My Ralph Loop review mechanism had a hidden problem.
v0.2’s flow was straightforward: find issues → fix → confirm convergence. In part 4 of this series, I mentioned that if the creator disagrees with the reviewer’s judgment, they can present evidence in the next round for reassessment. But that was one sentence in the rules — not a formal protocol. Nobody was checking whether the review itself was sound. The reviewer might mislabel severity. The main agent might blindly accept bad suggestions.
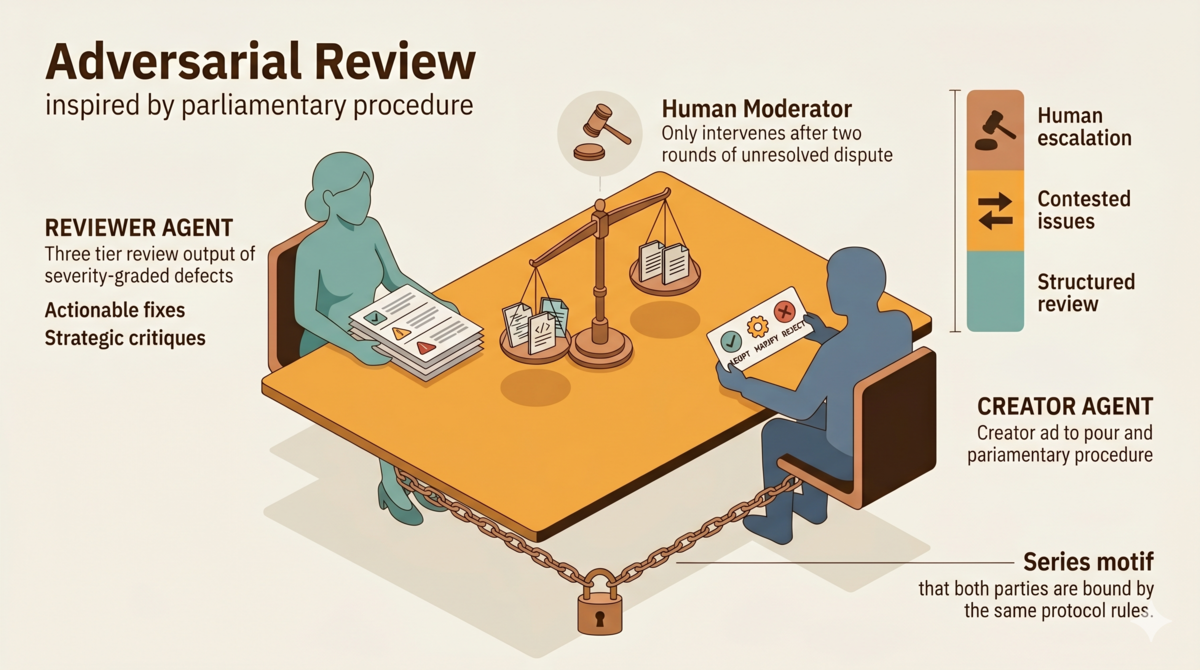
Today I released tdd-pipeline v0.3.0[1]. The design principle for v0.3 fits on a single line: every decision in the review process must be verifiable. Is the issue the reviewer flagged a real issue? Is the fix the main agent accepted a real fix? If the main agent rejects something, does the reason hold up? Every step needs evidence, a record, and rule-based constraints.
v0.3.0 includes other changes too. This article focuses on the three core mechanisms: structured review output, critical scrutiny by the main agent, and the contested issue protocol. All three serve one principle — turning review from a one-way directive into a closed loop where every step is verifiable.
1. Structured Review Output
The reviewer can no longer dump a loose list of issues. Output must fall into three categories:
- Severity-graded defects: C (Critical) / H (High) / M (Major) / L (Low) / I (Info)
- Actionable fix suggestions: Not “consider improving X” — but what to change, how to change it, and why
- Strategic critique: Challenging assumptions, identifying risks, questioning the reasoning behind design decisions
One rule: if no C/H/M defects exist this round, constructive suggestions and critique are optional. No padding the template with forced criticism.
Strategic critique has strict requirements:
- Don’t just flag surface problems — question the reasoning behind each choice
- Identify potential failure modes, edge cases, and blind spots
- Challenge whether the current direction is correct, not just whether it works
- Assess what trade-offs the current approach makes, and whether those trade-offs are acceptable under the project’s constraints
- Back every point with evidence — cite specific content, requirements, or conflicts in prior outputs
2. Critical Scrutiny by the Main Agent
When the main agent receives the review report, it cannot rubber-stamp everything. It must perform structured critical scrutiny in four steps:
- Read the full review report — understand the reasoning behind each suggestion and opinion, not just the surface-level recommendations
- Evaluate against project context — actual constraints (timeline, tech stack, team, architecture); whether suggestions solve real problems or theoretical ones; whether “improvements” introduce new complexity or risk; whether the reviewer’s assumptions about the project are correct
- Decide ADOPT / MODIFY / REJECT for each item
- Record the scrutiny process — every non-trivial decision needs a documented rationale
If the main agent skips steps 1 and 2 and jumps straight to labeling, critical scrutiny degrades into theater — which is exactly the problem this article addresses.
Rejection rules are strict:
- L/I issues and critique: the main agent has free discretion
- C/H/M issues: can only be rejected if “the reviewer’s factual assumptions about the project are wrong” or “the alleged defect is actually documented intended behavior”
These rejection reasons are always invalid:
- “No time” — issues that must be fixed cannot be skipped
- “I disagree with the priority” — severity grading is the reviewer’s call
- “It works in practice” — risks identified by the reviewer must be addressed
3. Contested Issue Protocol
When the main agent rejects a C/H/M issue, the adversarial loop activates:
- The main agent must record its rejection rationale
- The contested issue carries into the next round, and the reviewer must explicitly respond
- The reviewer can accept the rejection (issue removed from statistics) or re-raise with new evidence (issue stays)
- After the reviewer provides new evidence, the main agent cannot reject again using the same rationale — it must ADOPT or MODIFY
- If the main agent rejects again with a different rationale, it counts as a second contested round. After two contested rounds, escalate to the user
Key invariant: a rejected C/H/M issue still counts toward gate statistics until the reviewer (the independent AI subagent) explicitly drops it. You cannot bypass gate conditions by rejecting.
Three roles:
- Main agent (the AI writing code) = opposition: the deliverable’s creator, who can contest the reviewer’s issues
- Reviewer (independent AI subagent) = motion proposer: finds issues, provides evidence, responds to challenges
- User (human) = chair: makes the final call when two contested rounds fail to resolve, and decides at Max Rounds
The reviewer proposes a motion. The main agent is the opposition. The user is the chair — neutrally executing procedure, favoring neither side. The human does not read code line by line. The human chairs — stepping in to decide who is right when two AIs cannot agree on the evidence.
Real-World Parallels
These patterns are not hypothetical. In open-source projects, code review disputes between humans happen every day. The contested issue protocol’s mechanics — raising issues, contesting, evidence confrontation, escalation — play out repeatedly in the real world.
Case: The Prefix Slash Controversy in ky[2]
sindresorhus/ky is a popular HTTP client library for the browser. Its
prefixUrloption rejects paths that start with a slash — passing/usersthrows an error. The maintainer’s reasoning:prefixUrldoes string concatenation, not URL parsing, and developers might mistakenly assume/usersresolves from the origin root — a principled design decision.But nearly every major API documentation displays paths with leading slashes. GitHub REST API, Reddit API, Twilio, Netlify, Twitter/X, Salesforce — all use
/pathformat. Core contributor @sholladay called it “easily the most controversial part of Ky.”How the contested issue protocol would handle this:
Round N: Reviewer raises [H-2]
prefixUrlrejects leading slashes, blocking standard API workflows.Main agent REJECTS: “This is documented intended behavior. prefixUrl does string concatenation, not URL parsing.”
[H-2] becomes a contested issue, carried into Round N+1.
Round N+1: Reviewer investigates. Finds that six major API docs all use leading slashes. The “principled design decision” has a concrete cost: the library breaks standard API workflows. Reviewer re-raises [H-2] with new evidence.
Main agent cannot reject with “documented intended behavior” (same rationale is now invalid). Main agent MODIFIES: “Add slash stripping as a normalization step, preserving prefix semantics.”
Round N+2: Reviewer verifies the modification. Zero new issues.
In reality, this controversy spanned issue #70 (2018), discussion #468, PR #561, and dragged on for years until PR #606 resolved it in v2[2]. It was precisely these prolonged controversies that made me realize: when both sides have reasonable grounds, critical deliberation matters more than who speaks louder. The contested issue protocol distills this thinking into governance rules encoded in protocol — constraining AI agents so that every review decision is tested against evidence, not settled by gut instinct.
Sometimes the parties cannot agree.
Case: The URL Parser Deadlock in requests[3]
psf/requests is the most widely used HTTP library in Python. v2.32.3 introduced a regression:
urlparse()could not handle IPv6 link-local addresses with zone identifiers (e.g.,[fe80::1%eth0]), causing socket errors on machines with multiple network interfaces. Someone submitted PR #6927, proposing a switch tourllib3.parse_url().Maintainer @sigmavirus24 pushed back hard: history showed that every URL parser swap caused regressions. “Every URL parsing change is a minefield.” The PR author was frustrated — the maintainer was not engaging, and the author’s company had SLA pressure. Neither side would yield. The PR was closed.
Through the lens of the contested issue protocol:
Round N: Reviewer raises [H-1] URL parsing regression breaks IPv6 zone ID support.
Main agent REJECTS: “Using stdlib urlparse is correct. urllib3.parse_url has its own compatibility issues.”
Round N+1: Reviewer provides counter-evidence: stdlib urlparse explicitly does not support RFC 6874 zone identifiers, causing socket errors on multi-NIC machines.
Main agent REJECTS again (second contested round): “Historical experience shows that every URL parser replacement has caused regressions.”
→ Escalate to user. The submitted case file includes:
- Original issue description: how the reviewer discovered the regression, what severity was assigned
- Reviewer’s evidence chain: RFC 6874 specification clause, specific socket errors, affected user reports
- Main agent’s rejection rationale: historical regression record, concerns about urllib3.parse_url stability
- Contest history: arguments and evidence from both rounds
- Current status: whether the regression is still affecting users
The user reviews the complete case file and decides: “Conditional accept — use urllib3.parse_url only for URLs containing zone IDs, keep stdlib for everything else.” This is exactly what PR #7065[3] did later.
In reality, the #6927 deadlock wasn’t about the technical problem being unsolvable. These situations made me think: when evidence confrontation has no rules, escalation has no path, and the same rationale can be reused indefinitely, arguments devolve into wars of attrition. The contested issue protocol encodes these hard-won lessons — evidence over authority, no recycled rationales, bounded escalation — into explicit constraints, giving AI agents a clear protocol to follow in similar situations.
From Parliamentary Rules to Review Protocol
Look at the six rules of the contested issue protocol. They were not designed from scratch. Someone solved this same problem 150 years ago[4].
| Robert’s Rules of Order | Contested Issue Protocol |
|---|---|
| Motion-first principle: discuss only after a motion is raised; no motion, no discussion | Reviewer must raise specific issues (with severity); vague opinions are not accepted |
| Clear stance principle: state support or opposition first, then give reasons | Main agent must ADOPT/MODIFY/REJECT; every non-trivial decision requires documented rationale |
| Full debate principle: voting happens only after discussion is fully aired | Contested issues carry into the next round; reviewer must respond to rejection rationale |
| Address the chair principle: participants do not debate each other directly | Main agent and reviewer communicate through reports, not direct dialogue |
| Chair neutrality principle: the chair does not favor either side | User arbitrates, does not participate in technical debate, only decides when two contested rounds fail to resolve |
| Debate limit principle: each person may speak at most twice | Two contested rounds, then escalate to user; no infinite loops |
Beneath the surface correspondence lies a fundamental difference. Robert’s Rules assumes participants have free will and strategic motives. The rules constrain strategic behavior — loophole exploitation, coalition building, stalling tactics. The contested issue protocol’s participants are agents. Agents do not game the system. Here the rules serve a different purpose: making implicit engineering processes explicit and verifiable. One governs behavior. The other governs process flow.
But this difference does not weaken the comparison. It reinforces the core insight: 150 years of Robert’s Rules prove that procedural rules are necessary for any deliberative body, regardless of capability. Human legislators have rationality and professional expertise, yet they still need procedural rules. AI agents have no emotions and do not launch ad hominem attacks — but precisely because they cannot “self-enforce,” rules must be encoded into the protocol itself, rather than relying on social convention.
This is not decoration. It shows that Ralph Loop’s contested issue protocol inherits a 150-year-tested tradition of procedural justice — replacing “please follow the rules” with “the protocol enforces them.” (For those curious about the GAN analogy: the motivations differ fundamentally — GAN is adversarial deception, Ralph Loop is adversarial verification — and so do the dynamics, continuous gradient space vs. discrete rounds. Robert’s Rules is the more accurate frame because it shares the same kernel: constraining adversarial processes through procedural justice.)
Practical Effects
This mechanism addresses two extremes — and both extremes are failures of verifiability.
First extreme: the main agent blindly accepts every reviewer suggestion, even unreasonable ones. Critical scrutiny and the ADOPT/MODIFY/REJECT framework give the main agent a mechanism to say no — but it must provide reasons.
Second extreme: the main agent and reviewer argue endlessly with no resolution. Two contested rounds maximum, then escalation to the user. Quality is protected without burning tokens.
Series Relationship
Part 4 covered Ralph Loop’s convergence mechanism[5], solving “how to confirm the review can end.”
This article covers the v0.3 upgrade, solving “whether every step in the convergence process is reliable.”
Before, we only cared whether issues existed. Now we also care:
- Is the issue a real issue?
- Is the fix a real fix?
- Is the review a real review?
In practice, AI review theater has dropped noticeably. Side effect: sometimes the two AIs argue more earnestly than I write code.
References
- tdd-pipeline v0.3.0: github.com/alexwwang/tdd-pipeline (tag v0.3.0)
- sindresorhus/ky — prefixUrl leading slash controversy: issue #70, discussion #468, PR #561, PR #606
- psf/requests — URL parsing regression and IPv6 zone ID: issue #6735, PR #6927, PR #7065
- Robert, Henry M., Robert’s Rules of Order, 1876.
- Part 4 of this series: AI Errors Converge, They Don’t Randomize
The Aristotle project is open source on GitHub under the MIT license. Issues and PRs welcome.