmatter schema, multi-dimensional retrieval, atomic writes, cold start migration. 75 pytest tests all passing.
- P2 (Aristotle Skill Layer Integration): REVIEW.md refactored to MCP tool call chain, REFLECTOR.md output protocol extension, C role schema validation.
Not yet implemented:
- P3 (Learner + Searcher): let AI automatically retrieve relevant rules before task starts. This is key to GEAR self-healing loop — evolve from “manual trigger reflection” to “automatic learning avoid pitfalls.”
- P4 (Evolution Model): Δ decision factor actual integration, and review level automatic adjustment.
- P5 (Documentation Wrap-up)
Review this design path: from one append-only Markdown file, to Git-backed filesystem, to MCP Server, to GEAR protocol. Every step wasn’t planned in advance, but forced out by concrete problems encountered in actual use.
Rules couldn’t roll back → introduce Git. Read-write interference → introduce read-write separation and state machine. AI directly executing git commands unreliable → introduce MCP Server. No structure between rules → introduce YAML frontmatter and retrieval dimensions. Production and review goals conflict → introduce role separation. Design reusable → abstract as GEAR protocol.
Every step solves one concrete problem. Connected together, this path points to an ultimate goal — self-healing loop:
L executes task → O retrieves relevant rules through S
→ L still makes error after learning → submit error report to O
→ O pulls up R generate new rule → C reviews → verified
→ next L retrieves updated rules through S
Every failure creates new knowledge, every new knowledge reduces similar failure probability. Loop wasn’t designed from day one, but every iteration paved way for it — Git gave version management, MCP gave structured interface, retrieval dimensions gave precise matching, role separation gave trust boundaries, O in-between gave context isolation. All these together, loop runs.
Not considering all possible requirements at system design start, but discovering problems in use, refining abstractions in solving problems. This is harness engineering’s core method — iterate on smallest viable solution, let every iteration solve one real problem, eventually discover loop already underfoot.
Appendix: GEAR Protocol Conformance Requirements
A system claiming GEAR compliance must meet the following conditions:
- Role separation. Production (R), review (C), consumption (L) handled by different agents or processes. Same agent cannot simultaneously execute two roles on same rule.
- Git-backed storage. All
verifiedrules must enter repo via git commit. Consumers read throughgit show HEAD:or equivalent mechanism. - State machine enforcement. Rules can only convert through
pending → staging → verifiedorrejectedpaths, no skipping allowed. - Frontmatter schema. Each rule must contain YAML frontmatter, at minimum have
id,status,scope,category,confidence,risk_level,intent_tags,created_atfields. - Intent-driven retrieval. System must support querying rules by
intent_tags.domainandintent_tags.task_goal. - Rejected rule preservation. Rejected rules preserve original metadata, can be restored through
restoreoperation. - Atomic writes. Rule files written via “write temporary file + rename” method, no partial writes allowed.
Reference Links
- Aristotle project repo: github.com/alexwwang/aristotle
- GEAR protocol spec (the project’s internal
GEAR.mdfile, currently ingit-mcpbranch) - Previous article From Scars to Armor: Harness Engineering in Practice
Aristotle project is open source on GitHub, MIT license. Issues and PRs welcome.