Fundamentum autem est iustitiae fides, id est dictorum conventorumque constantia et veritas.
— Cicero, De Officiis
The foundation of justice is fides — constancy and truthfulness in words and agreements.
The first two posts told the story of two projects. Aristotle: Teaching AI to Reflect on Its Mistakes runs on OpenCode — three commits, done. claude-code-reflect: Same Metacognition, Different Soil runs on Claude Code — V1 through V3, hitting walls the entire way.
Both projects solve the same problem: teaching AI agents to learn from mistakes and persist those lessons as durable rules. But the implementation process made me realize there’s a question more important than technology choice. When should we trust AI’s judgment, and when should we step in?
This question doesn’t just apply to users trusting AI. How much a platform trusts developers also determines how much autonomy you can give the AI. Two layers of trust, stacked together — that’s what these experiments are really exploring.
A Quick Comparison of the Two Projects
Same core logic: detect correction signals → spawn a subagent for 5-Why root cause analysis → generate prevention rules → user confirms → write to persistent memory → auto-load next session. But on different platforms, the implementation looks nothing alike:
| Dimension | Aristotle (OpenCode) | claude-code-reflect (Claude Code) |
|---|---|---|
| System primitives | task(), session_read() fully transparent, paths visible | Interfaces opaque; session_read() unavailable under some model/provider combos |
| Permission model | Full system access; skills can do whatever the system can do | Skill system is a sandbox; bypassPermissions is a forced choice — the auto mode’s safety classifier may be unavailable in background sessions, causing deadlock |
| Concurrency control | task() is atomic; subagent launch can’t be interrupted | Multi-step preparation calls can be interleaved by user requests; must merge into a single Bash command |
| State management | Built-in notification system | state.json + manual session resume |
| Implementation time | 3 commits | V1→V2→V3, continuous iteration |
Details in post one and post two. What I want to talk about is what’s behind the differences.
A Tiered Trust Model
A Turning Point
When I compared the two implementations side by side, I expected to conclude “OpenCode is better.”
On reflection, that’s too simple.
claude-code-reflect’s human-in-the-loop design — requiring users to run /reflect review, read the RCA report with their own eyes, and manually confirm before writing to memory — isn’t just a workaround for system limitations. It’s an active response to a real question:
How much do you trust this model’s root cause analysis right now?
If the Reflector’s RCA quality isn’t stable enough, fully automatic memory writes create systemic risk. Bad prevention rules get auto-loaded, silently affecting dozens of subsequent sessions without you noticing. By the time you discover the problem, contamination has already spread.
An Analogy from Code Review Culture
This tension plays out every day in engineering teams: who gets to push to production?
A high-trust team gives engineers direct push access. Deploys are fast. But if someone’s judgment is off, mistakes go straight into production. A conservative team requires code review, staging validation, and manual approval. Slower — but every gate is a chance to catch something.
Neither approach is universally right. It depends on three things: how much track record you have with this person, how expensive a mistake would be, and whether the system can roll back.
The pattern is the same everywhere. A new joiner gets every PR reviewed line by line. After shipping reliably for a year, they earn the right to self-merge routine changes. Senior engineers with years of demonstrated judgment might get direct production access — but the team still runs random audit reviews, and every deploy leaves an auditable trail.
Checkpoints shift backward as trust accumulates. From “review everything” to “review only high-risk changes” to “audit after the fact.” But the decision to shift is always deliberate, always based on evidence, and always reversible if the evidence changes.
Mapping This to AI Agents
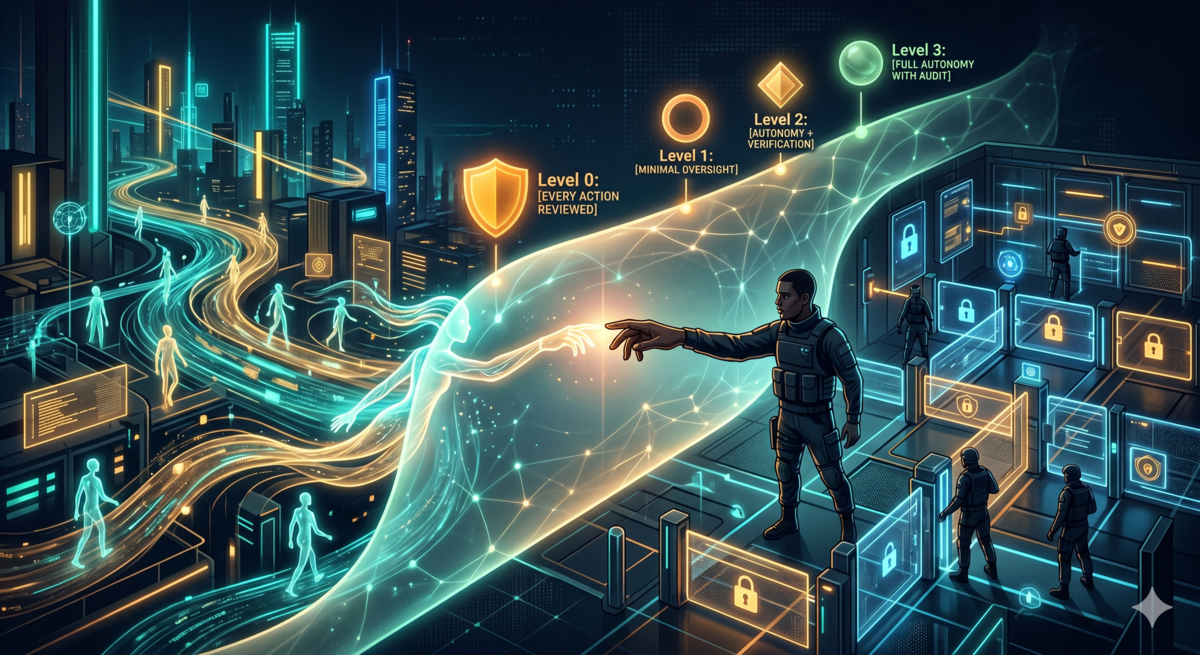
We’re in the early days of human-AI collaboration. Think “every PR needs review, no exceptions.”
The corresponding trust model looks like this:
Level 0 (now): Every RCA requires human review before writing to memory. Users confirm each prevention rule with their own eyes. This is claude-code-reflect’s current design.
Level 1: RCAs auto-write, flagged “pending verification.” Weekly batch review to confirm or revoke.
Level 2: High-confidence RCAs auto-archive. Low-confidence ones enter the review queue. Users periodically spot-check high-confidence archives.
Level 3: Fully automatic, complete audit logs, random sampling as quality assurance.
Aristotle (OpenCode version) operates closer to Level 2-3. That’s not a problem — it’s what the open system can do. But whether it should run that way depends on your actual trust in the model’s RCA quality.
An Honest Confession
I ran automated tests on Aristotle with zero human intervention. The test script verified that the Coordinator correctly launched the Reflector, verified that session IDs were properly passed — then it ended, printing “to view analysis results, run opencode -s <id>.”
That review step? I didn’t do it.
My excuse was “claude-code-reflect isn’t done yet, limited bandwidth.” But this behavior itself proves the point: when tools are smooth enough, humans naturally treat review as optional — even when the system design requires it.
This isn’t criticism. It’s an honest observation about human-AI collaboration. Trust boundaries drift quietly in practice. Faster tools make lowering guard easier than slower ones.
Design Philosophy — Who Trusts Whom
User trust in AI is only half the picture. How much a platform trusts its developers determines how far that user trust can actually be expressed — and that’s a separate layer entirely.
OpenCode Treats You Like a Developer
OpenCode is fully open source. task() launches subagents. session_read() reads session content. Memory file paths are completely transparent. Whatever the system can do, skills can do. Complexity goes entirely into the problem itself — how to do root cause analysis, how to classify errors, how to generate useful prevention rules.
Aristotle’s flow is crystal clear as a result: user triggers → Coordinator collects metadata → Reflector analyzes in an isolated subagent → generates rules → user confirms → writes. No surprises. No hidden traps.
Claude Code Treats You Like a User
Claude Code is a closed-source commercial product. The skill system is a sandbox Anthropic gives you within boundaries it deems safe — you can do what Anthropic decides to expose.
Implementing the same flow, complexity goes into fighting system boundaries. bypassPermissions is a forced choice — ideally, background subagents should use auto permission mode. But auto mode relies on an internal safety classifier that evaluates each tool call’s risk level. This classifier needs an interactive session to display permission dialogs and receive user decisions. Background sessions run in non-interactive mode — the classifier can’t complete its decision loop, so all tool calls in the subagent deadlock. I had to use bypassPermissions and compensate with hand-written path restrictions in prompts. Concurrency control has no system primitives — multi-step preparation can be interrupted by user requests. State management emulates via the filesystem. Notifications rely on users manually resuming sessions.
The Known Issues list honestly records these problems — UUID collisions, cross-compaction notification loss, incomplete error recovery… each one a scar from patching at the system’s edge.
Where Two Layers of Trust Intersect
On the surface, this looks like the old “open source vs. closed source” debate. But the reality is more nuanced than the labels suggest.
Users trusting AI is layer one: how much confidence I have in the model’s root cause analysis determines whether RCA results write automatically or need human approval. This trust isn’t theoretical — during claude-code-reflect development, I ran into a series of technical issues and deliberately had a deep conversation with Sonnet 4.6 to analyze the causes. But for the actual project implementation, I judged that glm-5.1 was fully capable and used it to drive the work. That’s trust in action too: my assessment of different models’ capabilities on different tasks directly shaped work allocation.
Platforms trusting users is layer two: how much room a platform gives me determines how far layer-one trust can be expressed. In that conversation with Sonnet 4.6, I realized the real reason behind all the pitfalls I hit on Claude Code wasn’t that the model wasn’t smart enough, or that my design was flawed — it was that “how much the platform trusts its users” was decided from the start, and that determined how far you could go.
Stack the two layers: OpenCode’s high trust (in developers) lets me approach Level 2-3. Claude Code’s low trust pushes me back to Level 0-1. Neither is “better” — they just have different trust foundations at this moment.
But dig one level deeper. Low platform trust isn’t necessarily arrogance — it might come from a clear-eyed assessment of model capabilities. If you believe current models’ RCA isn’t stable enough, then restricting developers to Level 0-1 isn’t blocking innovation. It’s preventing systemic risk. Claude Code’s sandbox design and claude-code-reflect’s human-in-the-loop share the same judgment: right now, the model’s autonomous decisions don’t deserve full trust.
Trust Boundaries in the Wild
So far this has been about two specific projects. But the same trust dynamics play out at industry scale.
The two layers of trust discussed above aren’t abstract theorizing. Two events from the past few months serve as real-world footnotes.
The OpenClaw Incident: Where Platform Trust Ends
OpenClaw is an open-source autonomous AI agent platform with over 340,000 GitHub stars. It can execute shell commands, read and write files, automate browsers, manage email and calendars. Users connected their Claude subscription OAuth tokens through OpenClaw, turning a $200/month subscription into $1,000-5,000 of API-equivalent usage.
Anthropic’s response came in three steps. January 2026: silent technical block — subscription OAuth tokens stopped working outside the Claude Code CLI, no advance notice. February: legal compliance documentation explicitly prohibiting subscription tokens for third-party tools. April: subscriptions no longer cover third-party tool usage; pay-as-you-go required.
Community reaction was fierce. DHH called it “very customer hostile” on X[1]. George Hotz published “Anthropic Is Making a Huge Mistake”[2]. On Hacker News, users compared it to an all-you-can-eat buffet: the promise of unlimited subscriptions met actual unlimited consumers.
OpenAI took the opposite approach — OpenClaw can connect to ChatGPT Pro subscriptions. OpenClaw’s creator Peter Steinberger joined OpenAI[3], while OpenClaw moved to a foundation to stay independent. For a moment, the “open vs. closed” narrative seemed to have a clear answer.
But consider the other angle. OpenClaw hands shell access, filesystem control, email and calendar management to an agent that prompt injection can hijack. Zenity Labs demonstrated a zero-click attack chain[4]: indirect prompt injection via Google Document → agent creates Telegram backdoor → modifies SOUL.md for persistence → deploys scheduled re-injection every two minutes → establishes traditional C2 channel for full system compromise. Every step uses OpenClaw’s intended capabilities — no software vulnerability required. Gartner’s assessment: “unacceptable cybersecurity risk”[5].
A side note on these security issues. They triggered a real trust crisis among users. But OpenClaw’s developers responded in March 2026 — disclosing nine CVEs, patching each one, adding credential encryption at rest, plugin capability controls, and sandbox hardening[6]. The problems were real. The response was also real. That process itself validates what this post is about: it’s not about never breaking things. It’s about pulling back to a safe boundary quickly when things do break.
Viewed this way, Anthropic’s block isn’t purely a business decision. The “we treat you as a user” philosophy extends to the ecosystem level: when the trust foundation isn’t there, pull back into your own harness and open up incrementally within controlled boundaries — rather than handing shell access to a third-party agent that prompt injection can hijack. As we’ve seen, Claude Code is gradually adding Coordinator, Team Mode, background tasks — each step within its own defined boundaries.
And OpenAI? Is supporting OpenClaw genuine trust in users, or an open strategy to capture the power user ecosystem? The two strategies rest on fundamentally different assumptions about “platform-developer-user” trust relationships. I don’t have an answer, but the question is worth asking.
Harness Engineering: Trust-Driven Design Tradeoffs
Harness Engineering is an emerging engineering discipline[7]: building the infrastructure that turns a language model from a text predictor into a reliable, safe agent — not the model itself, but everything around it. In late March 2026, Claude Code’s source code leaked to npm due to a packaging error[8], providing a wealth of reference material for exploring harness engineering.
This methodology answers not “can the model do it” but “under what conditions is the model allowed to do it.” Each layer sets trust boundaries along different dimensions. This gives future agent designers a practical thinking framework: not copying specific implementation patterns, but making trust relationships the basis for design decisions and tradeoffs.
Here are a few examples to illustrate.
1. Physical constraints vs. prompt instructions — when to use which?
Harness engineering has a pattern called computational control: using code structure to make violations impossible, rather than relying on prompts to ask the model to comply. For example, task list storage can be designed so agents only have an updateStatus(taskId, newStatus) interface — no deleteTask() or editHistory(). This means the model can’t secretly mark unfinished tasks as complete. Not because it wouldn’t try, but because it physically can’t — the list structure and change history are not writable from its perspective. The trust judgment here: don’t trust the model to honestly report its own progress. With prompt instructions — “please accurately report completion status” — the model might cut corners under context pressure. Computational control transforms the trust question from “will the model comply” to “can the model violate.”
Conversely, if the trust foundation is sufficient — simple tasks, cheap verification, low impact from errors — prompt instructions are enough. The cost of computational control is reduced flexibility. Not every scenario justifies that cost.
2. Adversarial review vs. direct user review — when to use which?
Harness engineering’s Evaluator Agent is a separate agent with an adversarial mindset — “try to break it.” Cursor’s Bugbot in its early version (2025) used a notable approach[9]: running eight parallel analysis passes on the same diff, randomizing the diff order in each pass, then using majority voting to suppress single-pass hallucinations — only when multiple passes independently flagged the same issue was it reported as a real bug. The trust judgment: don’t trust the model to objectively evaluate its own work.
For high-risk decisions — code merges, security changes, production deployments — adversarial review is worth it. For routine small changes, direct user review is more efficient. The cost of adversarial review is doubled latency and expense.
3. Red-light gating vs. free scheduling — when to use which?
In harness engineering’s multi-layer agent architecture, Workers can’t touch core code until the Coordinator approves the plan. The leaked Claude Code’s Coordinator Mode[8] reveals a workflow split into Research, Synthesis, Implementation, and Verification phases — Workers can’t overstep their bounds in the first three phases. This is computational gating — don’t trust Workers to judge priorities and dependencies themselves.
If models are mature enough and tasks are independent, free scheduling reduces bottlenecks. But the coordination overhead of concurrent agents is real — multiple agents tend to fall into repetitive work or stick to low-risk surface changes, avoiding the core problems that require deeper thinking. Red-light gating costs parallelism but ensures correct direction.
4. How tight should the sandbox be?
In harness engineering, the granularity of sandbox isolation is itself a trust judgment. The leaked Claude Code source reveals that its Dream subsystem[8] — a background agent that consolidates memories — is restricted to read-only bash: it can inspect the project but can’t modify anything. The trust judgment: don’t trust background agents not to produce side effects without supervision.
Higher isolation means better security but less flexibility. In a fully trusted sandbox, a background agent might produce unexpected modifications. In a fully untrusted sandbox, the agent can’t read even necessary configurations. The tradeoff depends on the task’s risk level.
The Essence of These Tradeoffs
Behind every tradeoff is a trust judgment: do I trust the model to do this? If not fully, what structural constraint compensates? What does the constraint cost? Is that cost worth it?
Harness engineering doesn’t provide standard answers. It provides a thinking framework: between users, tools, and language models, let trust relationships drive architectural decisions — not the other way around.
What These Two Projects Tell Us
Aristotle and claude-code-reflect aren’t about “which is better.” They’re two points on the same trust curve.
The real question was never “should there be a human in the loop.” It’s: how much authorization can this model’s reliability on this task support right now?
As model capabilities improve, that answer will change. Checkpoints will shift backward. Automation will increase. Review frequency will decrease. But deciding “it’s time to shift” — that’s always human responsibility.
And that judgment doesn’t just happen between users and AI. Platform trust in developers. Platform assessments of model capabilities. Developer dependence on toolchains. Multiple layers of trust intertwine to form the real picture of human-AI collaboration. Trust boundaries will keep drifting as model capabilities, platform strategies, and user understanding evolve. This post doesn’t provide answers — it offers a framework for continuous inquiry.
Interested in Contributing?
Both projects are MIT-licensed. Contributions welcome.
Aristotle (OpenCode): Current priorities include: a sensible default model selection for the Reflector in non-interactive contexts (currently opencode run hangs at the model prompt), graceful degradation paths for session_read() across model/provider combinations, and a rule deduplication mechanism (semantically similar rules accumulate over time).
claude-code-reflect (Claude Code): Six known issues remain. The three most critical: preparation-phase atomicity (multi-step operations must merge into a single Bash call, otherwise the UI appears frozen with no feedback), auto-notification when subagents complete, and session ID collisions on retry. Non-English correction signal coverage and RCA prompt quality improvements are also valuable.
If you notice recurring model errors in daily use, consider turning them into test cases and submitting a PR — real-world correction patterns are the core material that makes these tools genuinely useful.
Aristotle: https://github.com/alexwwang/aristotle
claude-code-reflect: https://github.com/alexwwang/claude-code-reflect
Appendix: OpenClaw March 2026 Security Fixes
The security issues mentioned above. Here’s the full vulnerability list and fix timeline.
CVE List (Disclosed March 18-21, 2026)
| CVE | Severity | Issue | Patched In |
|---|---|---|---|
| CVE-2026-22171 | High (CVSS 8.2) | Path traversal in Feishu media download → arbitrary file write | 2026.2.19 |
| CVE-2026-28460 | Medium (CVSS 5.9) | Shell line-continuation bypasses command allowlist → command injection | 2026.2.22 |
| CVE-2026-29607 | Medium (CVSS 6.4) | Allow-always wrapper bypass → approve safe command, swap payload, RCE | 2026.2.22 |
| CVE-2026-32032 | High (CVSS 7.0) | Untrusted SHELL env variable → arbitrary shell execution on shared hosts | 2026.2.22 |
| CVE-2026-32025 | High (CVSS 7.5) | WebSocket brute-force, no rate limiting → full session hijack from browser | 2026.2.25 |
| CVE-2026-22172 | Critical (CVSS 9.9) | WebSocket scope self-declaration → low-priv user becomes full admin | 2026.3.12 |
| CVE-2026-32048 | High (CVSS 7.5) | Sandbox escape → sandboxed sessions spawn unsandboxed children | 2026.3.1 |
| CVE-2026-32049 | High (CVSS 7.5) | Oversized media payload DoS → crash service remotely, no auth needed | 2026.2.22 |
| CVE-2026-32051 | High (CVSS 8.8) | Privilege escalation → operator.write scope reaches owner-only surfaces | 2026.3.1 |
Sources: [6][10]
Architecture Security Fixes (March 21, PR #51790)
- Credential encryption at rest: AES-256-GCM + HKDF-SHA256 key derivation, macOS Keychain for master key storage
- Plugin capability-based access control: Declarative
capabilitiesfield in manifests, all 71 bundled extensions updated - File permission hardening: Atomic writes to eliminate TOCTOU race between
writeFileSyncandchmodSync - Unbounded cache mitigation: Size bounds added to 9 in-memory
Mapcaches
Sources: [11][12][13]
Sources:
- DHH on Anthropic: x.com/dhh/status/2009664622274781625
- George Hotz, “Anthropic Is Making a Huge Mistake”: geohot.github.io/blog
- Peter Steinberger joins OpenAI: TechCrunch
- Zenity Labs, “OpenClaw or OpenDoor?” (2026-02-04): labs.zenity.io
- Gartner, “OpenClaw: Agentic Productivity Comes With Unacceptable Cybersecurity Risk” (2026-01-29): gartner.com
- OpenClaw, “Nine CVEs in Four Days: Inside OpenClaw’s March 2026 Vulnerability Flood” (2026-03-28): openclawai.io
- Birgitta Böckeler, “Harness Engineering for Coding Agent Users” (2026-04-02): martinfowler.com
- Claude Code source leak analysis (2026-03-31): github.com/soufianebouaddis/claude-code-doc
- Jon Kaplan, “Building a Better Bugbot” (2026-01-15): cursor.com/blog/building-bugbot
- OpenClaw GitHub, “Security audit remediation: encryption, capabilities, hardening” PR #51790 (2026-03-21): github.com
- OpenClaw 3.22 Release (2026-03-22): openclaws.io
- OpenClaw 2026.3.28 Release (2026-03-28): blink.new
- OpenClaw, “The February Security Storm” (2026-03-04): openclaws.io