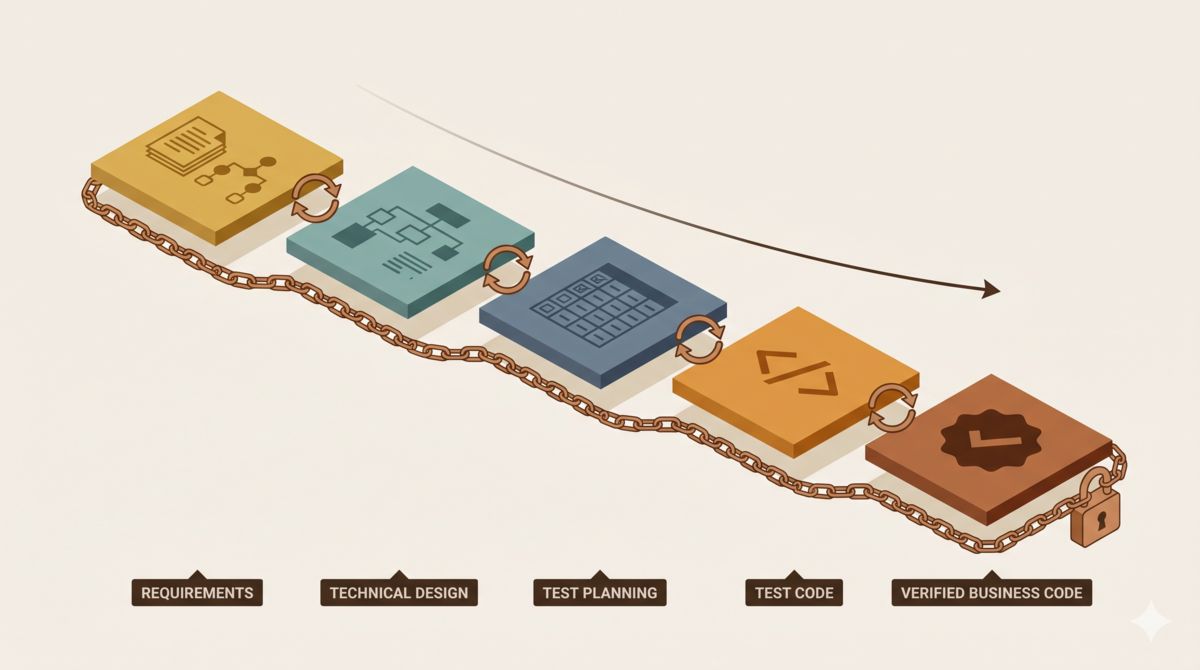
This is article 6 in “Taming AI Coding Agents with TDD.” The first four covered requirements disambiguation with the GEAR protocol, tech spec guardrails, test documents before test code, and convergent review loops. Article 5 upgraded the review layer with procedural justice. This one strings everything together into a single pipeline you can actually run.
The Complete Pipeline
Product Design → Tech Spec → Test Plan → Test Code → Production Code
↑ ↑ ↑ ↑ ↑
Ralph Loop Ralph Loop Ralph Loop Ralph Loop Ralph Loop
Each stage has its own inputs, outputs, and review rules:
- Requirements: Raw feature ideas go in. Testable acceptance criteria come out.
- Design: Acceptance criteria go in. A tech spec backed by API research comes out.
- Test planning: The tech spec goes in. Full-coverage test cases come out.
- Coding: Test cases go in. Passing production code comes out.
- Review: Every stage ends with a Ralph Loop. C/H/M issues must hit zero before moving on. Two consecutive rounds with zero issues at any level (C/H/M/L) triggers early exit[1].
The pipeline runs on priority propagation. During product design, each acceptance criterion gets tagged as either key (must have full test coverage) or peripheral (happy-path is enough). That tag flows downstream. Key ACs require boundary tests and error-path tests. Peripheral ACs only need the main scenario. Decisions made early ripple through every downstream stage.
Why You Cannot Skip Stages
Errors propagate downstream in this pipeline. Ambiguous requirements? The AI will not ask for clarification. It fills in the blanks with its own assumptions. Skipped API research during design? The AI will not stop to verify. It builds an entire architecture on top of APIs that may not exist. Test cases covering only happy-paths? The AI will not flag the gaps. It ships code that passes the narrow tests and calls it done.
Each layer exists to catch what the layer above missed. Skip one, and errors flow straight into production code. Finding them during review costs ten times more to fix.
Stage Checklists
Requirements Stage
- Is every acceptance criterion testable?
- Can each AC produce a binary pass/fail verdict?
- Are there vague subjective adjectives hiding in the text?
- Did you ask at least three clarifying questions?
- Are platform constraints written out explicitly?
Full rules: Requirements disambiguation with the GEAR protocol
Design Stage
- Does every platform API call have a research conclusion behind it?
- Does each research result cite an official documentation source?
- Are there assumptions about features that may not exist?
- Can every component be traced back to an acceptance criterion?
Full rules: Tech spec guardrails
Test Planning Stage
- Does every acceptance criterion have a corresponding test case?
- Are boundary scenarios covered?
- Are error branches tested?
- Are tests anchored to requirements, not to the implementation?
Full rules: Test documents before test code
Coding Stage
- Are external inputs validated for correctness?
- Is there an injection attack risk?
- Do all test cases pass?
Review Stage
- Is the reviewer independent from the creator (different session)?
- Have C/H/M issues hit zero (gate pass condition)?
- Do two consecutive rounds with zero issues at any level (C/H/M/L) trigger early stop?
- Can every change be traced to a requirement?
- Did the reviewer output in three structured categories (defects / suggestions / critique)?
- Did the main agent make ADOPT/MODIFY/REJECT decisions for each item with documented rationale?
- Were rejected C/H/M issues responded to by the reviewer in the next round?
- Was the same rationale not reused for rejection?
- Were issues unresolved after two contested rounds escalated to the user?
Full rules: Convergent review loops, Procedural justice encoded
Aristotle Project Retrospective
Everything in this series came from mistakes I made on the Aristotle project[2]. Three versions. Each failure traced back to the same root cause: a missing process layer.
Version 1: One-Line Requirement, 371 Lines of Context Pollution
The entire requirement was one sentence: “Add a reflection feature to Aristotle.” The AI generated a 371-line SKILL.md and injected it into the main session. All 37 assertions passed. Every single design principle was violated. The reflection task ran inside the main session with no isolation. No human-in-the-loop review.
Root cause: No requirements stage. A one-line requirement left enormous blanks. The AI filled every one with its own assumptions.
Which layer would have caught it: The requirements checklist. “Where does the reflection task execute?” “How are rules stored?” “Who reviews rule quality?” Three clarifying questions would have exposed the design flaws on day one.
Version 2: PRD Written, API Research Skipped
I wrote a structured PRD this time. Requirements were clear. But I skipped API research in the tech spec. The AI designed an entire async architecture around task(run_in_background=true) — an API that does not exist[2]. The reflection module, the notification module, the state manager, all built on that assumption. Integration testing revealed the gap. Full rewrite.
Root cause: No design stage. The PRD locked down “what to build” but not “how to build it.” The AI improvised the “how,” basing an entire system on a nonexistent platform capability.
Which layer would have caught it: The design checklist. “Does every decision involving a platform API have a research conclusion behind it?” That one rule would have stopped the error before a single line of code was written.
Version 3: Full Pipeline Execution
I ran every stage: product design → tech spec (with API research) → test plan → test code → production code. Ralph Loop after each stage.
Manual testing still found 16 bugs. The value of this method is not “zero bugs.” The value is that all 16 bugs were traced to precise root causes. Every bug had a clear fix. Fixes introduced zero new issues. Zero regressions. The AI output became controllable. Problems became solvable. The project shipped[2].
In the most recent feature iteration, the pipeline showed its compounding effect:
| Phase | Deliverable | Ralph Rounds | Extra Review |
|---|---|---|---|
| 1 Product Design | 7 US + 7 AC | R4 pass | — |
| 2 Tech Spec | 309-line design doc | R4 + Council + Oracle ×2 | — |
| 3 Test Plan | 57 tests / 10 classes | R1 pass | — |
| 4 Test Code | 862+ lines of tests (48 initially failing) | R2 + Oracle ×3 | — |
| 5 Production Code | ~220 lines of implementation | R2 pass | Council B+ |
Council and Oracle are independent reviewer roles in the Ralph Loop protocol[1]: Oracle is a single AI reviewer for deep code review and architecture analysis; Council is a multi-model consensus mechanism for decisions needing multiple perspectives.
One trend jumps out: the test plan passed in a single round (R1). The strict process in earlier stages locked down the scope so tightly that downstream stages needed almost no correction. Product design took R4. Tech spec took R4 plus Council review plus two Oracle reviews. That upfront investment paid for itself in every stage after.
When to Use This, When Not To
This method is not a silver bullet. Apply it where it fits.
Good Fit
- AI generates more than 50% of the code. You review and steer. The more code the AI writes, the wider a systematic error can spread.
- Complex business domains with ambiguous requirements. “The system should support high concurrency” — the AI will interpret that as whatever pattern dominates its training data, not ask you for specific targets.
- Tech specs involve uncertain platform APIs. AI knowledge of platform APIs can be outdated or fabricated. Explicit verification is non-negotiable.
- Long-lived production projects. The process documents are the best onboarding material you will ever write.
Not Worth It
- Small, deterministic utilities. A 50-line shell script for log cleanup. Unambiguous requirements. No uncertain APIs.
- Code written entirely by humans. No AI participation means no systematic error propagation. The premise for strict process does not exist.
- Exploratory prototypes. The goal is fast validation of an idea. Process constraints slow that down without adding value.
The core judgment:
The marginal cost of strict process decreases with project complexity. The necessity of strict process increases with AI participation.
The more complex the project, the more rework time the process saves — far exceeding the process overhead. The more code the AI writes, the higher the risk of systematic error propagation. Structured defenses become non-negotiable.
Relationship to Existing Methodologies
This method is not invented from scratch. It is Requirements Traceability Matrix (RTM), Specification by Example (SBE), and Acceptance Test-Driven Development (ATDD), applied to AI-assisted development. I laid out the detailed connections in Article 3.
The biggest difference from traditional TDD:
- Traditional TDD: The developer maps “requirements → tests → code” mentally.
- AI-assisted TDD: That mapping must be written down explicitly. The AI has no “mental understanding.” Only written text functions as a constraint it can follow accurately.
In traditional development, an experienced engineer can judge “these acceptance criteria are too vague” or “this API needs verification” in their head. The AI cannot. It does not question requirements. It does not verify assumptions. Human implicit judgment must become explicit documentation. That is the entire reason the process exists.
Series Conclusion
This series ran six articles. It really comes down to one principle:
AI coding agents are not silver bullets. They are amplifiers. They amplify your engineering capability. They also amplify your engineering debt. Taming them requires stricter process discipline than traditional development.
Four layers, each solving a specific AI problem:
- Requirements: The AI does not ask follow-up questions. Structured clarification questions close the ambiguity gaps.
- Design: The AI designs around APIs that do not exist. Explicit research checklists verify every assumption.
- Testing: The AI writes happy-path tests and skips boundary cases. Test documents anchor to requirements, not to implementation.
- Review: An AI reviewing its own work lacks the independence to catch its own errors. Independent reviewers, a contested issue protocol, and two consecutive rounds with zero issues at any level (C/H/M/L) prove convergence — every step backed by evidence, records, and rule-based constraints.
Process is not a straightjacket. It is the wall that stops the AI from going off the rails.
References
- Ralph Loop review protocol: github.com/alexwwang/tdd-pipeline, ralph-review-loop.md
- Aristotle project source code: github.com/alexwwang/aristotle
Series Articles
- Article 1 — Requirements layer: Why AI-Assisted Development Needs Structured Requirements First
- Article 2 — Design layer: PRD to Tech Spec
- Article 3 — Testing layer: Test Documents Before Test Code
- Article 4 — Review layer: AI Errors Converge, They Don’t Randomize
- Article 5 — Procedural justice layer: Procedural Justice Encoded
The Aristotle project is open source on GitHub under the MIT license. Issues and PRs welcome.