
级联检索,借信息检索领域 15 年前的方法治审查 agent 的病
系列:用经典理论指导 Agent 实践(第一篇) TL;DR: 设计审查的 agent 既要找得全又要找得准,一个 agent 难以两全。借鉴信息检索 15 年前的级联检索思路,拆成两个 agent——一个只管找全(Recall Pass),一个只管找准(Precision Pass)。设计方案的缺陷更早暴露,开发阶段返工的风险降低了。 ...
系列:用经典理论指导 Agent 实践(第一篇) TL;DR: 设计审查的 agent 既要找得全又要找得准,一个 agent 难以两全。借鉴信息检索 15 年前的级联检索思路,拆成两个 agent——一个只管找全(Recall Pass),一个只管找准(Precision Pass)。设计方案的缺陷更早暴露,开发阶段返工的风险降低了。 ...
系列:破而后立的 TDD 流程迭代(第三篇) 第一篇:失之东隅,收之桑榆的实验 · 第二篇:以尺度尺,用方法改进方法 TL;DR: 阶段六已经在集成层做诊断——逐个 bug 追问根因。它不做的事是跨缺陷的模式扫描、组件缝隙检查、执行顺序分析。这些事归阶段七。小系统里阶段七多拦几个 bug;系统大了,同样是这三件事,产出变成建测试基础设施、硬化 CI 规则、驱动架构演进。阶段七不做架构决策,但它提供架构决策最稀缺的输入——基于证据的问题定位。 ...

系列:破而后立的 TDD 流程迭代(第二篇) 上一篇:失之东隅,收之桑榆的实验 TL;DR: TDD Pipeline 自己教的是"给原则不给步骤",但自己却长成了步骤驱动的工具。把阶段一到阶段五的操作步骤删掉,只保留原则、风险提示和反面例子。模型自己推导出了被删掉的步骤,输出质量不降。原因:阶段一到阶段五是创作阶段,需要发散空间,去掉固定轨道反而更好。同样的策略用在阶段六上失败了——下一篇讲为什么。 ...

系列:破而后立的 TDD 流程迭代(第一篇) TL;DR: 把 TDD Pipeline 的阶段六(预发布测试)从"步骤驱动"精炼为"原则驱动",预设目标没达到——精炼版在单个 bug 的追问深度、证据链完整度上都比原版差。但对比两组输出发现了维度差异:精炼版在组件缝隙检查、跨 bug 模式扫描上比原版强。这些差异指向一个判断——阶段六不需要被精炼,而是缺了一个阶段六没有定义的任务,后来被定义为阶段七。 ...

TL;DR: 展示 Why Articulation 模板升级前后的对比,以及三条可迁移建议:给原则不给示例、关键步骤用强制语气、相信模型的自我组织能力。实验局限也已说明。 前两篇回顾 第一篇从 Anthropic 的对齐研究出发:教模型"为什么"比只教它"正确答案",误对齐率从 22% 降到 3%(约 7 倍),而且用 1/28 的数据量就能达到同等效果[1]。我把这个发现移植到 prompt 设计里,造出了 Why Articulation 模板——要求 AI 动手前先说清目的、风险和方案。 ...

TL;DR: 四变量 A/B 实验测试 Why Articulation 的结构、语气、位置和示例。正面示例反而有害——模型倾向模仿而非独立思考。开放式 prompt 方向性提升质量,同时节省 33% token。 ...

TL;DR: Anthropic 的对齐研究表明,教模型"为什么"比教"做什么"更有效——误对齐率从 22% 降到 3%。本文拆解四组实验,提炼出三个可迁移的 prompt 设计教训。 ...

TL;DR: 一个使用 AI 的人会经历怎样的成长?这篇文章把从"第一次打开对话框"到"以 AI 的方式思考"的旅程分为五个阶段——初触者、使用者、工程师、架构师、原住民。每个阶段的本质不是学会更多工具,而是思维方式发生一次跃迁:从被动接受输出,到主动设计输入,再到编排多 Agent 协作,最终重塑自己的认知框架。文末链接到交互式路径图,可以展开探索每个阶段的完整内容。 ...
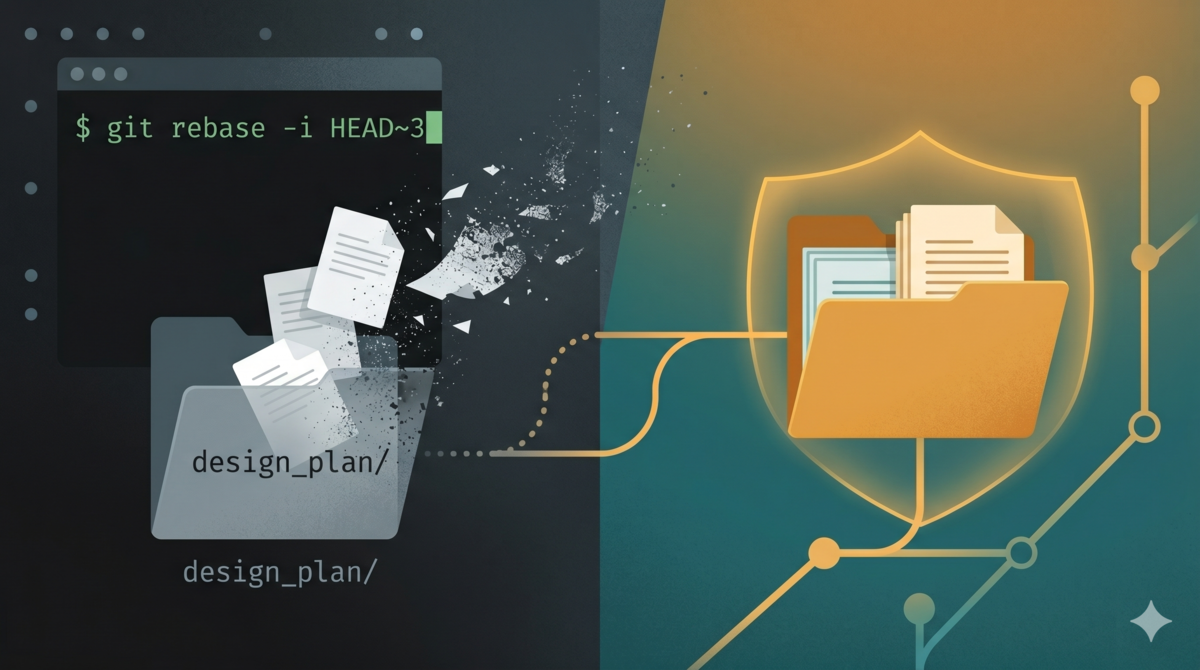
TL;DR: git rebase / checkout 会静默删除 .gitignore 中的未追踪文件,且无法恢复;git stash -u 不会 stash git-ignored 的文件。解决方案是用 git worktree 创建 local-assets 分支,把设计文档放在被 git 追踪的安全空间里。三条命令搞定日常:dp-save.sh 保存、--prune 清理、--restore 恢复。多个项目实测引入后文档丢失归零。完整脚本见 alexwwang/design-doc-worktree。 ...

TL;DR: Aristotle v1.1 发布前发现 18 个 bug,单元测试只拦住 4 个(22%)。剩下 14 个都在集成层——组件接线、配置传递、进程启动的交叉点。对它们做 root cause analysis 后归纳出六种模式:路径/环境不一致(5 个)、注册遗漏(3 个)、启动阻塞(2 个)、静默失败(2 个)、测试-生产路径差异(2 个)、集成拼接错误(4 个)。根因不是问题变难了,是 AI 绕过了手写代码时靠经验建立的防线——实现和审查的节奏脱钩、代码外观误导了质量判断、集成环节从显式动作变成了隐式假设。文末附八维度集成检查清单和 16 种 bug 类型的路线图。 ...